







数据库人员分类:开发、管理、优化、设计
命令:
跟踪执行更新产生的日志情况:
更新语句执行前后,执行一下语句,两日志大小只差就是本次更新产生的日志
select a.name,b.value from v$statname a, v$mystat b where a.statistic# = b.statistic# and a.name = 'redo size';
跟踪数据库读数据情况
set autotrace traceonly;
查看参数文件、控制文件、数据文件在主机的位置
show parameter spfile(参数文件)/control(控制文件)
select file_name from dba_data_files ;//数据文件
select group#,member from v$logfile; //日志文件
查看共享池使用情况:
select pool , sum(bytes)/1024/1024 || 'MB' from v$sgastat where pool is not null group by pool;
查看共享池解析sql情况:
select t.sql_text,t.sql_id, t.parse_calls , t.EXECUTIONS from v$sql t
where t.sql_text like 'select user_id,user_name from users t where t.home_city=%';
物理体系
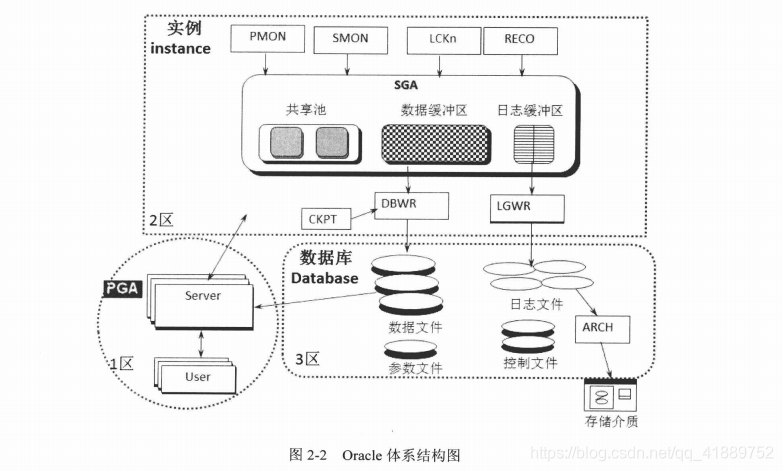
oracle共享池:库高速缓存 + 数字字典高速缓存
库高速缓存:LRU队列和算法 存放执行的SQL,没有内存空间时
数字字典高速缓存:数据文件、表、索引、列、用户、其他的数据对象的定义和权限信息
共享池的大小受限制于SGA_MAX_SIZE参数的大小。
alter system set shared_pool_size= xxx m
select SQL语句的执行顺序
1. 首先进入PGA(程序全局区,获取用户连接信息、权限等,并匹配唯一hash值)
2. 进入SGA(系统全局区)中的共享池(如果存在相同表定义、语句语法等则不做校验,直接从共享池中获取)
3. 进入数据缓存区取数据(如果缓存区不存在该数据,则去数据库中查询,称物理读)//相同的sql语句,第二次执行要比第一次执行快很多,因为少了校验,
并且数据直接在缓存区中获取。另外,共享池判断两个SQL语句,是否相同是根据语句正文是否相同来判断,所以必须使用变量。
update SQL语句的执行顺序
除需要执行select语句的步骤外,更新语句会启动DBWR(数据库书写器),将更新后的数据写入磁盘.另做更新操作时,日志会将更新动作写入日志缓冲区,
当发生意外情况时(执行失败),可以重复执行日志缓冲区记录的动作,保证执行成功.日志缓冲区写满后,会备份成日志文件,以为后面的记日志腾出空间.
做更新操作时,需要提交事务.oracle采用批量提交的方式,当数据量达到一定大小时,做一次批量提交(因为有日志文件,所以不怕数据丢失/同时也有回滚操作的
日志,以提供回滚操作)。
回滚操作保持查询数据的一致性:
查询时间较长,比如要查询十组数据,前三组数据查询时,第八组数据被修改了,此时查询到的第八组数据是修改之前的(原理:开始查询时刻,有一个SCN,当后续
查到的数据时间在这个时间之后,且数据有发生更新时,从回滚槽 dudo块中获取修改前的数据以供查询)
修改oracle实例参数


通过修改oracle的参数来控制数据库实例化后分配的内存空间进而优化oracle速度
数据库归档模式:当日志缓冲区写满后,需要将其归档到归档文件中,防止日志覆盖/丢失(有些数据库对安全性能要求高,会关闭改功能)
数据库的启动(startup命令):
1.startup nomount阶段
读取参数文件(根据参数文件的内存分配策略分配相应的内存区域,并启动后台进程),创建实例
show parameter pfile //查看是否启动成功
2.startup mount阶段
根据参数文件,查找控制文件(记录了数据文件,日志文件,检查点等重要信息).连接实例和数据库的桥梁
3.alter database open阶段
数据库关闭(启动的反向,shutdown immediate)
逻辑结构
数据库:表空间(tabelspace)、段(segment)、区(extent)、数据库块(block)
段(segment):新建表T时,系统就会为其分配段(Segment T),段分配成功之后,会立即为其分配若干数据块的初始数据扩展(即使表中没数据)
表空间(tableSpace): 数据表空间(储存数据)、系统表空间(维护作用)、临时表空间、回滚表空间
表空间不足报错: 建表空间时,未设置成自动扩展 解决: 修改为自动扩展/增加数据文件
临时表空间: 可以有多个,同时投入运行
优点: 并行,分担IO竞争(oracle 10g以后推出的临时表空间组,可以不断往组里面添加临时表空间,用户指定组以后,运行时,
选择组里面的表空间,IO均衡负载,极大提高数据库性能)
回滚表空间: 可以有多个,但是只有有一个投入使用.
优点: 只有一个回滚表空间的时候,数据量大的时候,需要不断地 扩展空间,导致空间浪费.有多个,当数据量大的时候,
可以做切换,删除原来旧的表空间.
查看表空间扩展次数:
select * from user_extents where segment_name='table_name';
如果频繁插入,可以选择加大表空间初始大小,和扩展容量来减少扩展次数,提高性能
PCTFREE: 为一个块保留的空间百分比(默认10%)
备注: 当块剩余低于这个百分比之后,再次扩大表数据就会另辟新的数据块,导致行迁移(行迁移不会影响全表扫描,会影响索引查询或通过rowid查询,主要由于一次
读取要访问两个块).
表设计成就英雄
普通堆表(适合大部分设计场景):
不足:
1.表更新有日志开销
2.表delete操作有瑕疵
3.表记录太大索引较慢
4.索引回滚读开销大
5.有序插入难有序读出
全局临时表(适合接口表设计):
分区表(适合日志表):
神通广大的分区表
原理:不同分区存在不同的段(segment)中
类型:range分区,list分区,hash分区,组合分区
range分区:
使用最广泛,可用于范围的,比如时间在某个区间放一个分区
list分区
某个值的分区,比如福州市编码的放一个分区,宁德市的放一个分区
hash分区
根据hash算法,分派到不同的分区中(而不是在同一个分区)
分区本身有额外开销,分区越多就需要管理更多的段,因此只有大表才建议
用分区,100万以下的表不建议用分区
特性
1.高效的分区消除(操作落在指定分区,即扫描指定段)
2.高效的记录清理
delete删除数据,无法释放数据块(删除数据后,查询速度不会变快),分区支持truncate 删除分区,并释放内存块
3.高效的分区转移(内部是通过数字字典的小改动实现的,所以速度非常快)
通过exchange patition with table关键字进行两表的分区数据转移,速度极快
分区索引
全局索引--普通索引
局部索引--针对分区的索引
分区表易错点
有分区用不到
分区索引失效
update golbal indexes(分区操作后,会进行索引重建工作) --对分区进行操作时,加入该关键字,可以避免全局索引失效的问题。
分区索引效率低
查询时没将分区条件加入where语句
索引组织表(适合极少更新的配置表):
优点:
不足:
簇表(频繁关联的多表查询):
优点:
不足:

















 3955
3955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









