






Hessian矩阵
定义
假设有一实值函数f(x_1,x_2,……,x_n),如果f的所有二阶偏导数都存在并在定义域内连续,那么函数f的hessian矩阵为
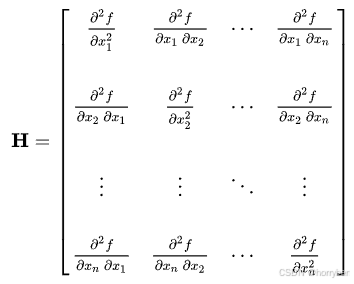
或使用下标记号表示为
显然黑塞矩阵是一个n×n方阵。黑塞矩阵的行列式被称为黑塞式(英语:Hessian),而需注意的是英语环境下使用Hessian一词时可能指上述矩阵也可能指上述矩阵的行列式。
公式推导过程
由高等数学知识可知,若一元函数f(x)在点的某个领域内具有任意阶导数,则函数f(x)在
点处的泰勒展开式为:
其中,
同理,二元函数在
点处的泰勒展开式为
其中,
将上述展开式写成矩阵形式,则有
其中,是
的转置,
是函数
在
的梯度,矩阵
既函数
在
点处的
hessian矩阵,它是由函数
在
点处的所有二阶偏导数所组成的方阵。
由函数的二次连续性,有,所以,hessian矩阵
是对称矩阵。
由二元函数的泰勒展开式推广到多元函数,函数在
点处的泰勒展开式为
其中:为函数f(x)在点
点的梯度,那么就有
为函数f(x)在点
点的
hessian矩阵,若函数有n次连续性,则函数的
hessian矩阵为对称矩阵。
Hessian矩阵在模型参数中的意义
Hessian矩阵是一个二阶偏导数矩阵,用于描述多变量函数的局部曲率。对于一个标量函数 (如神经网络的损失函数),Hessian矩阵
的元素为:(这个标量函数实际就是模型的损失函数)
这里,是模型权重向量。
在模型中,Hessian矩阵就标志着权重大小对模型的影响程度,hessian矩阵在何处曲率最大,那么模型对该方向上的参数变化就更加敏感,故而在量化过程中要小心处理那些曲率较大的参数以避免精度损失。
在GPTQ中,通过对hessian矩阵的分析,设计出针对不同参数类型的自适应量化策略。主要作用在于利用二阶导数信息来优化量化策略。
Hessian矩阵的逆
GPTQ的量化过程涉及使用hessian矩阵的逆,Hessian矩阵H 是一个多变量函数 f的所有二阶偏导数组成的方阵,通常用于描述函数在某一点上的局部曲率。如果H 是非奇异的(即其行列式不为零),则它可以有一个逆矩阵。
可以通过这个逆来找到最小化f的p值,具体涉及公式为;
其中∇f(x)是梯度向量,p是在点x处的增量,想要最小化f,可以求解由上式对p求并取0得到的等式:H(x)p=−∇f(x),这里的就是用来找到p的。
hessian矩阵的逆还能被用来搜索方向,通过乘以负梯度,得到一个搜索方向。使得函数值在该方向上最快下降。
计算Hessian矩阵及其逆在高维空间中是非常昂贵的,特别是在深度学习中处理大规模神经网络时。因此,在实践中,经常使用近似方法或者替代技术(如拟牛顿法)来避免直接计算Hessian矩阵的逆。
GPTQ中的hessian矩阵
GPTQ对随机顺序的参数量化的优化效果不佳、但是在大部分固定顺序的模型参数量化效果较好。(这里的随机顺序与固定顺序应该是模型的结构,像是transformer中带位置编码和不带位置编码的,亦或者是全连接神经网络与卷积加Relu的过程)
{疑问:这种量化的过程是否等同卷积神经网络中的降维操作}
GPTQ中使用了“延迟批处理技术”,我目前并不是很理解这是在干什么,但是应该和这张图有关:
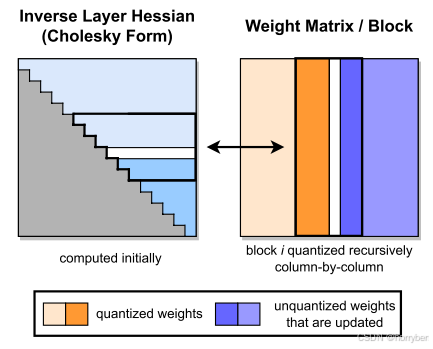
量化表示
在实际应用中,量化的步骤包括将原始浮点数参数映射到离散的整数值。例如:
-
3 位量化:
-
量化级别:通常有 8 个离散值,例如:{-7, -5, -3, -1, 1, 3, 5, 7}(如果使用对称量化)。
-
原始参数值被映射到这些离散值中的一个,例如,一个浮点数值 2.5 可能会被量化为 3(在量化级别中最接近的值)。
-
-
4 位量化:
-
量化级别:通常有 16 个离散值,例如:{-15, -13, -11, -9, -7, -5, -3, -1, 1, 3, 5, 7, 9, 11, 13, 15}(如果使用对称量化)。
-
原始参数值被映射到这些离散值中的一个,例如,一个浮点数值 7.2 可能会被量化为 7(在量化级别中最接近的值)。
-
GPTQ原文中的细节内容
-
一种训练后量化方法
-
可以在几小时内执行千亿参数的模型量化、
-
不显著损失精度的情况下将模型压缩到每个参数3或者位、
-
实践创建了一个生成任务的压缩模型。
-
当前结果不包括激活量化。
-
OBQ量化方法:层级量化(独立处理每个row),找到使平方误差最小的量化权重矩阵W。通过计算每行的平方误差之和,独立的处理每行。每次只量化一个权重,同时更新所有尚未量化的权重,使用两个主要公式对权重进行迭代量化。附带了一个矢量化的实现,可以并行处理W的多行,可以在中等规模的模型实现合理的运行时间。
-
找到了OBQ量化中无法有效量化重参数化层的权重的问题,文中分析的原因是在量化过程结束时,那些可以调整补偿其他权重的权重补偿被最后的量化过程抵消了,只剩少数几个可以调整以进行补偿的量化权重。
-
GPTQ中使用相同顺序量化所有行的权重,将算法同时作用于多个块,保持所有块的更新,在处理完成后才对整个
和权重矩阵W进行全局更新。
-
针对OBQ只能处理中型模型的原因进行了分析,同时提出了新的可以解决"无法正确利用现代GPU的大规模计算能力"的方法:”延迟批处理“(使用一组索引代替OBQ中的单个索引值),这个方法有效的解决了内存吞吐量瓶颈。
-
优化Cholesky方法:这个方法的优化背景是大模型在量化后的数值不准确,
的不确定会导致算法在不正确的方向积极更新剩余权重,这种情况与模型大小有关,主要原因为GPTQ主要公式2的重复应用。这里的解决办法是在H的对角线元素添加一个常数λ.这个方法对于大模型来说缺乏健壮性与通用性。
我们来观察以下公式内容,其包含了GPTQ主要的计算过程与思想:
以下为OBQ中的主要公式:
以下为GPTQ中的主要公式:
在上面的式子中,F为剩余的全精度权重集,为贪婪最优权重,
为一组序列的贪婪最优权重。δF为最优更新。

















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









