







在prometheus中,metrics中的数据只是一些零散单一的数据,比如我们要知道cpu、内存这些数据一段时间内的最值,如:
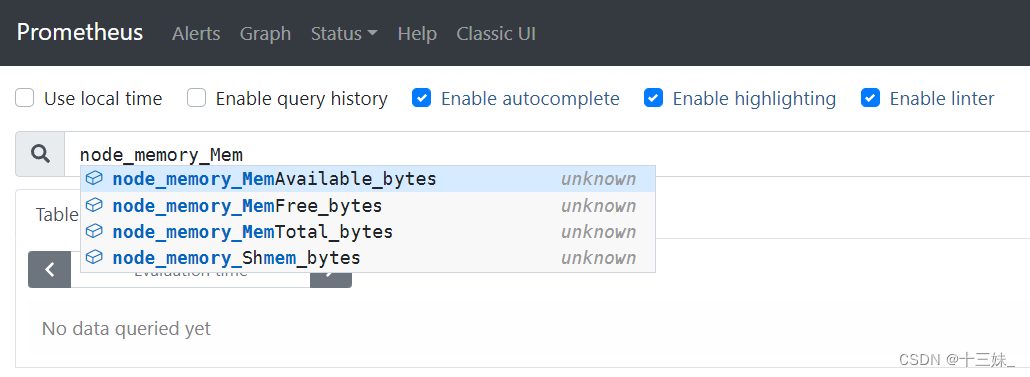
考虑到一些性能使用(当集群庞大时计算这些数据十分耗资源)。我们在运维时可以根据自身需要来自定义一些prometheus规则。同告警规则一样,我们需要自定义yml文件,在prometheus.yml配置文件中指向该yml文件(可以与告警规则在同一文件中,prometheus会根据匹配符自动区分)。
###prometheus.yml文件中定义好规则文件所在位置
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- 'rules/*.yml'
# A scrape configuration containing exactly one endpoint to scrape:下面开始自定义规则(这里仅举例,可根据自己实际生产需求来定义):
编辑rules/rule.yml
groups:
- name: node_usage_record
interval: 1m
rules:
- record: cpu:usage:max
expr: (1-(min(irate(node_cpu_seconds_total{mode="idle"}[1d])) by (instance))) * 100
- record: mem_usage
expr: (1 - ( node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes - node_memory_Shmem_bytes - node_memory_SUnreclaim_bytes) / (node_memory_MemTotal_bytes )) * 100
#上述内存计算方式可满足redhat/Centos6和7版本以及suse系统,而普通的available/total可能仅适用红帽系7版本./promtool check config prometheus.yml 检查规则是否正确,若全为success则可重启或热加载(当集群较大建议使用热加载kill -HUP 进程号,重启十分耗时)prometheus服务使配置生效。
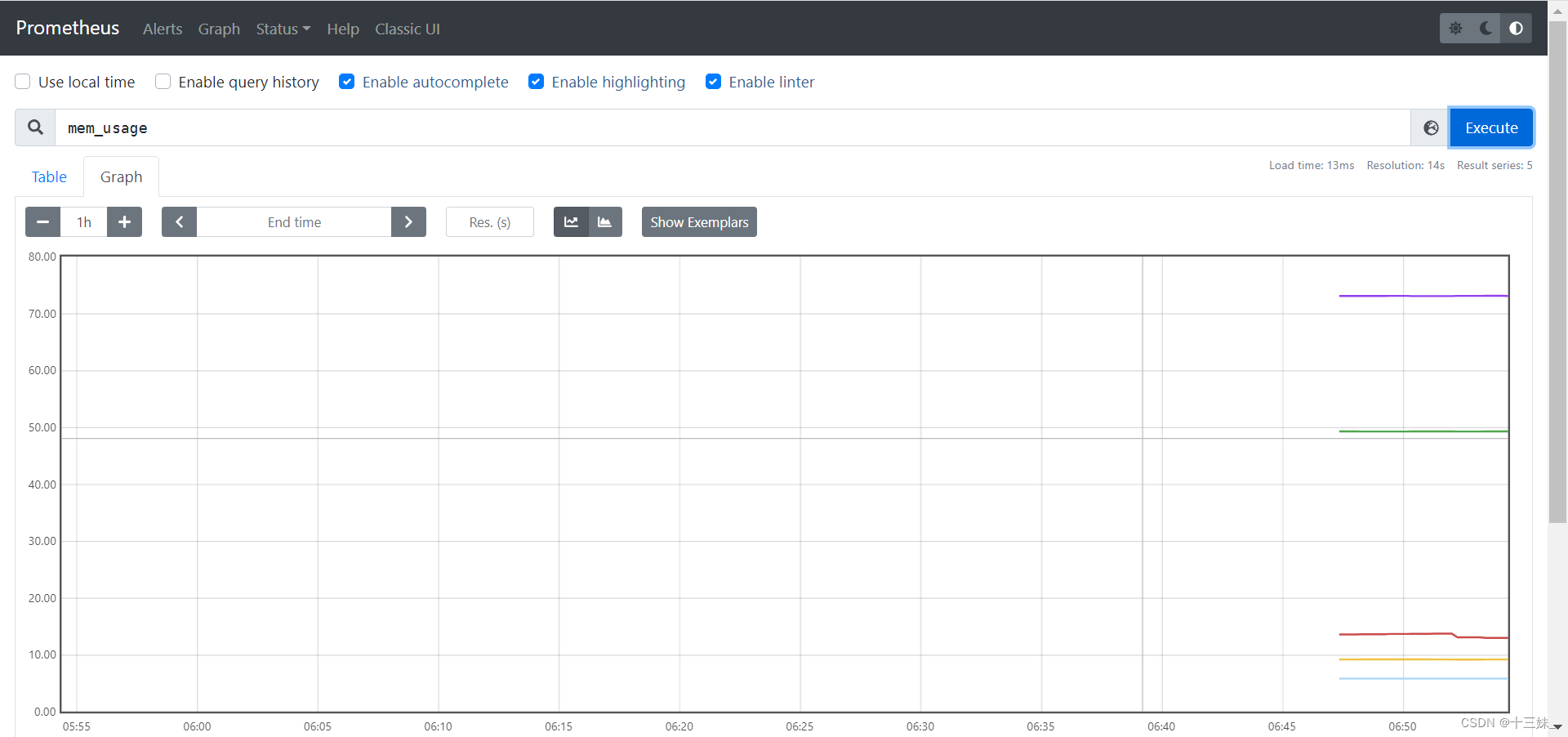
成功!
在grafana中自己也可以根据新的指标来制作图表

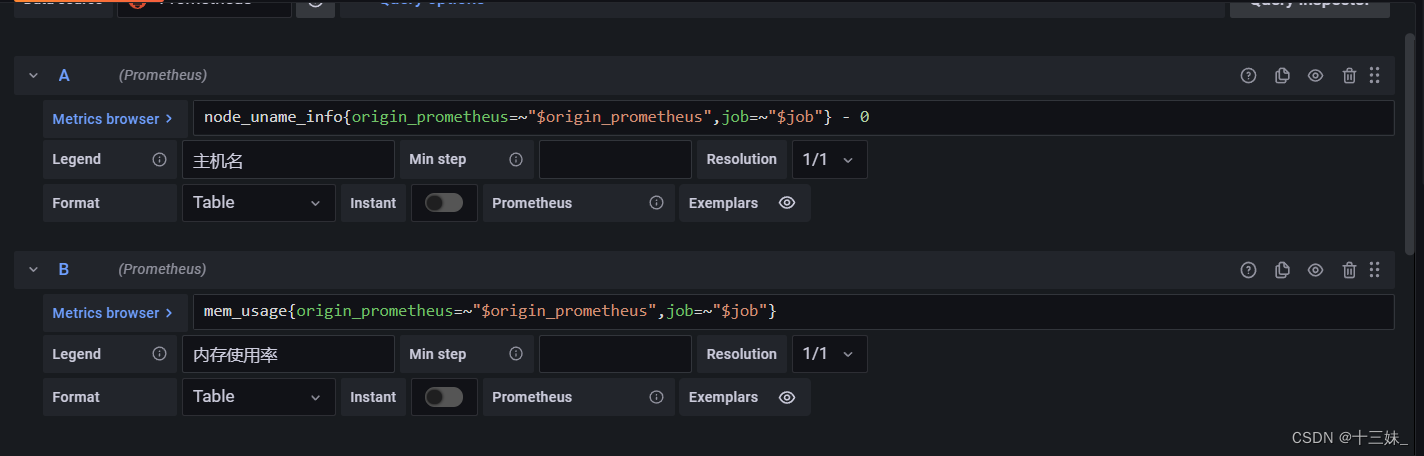
欢迎指正

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









