







 本文介绍了pandas中处理缺失值的方法,包括使用inplace参数替换缺失值,以及如何根据现有数据计算填充。还探讨了如何利用iloc和loc进行精确的数据定位,并介绍了pct_change函数用于计算变化率的功能。最后提到了层次索引的应用。
本文介绍了pandas中处理缺失值的方法,包括使用inplace参数替换缺失值,以及如何根据现有数据计算填充。还探讨了如何利用iloc和loc进行精确的数据定位,并介绍了pct_change函数用于计算变化率的功能。最后提到了层次索引的应用。
1.缺失值处理。


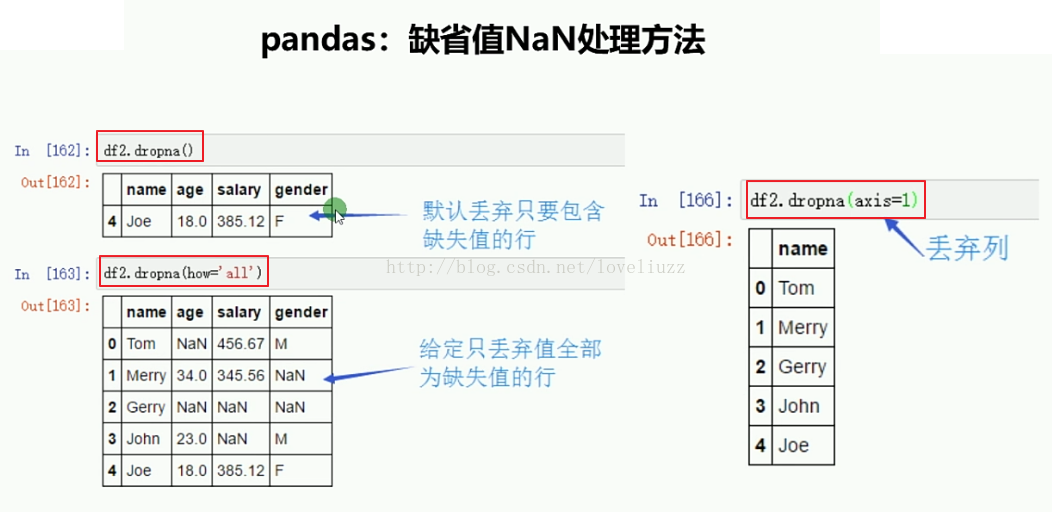
inplace参数为True则取代当前df,否则返回一个执行函数的df的复制。

2.但是nan填充值具体是什么呢,可以根据现有的数据经过计算来选择,更符合当前数据的规律。
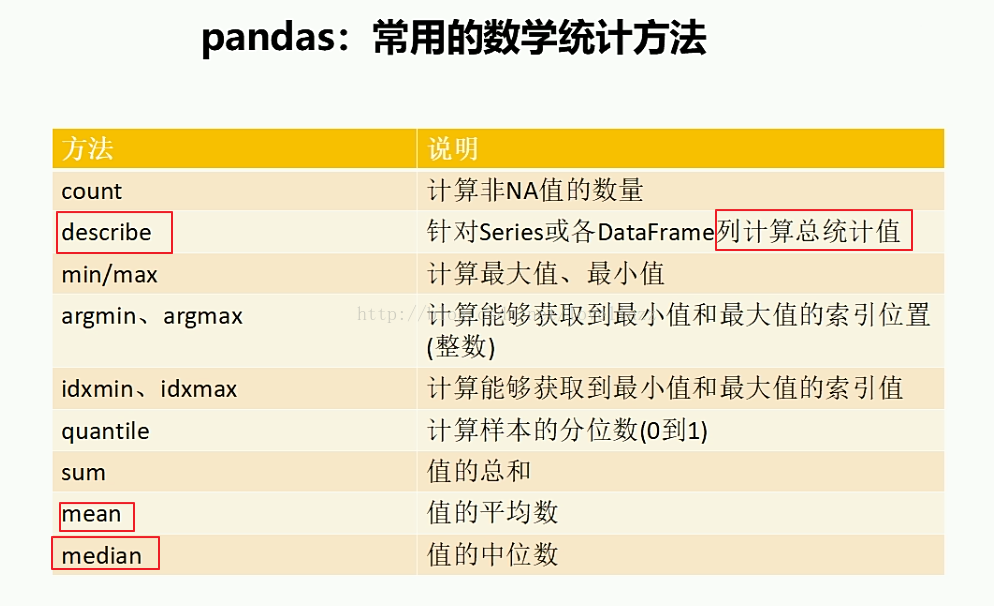
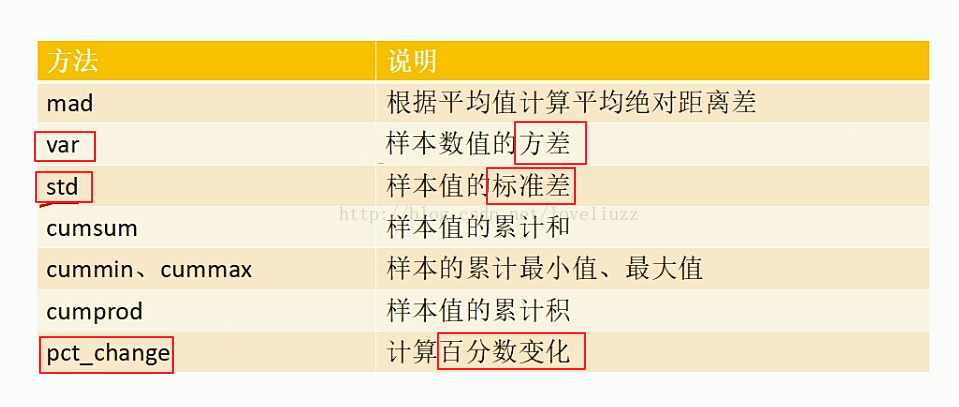
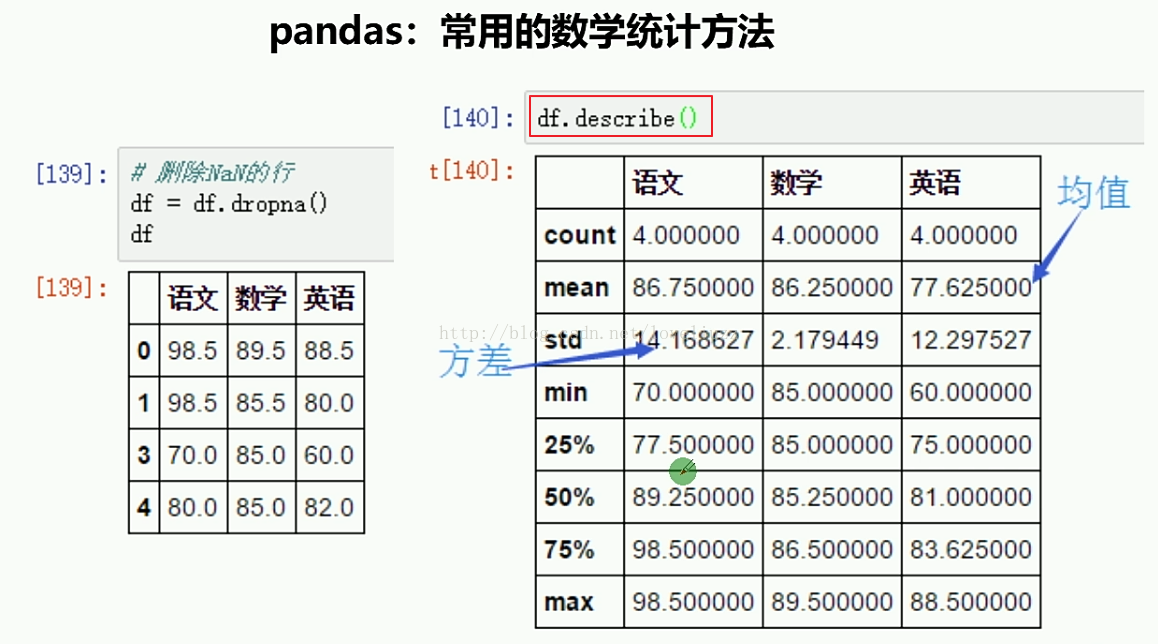

iloc,即index locate 用index索引进行定位,所以参数是整型,如:df.iloc[10:20, 3:5]
loc,则可以使用column名和index名进行定位,如:
df.loc[‘image1’:‘image10’, ‘age’:‘score’]
pct_change函数计算变化率:(后一个值-前一个值)/前一个值
默认period为1




3.层次索引


import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#3.pandas层次索引
data = Series([998.4,6455,5432,9765,5432],
index=[["2001","2001","2001","2002","2002"],
["苹果","香蕉","西瓜","苹果","西瓜"]]
)
print(data)
df4 = DataFrame({
"year":[2001,2001,2002,2002,2003],
"fruit":["apple","banana","apple","banana","apple"],
"production":[2345,5632,3245,6432,4532],
"profits":[245.6,432.7,534.1,354,467.8]
})
print(df4)
print("=======层次化索引=======")
df4 = df4.set_index(["year","fruit"])
print(df4)
print("=======依照索引取值=======")
print(df4.ix[2002,"apple"])
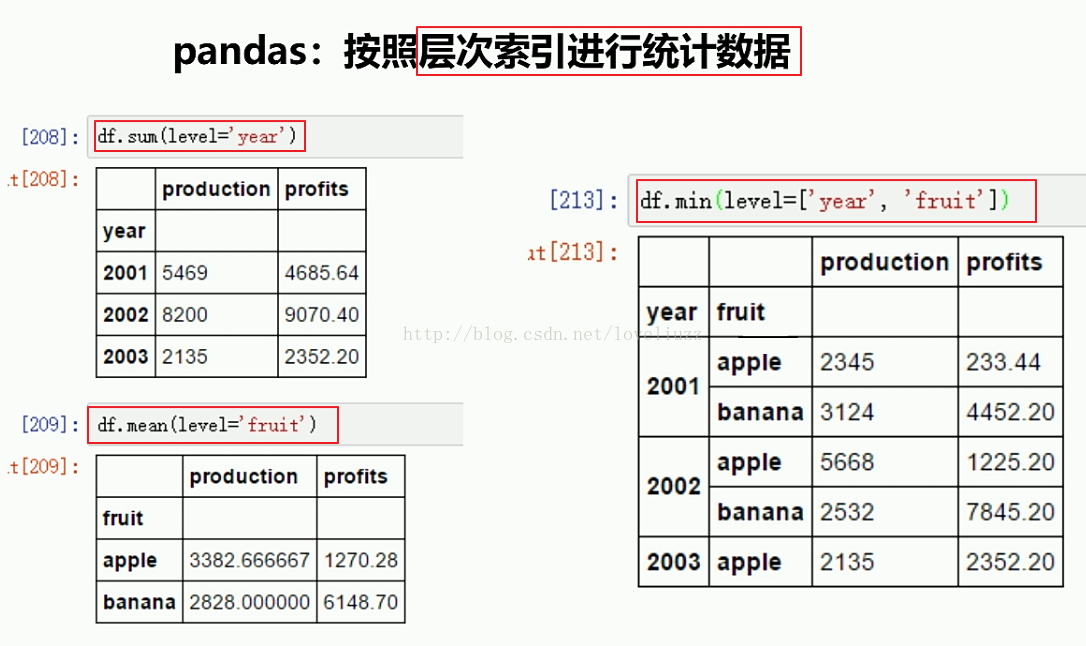
print("=======依照层次化索引统计数据=======")
print(df4.sum(level="year"))
print(df4.mean(level="fruit"))
print(df4.min(level=["year","fruit"]))
#运行结果:
2001 苹果 998.4
香蕉 6455.0
西瓜 5432.0
2002 苹果 9765.0
西瓜 5432.0
dtype: float64
fruit production profits year
0 apple 2345 245.6 2001
1 banana 5632 432.7 2001
2 apple 3245 534.1 2002
3 banana 6432 354.0 2002
4 apple 4532 467.8 2003
=======层次化索引=======
production profits
year fruit
2001 apple 2345 245.6
banana 5632 432.7
2002 apple 3245 534.1
banana 6432 354.0
2003 apple 4532 467.8
=======依照索引取值=======
production 3245.0
profits 534.1
Name: (2002, apple), dtype: float64
=======依照层次化索引统计数据=======
production profits
year
2001 7977 678.3
2002 9677 888.1
2003 4532 467.8
production profits
fruit
apple 3374 415.833333
banana 6032 393.350000
production profits
year fruit
2001 apple 2345 245.6
banana 5632 432.7
2002 apple 3245 534.1
banana 6432 354.0
2003 apple 4532 467.8
————————————————
版权声明:本文为优快云博主「loveliuzz」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/loveliuzz/article/details/78498121


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









