







隐马尔可夫模型 Hidden Markov Model
本文参考的视频链接
首先要知道什么式序列(Series),什么是集合(Set)
时间序列模型 Discrete Dynamic Model: Hidden Markov Model
P ( X t ∣ X t − 1 , X t − 2 … . X 1 ) = P ( X t ∣ X t − 1 ) (1) \begin{aligned} & P\left(X_{t} | X_{t-1}, X_{t-2} \ldots . X_{1}\right) \\ =& P\left(X_{t} \mid X_{t-1}\right)\tag{1} \end{aligned} =P(Xt∣Xt−1,Xt−2….X1)P(Xt∣Xt−1)(1)
1. 马尔可夫过程简介
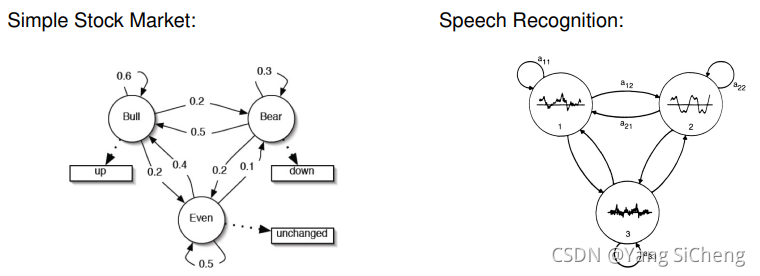
在我们知道一系列隐状态之后,我们的观测都是独立的
股市中的箭头的数值指的就是式(1)的概率值
为了所有的符号一致,现在把所有的隐状态记为q:
- p ( q t ∣ q t − 1 ) p(q_t|q_{t-1}) p(qt∣qt−1)→transition probability(转移概率,在HMM里面,一定是离散的)
- p ( y t ∣ q t ) p(y_t|q_t) p(yt∣qt)→emission/measurement probability(发射概率,并不一定是离散的)
这两个概率决定了HMM模型
在语音里面的应用如下所示(音标是隐变量)

HMM图模型

知道隐状态之后,观测都是独立的!

2. {A、B、 π \pi π}
在HMM里面,transition probability用一个矩阵(k×k)来表示:

- 我们用一个 A k × k A_{k×k} Ak×k的矩阵代表 p ( q t ∣ q t − 1 ) p(q_t|q_{t-1}) p(qt∣qt−1)
- 假设 p ( y t ∣ q t ) p(y_t|q_t) p(yt∣qt)是离散的,我们用一个 B k × L B_{k×L} Bk×L来表示

现在思考,是否只有
λ
=
{
A
,
B
}
\lambda=\{A,B\}
λ={A,B}便可以描述HMM模型
所以请思考,怎么计算股票观测到 P ( y 1 = u p , y 2 = u p , y 3 = d o w n ) P(y_1=up,y_2=up,y_3=down) P(y1=up,y2=up,y3=down)的概率?
我们知道:
P
(
x
)
=
∫
y
P
(
x
,
y
)
d
y
P(x)=\int_{y} P(x, y) d y
P(x)=∫yP(x,y)dy
所以原概率可以转化为:
P
(
y
1
,
y
2
,
y
3
)
=
∑
q
1
=
1
k
∑
q
2
=
1
k
∑
q
3
=
1
k
p
(
y
1
,
y
2
,
y
3
,
q
1
,
q
2
,
q
3
)
=
∑
q
1
=
1
k
∑
q
2
=
1
k
∑
q
3
=
1
k
p
(
y
3
∣
y
1
,
y
2
,
q
1
,
q
2
,
q
3
)
×
p
(
y
1
,
y
2
,
q
1
,
q
2
,
q
3
)
=
∑
q
1
=
1
k
∑
q
2
=
1
k
∑
q
3
=
1
k
p
(
y
3
∣
q
3
)
×
p
(
y
1
,
y
2
,
q
1
,
q
2
,
q
3
)
=
∑
q
1
=
1
k
∑
q
2
=
1
k
∑
q
3
=
1
k
p
(
y
3
∣
q
3
)
×
p
(
q
3
∣
y
1
,
y
2
,
q
1
,
q
2
)
×
(
y
1
,
y
2
,
q
1
,
q
2
)
=
∑
q
1
=
1
k
∑
q
2
=
1
k
∑
q
3
=
1
k
p
(
y
3
∣
q
3
)
×
p
(
q
3
∣
q
2
)
×
(
y
1
,
y
2
,
q
1
,
q
2
)
=
∑
q
1
=
1
k
∑
q
2
=
1
k
∑
q
3
=
1
k
p
(
y
3
∣
q
3
)
×
p
(
q
3
∣
q
2
)
×
p
(
y
2
∣
q
2
)
×
p
(
q
2
∣
q
1
)
×
p
(
y
1
∣
q
1
)
×
p
(
q
1
)
\begin{aligned} P\left(y_{1}, y_{2}, y_{3}\right)&=\sum_{q_1=1}^{k} \sum_{q_2=1}^{k} \sum_{q_{3}=1}^{k} p\left(y_{1}, y_{2}, y_{3}, q_{1}, q_{2}, q_{3}\right)\\ &=\sum_{q_1=1}^{k} \sum_{q_2=1}^{k} \sum_{q_{3}=1}^{k}p(y_3|y_{1}, y_{2}, q_{1}, q_{2}, q_{3})\times p(y_{1}, y_{2}, q_{1}, q_{2}, q_{3})\\ &=\sum_{q_1=1}^{k} \sum_{q_2=1}^{k} \sum_{q_{3}=1}^{k}p(y_3|q_{3})\times p(y_{1}, y_{2}, q_{1}, q_{2}, q_{3})\\ &=\sum_{q_1=1}^{k} \sum_{q_2=1}^{k} \sum_{q_{3}=1}^{k}p(y_3|q_{3})\times p(q_{3}|y_{1}, y_{2}, q_{1}, q_{2})\times ({y_{1}, y_{2}, q_{1}, q_{2}})\\ &=\sum_{q_1=1}^{k} \sum_{q_2=1}^{k} \sum_{q_{3}=1}^{k}p(y_3|q_{3})\times p(q_{3}|q_{2})\times ({y_{1}, y_{2}, q_{1}, q_{2}})\\ &=\sum_{q_1=1}^{k} \sum_{q_2=1}^{k} \sum_{q_{3}=1}^{k}p(y_3|q_{3})\times p(q_{3}|q_{2})\times p(y_2|q_{2})\times p(q_{2}|q_{1})\times p(y_1|q_{1})\times p(q_{1}) \end{aligned}
P(y1,y2,y3)=q1=1∑kq2=1∑kq3=1∑kp(y1,y2,y3,q1,q2,q3)=q1=1∑kq2=1∑kq3=1∑kp(y3∣y1,y2,q1,q2,q3)×p(y1,y2,q1,q2,q3)=q1=1∑kq2=1∑kq3=1∑kp(y3∣q3)×p(y1,y2,q1,q2,q3)=q1=1∑kq2=1∑kq3=1∑kp(y3∣q3)×p(q3∣y1,y2,q1,q2)×(y1,y2,q1,q2)=q1=1∑kq2=1∑kq3=1∑kp(y3∣q3)×p(q3∣q2)×(y1,y2,q1,q2)=q1=1∑kq2=1∑kq3=1∑kp(y3∣q3)×p(q3∣q2)×p(y2∣q2)×p(q2∣q1)×p(y1∣q1)×p(q1)
所以现在还差了一个
p
(
q
1
)
p(q_1)
p(q1),所以现在需要一个初始状态的概率,所以我们还需要一个参数
π
\pi
π

HMM三个主要的操作如下:
Evaluate
p
(
Y
∣
λ
)
λ
MLE
=
arg
max
λ
p
(
Y
∣
λ
)
arg
max
Q
p
(
Y
∣
Q
,
λ
)
\begin{aligned} &\text { Evaluate } p(Y \mid \lambda) \\ &\lambda_{\text {MLE }}=\underset{\lambda}{\arg \max } p(Y \mid \lambda) \\ &\underset{Q}{\arg \max } p(Y \mid Q, \lambda) \end{aligned}
Evaluate p(Y∣λ)λMLE =λargmaxp(Y∣λ)Qargmaxp(Y∣Q,λ)
下面首先讨论Evaluation
如何应用HMM,以语音识别为例,例如找50个人说同样的cat或者dog…
λ
c
a
t
=
arg max
λ
l
o
g
P
(
y
(
1
)
(
1
)
,
y
(
2
)
(
2
)
.
.
.
∣
λ
)
\lambda_{cat} = \argmax_{\lambda} logP(y_{(1)}^{(1)},y_{(2)}^{(2)}...|\lambda)
λcat=λargmaxlogP(y(1)(1),y(2)(2)...∣λ)
之后我们想要干嘛?语音识别,有个人说了一段从来没有听说过的录音,现在可以去评估说哪个单词的概率最高,即Evaluate
下面来看Evaluation,即有了
λ
\lambda
λ来估计观测值:
P
(
y
1
.
.
.
y
T
∣
λ
)
P\left(y_{1} ... y_{T} \mid \lambda\right)
P(y1...yT∣λ)
= ∑ q 1 = 1 k ∑ q 2 = 1 k … ∑ q T = 1 k P ( y 1 … . y T , q 1 … q T ) ⏟ =\sum_{q_{1}=1}^{k} \sum_{q_{2}=1}^{k} \ldots \sum_{q_{T}=1}^{k} \underbrace{P\left(y_{1} \ldots . y_{T}, q_{1} \ldots q_{T}\right)} =q1=1∑kq2=1∑k…qT=1∑k P(y1….yT,q1…qT)
通常计算的方法如下所示:通常计算的方法如下所示:
p
(
Y
∣
λ
)
=
∑
Q
[
p
(
Y
,
Q
∣
λ
)
]
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
[
p
(
y
1
,
…
,
y
T
,
q
1
,
…
q
T
∣
λ
)
]
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
[
p
(
y
1
,
…
,
y
T
,
q
0
,
q
1
,
…
q
T
∣
λ
)
]
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
p
(
q
1
)
p
(
y
1
∣
q
1
)
p
(
q
2
∣
q
1
)
…
p
(
q
t
∣
q
t
−
1
)
p
(
y
t
∣
q
t
)
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
π
(
q
1
)
∏
t
=
2
T
a
q
t
−
1
,
q
t
∏
t
=
1
T
b
q
t
(
y
t
)
\begin{aligned} p(Y \mid \lambda) &=\sum_{Q}[p(Y, Q \mid \lambda)]=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k}\left[p\left(y_{1}, \ldots, y_{T}, q_{1}, \ldots q_{T} \mid \lambda\right)\right] \\ &=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k}\left[p\left(y_{1}, \ldots, y_{T}, q_{0}, q_{1}, \ldots q_{T} \mid \lambda\right)\right] \\ &=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k} p\left(q_{1}\right) p\left(y_{1} \mid q_{1}\right) p\left(q_{2} \mid q_{1}\right) \ldots p\left(q_{t} \mid q_{t-1}\right) p\left(y_{t} \mid q_{t}\right) \\ &=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k} \pi\left(q_{1}\right) \prod_{t=2}^{T} a_{q_{t-1}, q_{t}} \prod_{t=1}^{T}b_{q_{t}}\left(y_{t}\right) \end{aligned}
p(Y∣λ)=Q∑[p(Y,Q∣λ)]=q1=1∑k…,qT=1∑k[p(y1,…,yT,q1,…qT∣λ)]=q1=1∑k…,qT=1∑k[p(y1,…,yT,q0,q1,…qT∣λ)]=q1=1∑k…,qT=1∑kp(q1)p(y1∣q1)p(q2∣q1)…p(qt∣qt−1)p(yt∣qt)=q1=1∑k…,qT=1∑kπ(q1)t=2∏Taqt−1,qtt=1∏Tbqt(yt)
其中,定义转移概率为转移概率矩阵的第 i i i行,第 j j j列: p ( q t = j ∣ q t − 1 = i ) ≡ a i , j p\left(q_{t}=j \mid q_{t-1}=i\right) \equiv a_{i, j} p(qt=j∣qt−1=i)≡ai,j,同时定义测量概率为: p ( y t ∣ q t = j ) ≡ b j ( y t ) p\left(y_{t} \mid q_{t}=j\right) \equiv b_{j}\left(y_{t}\right) p(yt∣qt=j)≡bj(yt)。注意到这里有 k T k^T kT个可能的 Q Q Q值,所以我们需要更简单的方法。
3. 引入 α , β \alpha,\beta α,β便于Evaluate
存在的问题,运算量太大了!所以这里假设一个
α
\alpha
α和
β
\beta
β

联合概率:
α
i
(
t
)
=
p
(
y
1
,
y
2
,
…
y
t
,
q
t
=
i
)
\alpha_{i}(t)=p\left(y_{1}, y_{2}, \ldots y_{t}, q_{t}=i \right)
αi(t)=p(y1,y2,…yt,qt=i)
按照以上概率:
α
i
(
1
)
=
p
(
y
1
,
q
1
=
i
)
=
p
(
y
1
∣
q
1
=
i
)
×
p
(
q
1
=
i
)
=
b
i
(
y
1
)
⋅
π
(
q
1
)
\alpha_{i}(1)=p\left(y_{1}, q_{1}=i \right)=p(y_1|q_{1}=i)\times p(q_{1}=i)=b_i(y_1) \cdot \pi(q_1)
αi(1)=p(y1,q1=i)=p(y1∣q1=i)×p(q1=i)=bi(y1)⋅π(q1)
对于 α i ( 2 ) \alpha_i(2) αi(2),由于 P ( y 2 ∣ q 2 = j ) P\left(y_{2} \mid q_{2}=j\right) P(y2∣q2=j)一项与 i i i没有关系:
α i ( 2 ) = p ( y 1 , y 2 , q 2 = j ) = ∑ i = 1 k p ( y 1 , y 2 , q 1 = i , q 2 = j ) = ∑ i = 1 k p ( y 2 ∣ q 2 = j ) ⋅ p ( q 1 = j ∣ q 1 = i ) ⋅ p ( y 1 , q 1 = i ) ⏟ α i ( 1 ) = p ( y 2 ∣ q 2 = j ) ⏟ b j ( y 2 ) ∑ i = 1 k p ( q 1 = j ∣ q 1 = i ) ⏟ a i , j α i ( 1 ) = b j ( y 2 ) ∑ i = 1 k a i , j α i ( 1 ) . . . α j ( t + 1 ) = [ ∑ i = 1 k α i ( t ) a i , j ] b j ( y t + 1 ) . . . α i ( T ) = b j ( y T ) [ ∑ i = 1 k a i , j α i ( T − 1 ) ] \begin{aligned} \alpha_{i}(2)&=p(y_1,y_2,q_2=j)\\ &=\sum_{i=1}^{k}p(y_1,y_2,q_1=i,q_2=j)\\ &=\sum_{i=1}^{k}p\left(y_{2} \mid q_{2}=j\right) \cdot p\left(q_{1}=j \mid q_1=i\right) \cdot \underbrace{p\left(y_{1}, q_{1}=i\right)}_{\alpha_{i}(1)}\\ &=\underbrace{p\left(y_{2} \mid q_{2}=j\right)}_{b_j(y_2)}\sum_{i=1}^{k}\underbrace{p\left(q_{1}=j \mid q_1=i\right)}_{a_{i,j}}\alpha_{i}(1)\\ &=b_j(y_2)\sum_{i=1}^{k}a_{i,j}\alpha_{i}(1)\\ &...\\ \alpha_{j}(t+1)&=\left[\sum_{i=1}^{k} \alpha_{i}(t) a_{i, j}\right] b_{j}\left(y_{t+1}\right)\\ &...\\ \alpha_{i}(T)&=b_{j}\left(y_{T}\right)\left[\sum_{i=1}^{k} a_{i, j} \alpha_{i}(T-1)\right] \end{aligned} αi(2)αj(t+1)αi(T)=p(y1,y2,q2=j)=i=1∑kp(y1,y2,q1=i,q2=j)=i=1∑kp(y2∣q2=j)⋅p(q1=j∣q1=i)⋅αi(1) p(y1,q1=i)=bj(y2) p(y2∣q2=j)i=1∑kai,j p(q1=j∣q1=i)αi(1)=bj(y2)i=1∑kai,jαi(1)...=[i=1∑kαi(t)ai,j]bj(yt+1)...=bj(yT)[i=1∑kai,jαi(T−1)]
现在只有
k
×
T
k\times T
k×T个运算量而不是
K
T
K^T
KT了,所以到此为止,我们定义了前向过程:
α
i
(
t
)
=
p
(
y
1
,
y
2
,
…
y
t
,
q
t
=
i
∣
λ
)
⟹
p
(
Y
∣
λ
)
=
∑
i
=
1
k
α
i
(
T
)
\alpha_{i}(t)=p\left(y_{1}, y_{2}, \ldots y_{t}, q_{t}=i \mid \lambda\right) \Longrightarrow p(Y \mid \lambda)=\sum_{i=1}^{k} \alpha_{i}(T)
αi(t)=p(y1,y2,…yt,qt=i∣λ)⟹p(Y∣λ)=i=1∑kαi(T)
这是最后在t时处于状态i部分序列 y 1 , … , y t y_1,\dots,y_t y1,…,yt的概率。
现在的运算量只有KT而不是KT:
P
(
y
1
…
y
T
)
=
∑
j
=
1
k
α
j
(
T
)
{P\left(y_{1} \ldots y_{T}\right)}{=\sum_{j=1}^{k} \alpha_{j}(T)}
P(y1…yT)=j=1∑kαj(T)


以上讲解的都是Evaluate,现在讲怎么把
λ
\lambda
λ学出来
4. EM算法参数学习
EM算法:
θ
(
g
+
1
)
=
argmax
θ
∫
Q
log
P
(
Y
,
Q
)
⋅
P
(
Q
∣
Y
,
θ
(
g
)
)
⋅
d
Q
\theta^{(g+1)}=\underset{\theta}{\operatorname{argmax}} \int_{Q} \log P(Y, Q) \cdot P\left(Q \mid Y ,\theta^{(g)}\right) \cdot d Q
θ(g+1)=θargmax∫QlogP(Y,Q)⋅P(Q∣Y,θ(g))⋅dQ
因为
P
(
Q
,
Y
∣
θ
(
g
)
)
P\left(Q ,Y \mid\theta^{(g)}\right)
P(Q,Y∣θ(g))=
P
(
Q
∣
Y
,
θ
(
g
)
)
⋅
P
(
Y
∣
θ
(
g
)
)
P\left(Q \mid Y ,\theta^{(g)}\right) \cdot P(Y \mid \theta^{(g)})
P(Q∣Y,θ(g))⋅P(Y∣θ(g)),由于最后一项与
θ
\theta
θ没有关系,与
Q
Q
Q没有关系,这是一个常数,乘不乘对结果没有影响,所以我们写成:
θ
(
g
+
1
)
=
argmax
θ
∫
Q
log
P
(
Y
,
Q
)
⋅
P
(
Q
,
Y
∣
θ
(
g
)
)
⋅
d
Q
\theta^{(g+1)}=\underset{\theta}{\operatorname{argmax}} \int_{Q} \log P(Y, Q) \cdot P\left(Q ,Y \mid\theta^{(g)}\right) \cdot d Q
θ(g+1)=θargmax∫QlogP(Y,Q)⋅P(Q,Y∣θ(g))⋅dQ
之前我们已经知道:
p
(
Y
∣
λ
)
=
∑
Q
[
p
(
Y
,
Q
∣
λ
)
]
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
[
p
(
y
1
,
…
,
y
T
,
q
1
,
…
q
T
∣
λ
)
]
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
[
p
(
y
1
,
…
,
y
T
,
q
0
,
q
1
,
…
q
T
∣
λ
)
]
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
p
(
q
1
)
p
(
y
1
∣
q
1
)
p
(
q
2
∣
q
1
)
…
p
(
q
t
∣
q
t
−
1
)
p
(
y
t
∣
q
t
)
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
π
(
q
1
)
∏
t
=
2
T
a
q
t
−
1
,
q
t
b
q
t
(
y
t
)
\begin{aligned} p(Y \mid \lambda) &=\sum_{Q}[p(Y, Q \mid \lambda)]=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k}\left[p\left(y_{1}, \ldots, y_{T}, q_{1}, \ldots q_{T} \mid \lambda\right)\right] \\ &=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k}\left[p\left(y_{1}, \ldots, y_{T}, q_{0}, q_{1}, \ldots q_{T} \mid \lambda\right)\right] \\ &=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k} p\left(q_{1}\right) p\left(y_{1} \mid q_{1}\right) p\left(q_{2} \mid q_{1}\right) \ldots p\left(q_{t} \mid q_{t-1}\right) p\left(y_{t} \mid q_{t}\right) \\ &=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k} \pi\left(q_{1}\right) \prod_{t=2}^{T} a_{q_{t-1}, q_{t}} b_{q_{t}}\left(y_{t}\right) \end{aligned}
p(Y∣λ)=Q∑[p(Y,Q∣λ)]=q1=1∑k…,qT=1∑k[p(y1,…,yT,q1,…qT∣λ)]=q1=1∑k…,qT=1∑k[p(y1,…,yT,q0,q1,…qT∣λ)]=q1=1∑k…,qT=1∑kp(q1)p(y1∣q1)p(q2∣q1)…p(qt∣qt−1)p(yt∣qt)=q1=1∑k…,qT=1∑kπ(q1)t=2∏Taqt−1,qtbqt(yt)
所以前一个式子即为:
θ
(
g
+
1
)
=
argmax
θ
∫
Q
log
[
p
(
q
1
)
∏
t
=
2
T
a
q
t
−
1
,
q
t
∏
t
=
1
T
b
q
t
(
y
t
)
]
⋅
P
(
Q
,
Y
∣
θ
(
g
)
)
⋅
d
Q
=
∑
q
1
=
1
k
…
,
∑
q
T
=
1
k
[
log
π
(
q
1
)
+
∑
t
=
2
T
log
a
q
t
−
1
,
q
t
+
∑
t
=
1
T
log
b
q
t
(
y
t
)
]
⋅
P
(
Q
,
Y
∣
θ
(
g
)
)
\begin{aligned} \theta^{(g+1)}&=\underset{\theta}{\operatorname{argmax}} \int_{Q} \log [ p\left(q_{1}\right) \prod_{t=2}^{T} a_{q_{t-1}, q_{t}} \prod_{t=1}^{T}b_{q_{t}}\left(y_{t}\right)] \cdot P\left(Q ,Y \mid\theta^{(g)}\right) \cdot d Q\\ &=\sum_{q_{1}=1}^{k} \ldots, \sum_{q_{T}=1}^{k} [\log \pi\left(q_{1}\right) +\sum_{t=2}^{T} \log a_{q_{t-1}, q_{t}}+ \sum_{t=1}^{T}\log b_{q_{t}}\left(y_{t}\right)] \cdot P\left(Q ,Y \mid\theta^{(g)}\right)\\ \end{aligned}
θ(g+1)=θargmax∫Qlog[p(q1)t=2∏Taqt−1,qtt=1∏Tbqt(yt)]⋅P(Q,Y∣θ(g))⋅dQ=q1=1∑k…,qT=1∑k[logπ(q1)+t=2∑Tlogaqt−1,qt+t=1∑Tlogbqt(yt)]⋅P(Q,Y∣θ(g))

对于每一个term,可以分别由观测数据学习其对应参数,例如对于
π
\pi
π:
Q
term
1
=
∑
q
0
=
1
k
⋯
∑
q
T
=
1
k
ln
π
q
0
p
(
q
,
Y
∣
λ
(
g
)
)
=
∑
i
=
1
k
ln
π
i
p
(
q
0
=
i
,
Y
∣
λ
(
g
)
)
\mathcal{Q}^{\operatorname{term} 1}=\sum_{q_{0}=1}^{k} \cdots \sum_{q_{T}=1}^{k} \ln \pi_{q_{0}} p\left(q, Y \mid \lambda^{(g)}\right)=\sum_{i=1}^{k} \ln \pi_{i} p\left(q_{0}=i, Y \mid \lambda^{(g)}\right)
Qterm1=q0=1∑k⋯qT=1∑klnπq0p(q,Y∣λ(g))=i=1∑klnπip(q0=i,Y∣λ(g))
约束条件:
arg
max
(
Q
term
1
)
with
∑
i
=
1
k
π
i
=
1
\arg \max \left(\mathcal{Q}^{\text {term } 1}\right) \text { with } \sum_{i=1}^{k} \pi_{i}=1
argmax(Qterm 1) with i=1∑kπi=1
使用拉格朗日中值定理:
L
M
term
1
=
∑
i
=
1
k
ln
π
i
p
(
q
0
=
i
,
Y
∣
λ
(
g
)
)
+
τ
(
∑
i
=
1
k
π
i
−
1
)
\mathbb{L M}^{\text {term } 1}=\sum_{i=1}^{k} \ln \pi_{i} p\left(q_{0}=i, Y \mid \lambda^{(g)}\right)+\tau\left(\sum_{i=1}^{k} \pi_{i}-1\right)
LMterm 1=i=1∑klnπip(q0=i,Y∣λ(g))+τ(i=1∑kπi−1)
对两项求导,令其等于0:
∂
L
M
term
1
∂
π
i
=
p
(
q
,
Y
∣
λ
(
g
)
)
π
j
+
τ
=
0
∂
L
M
term
1
∂
τ
=
∑
i
=
1
k
π
i
−
1
=
0
\frac{\partial \mathbb{L} \mathbb{M}^{\text {term } 1}}{\partial \pi_{i}}=\frac{p\left(q, Y \mid \lambda^{(g)}\right)}{\pi_{j}}+\tau=0 \quad \frac{\partial \mathbb{L} \mathbb{M}^{\text {term } 1}}{\partial \tau}=\sum_{i=1}^{k} \pi_{i}-1=0
∂πi∂LMterm 1=πjp(q,Y∣λ(g))+τ=0∂τ∂LMterm 1=i=1∑kπi−1=0
p
(
q
0
=
i
,
Y
∣
λ
(
g
)
)
=
−
τ
π
i
p\left(q_{0}=i, Y \mid \lambda^{(g)}\right)=-\tau \pi_{i}
p(q0=i,Y∣λ(g))=−τπi
为了使用到约束条件,两边相加:
∑
i
=
1
k
p
(
q
0
=
i
,
Y
∣
λ
(
g
)
)
=
−
τ
∑
i
=
1
k
π
i
=
−
τ
\sum_{i=1}^{k} p\left(q_{0}=i, Y \mid \lambda^{(g)}\right)=-\tau \sum_{i=1}^{k} \pi_{i}=-\tau
i=1∑kp(q0=i,Y∣λ(g))=−τi=1∑kπi=−τ
代入可得:
π
i
=
p
(
q
0
=
i
,
Y
∣
λ
(
g
)
)
−
τ
⟹
π
i
=
p
(
q
0
=
i
,
Y
∣
λ
(
g
)
)
∑
i
=
1
k
p
(
q
0
=
i
,
Y
∣
λ
(
g
)
)
\pi_{i}=\frac{p\left(q_{0}=i, Y \mid \lambda^{(g)}\right)}{-\tau} \Longrightarrow \pi_{i}=\frac{p\left(q_{0}=i, Y \mid \lambda^{(g)}\right)}{\sum_{i=1}^{k} p\left(q_{0}=i, Y \mid \lambda(g)\right)}
πi=−τp(q0=i,Y∣λ(g))⟹πi=∑i=1kp(q0=i,Y∣λ(g))p(q0=i,Y∣λ(g))


小结
基本算是入了一个门,主要在听思路,三个典型问题的第三个这个视频没有讲,应该需要用维特比(Viterbi)算法进行递归,这个不会;EM算法公式怎么推的很不会。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









