







 本文介绍了如何利用graphviz和相关Python库pyreverse、pycallgraph,对Python代码进行逆向工程,自动绘制UML类图和函数调用图。首先讲解了安装graphviz和相关库的步骤,接着详细阐述了如何使用pyreverse绘制UML类图,以及如何使用pycallgraph生成函数调用图。此外,还探讨了Python中的数据结构如list的处理方法,如多维list去重和排序,以及介绍了sortedcontainers库中的SortedList、SortedDict和SortedSet的使用。
本文介绍了如何利用graphviz和相关Python库pyreverse、pycallgraph,对Python代码进行逆向工程,自动绘制UML类图和函数调用图。首先讲解了安装graphviz和相关库的步骤,接着详细阐述了如何使用pyreverse绘制UML类图,以及如何使用pycallgraph生成函数调用图。此外,还探讨了Python中的数据结构如list的处理方法,如多维list去重和排序,以及介绍了sortedcontainers库中的SortedList、SortedDict和SortedSet的使用。
😡😡😡
python逆向工程:Python代码自动绘制UML类图、函数调用图
itertools.accumulate():快速计算前缀和
二分查找库函数:bisect(), bisect_left(),bisect_right()
😡😡😡
python逆向工程:Python代码自动绘制UML类图、函数调用图
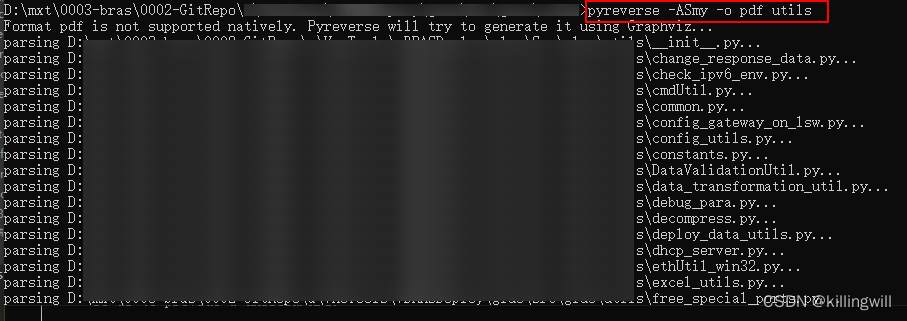
# NOTE:图片形式的类图(-o png)不方便查看搜索,输出为pdf形式更佳
pyreverse -ASmy -o pdf [dirName]
anaconda:Anaconda系列:conda是什么?conda与pip的区别是什么?
官网:https://www.anaconda.com/
conda:
官网:https://docs.conda.io/en/latest/
下载:https://docs.conda.io/projects/conda/en/latest/user-guide/install/download.html
Conda介绍:
https://blog.youkuaiyun.com/koflance/article/details/78582737
conda类似于npm或maven的包管理工具,只是conda是针对于python的。可以安装minconda或anaconda进行安装,前者是简化版本,只包含conda和其依赖。如果安装环境有python相关包也没有关系,不需要进行卸载。
anaconda支持windows、mac和linux系统,且有两个类型的版本,分别是GUI和command line版本,前者是图形界面,后者是命令行界面,占用资源较少。
conda有python3.x和python2.x系列两个版本,其实都没有关系,因为你在使用conda进行创建环境时,可以指定python的版本。
https://blog.youkuaiyun.com/zhanghai4155/article/details/104215198
Conda是适用于任何语言的软件包、依赖项和环境管理系统–包括Python,R,Ruby,Lua,Scala,Java,JavaScript,C / C ++,FORTRAN等。
Conda是在Windows、macOS和Linux上运行的开源软件包管理系统和环境管理系统。Conda可以快速安装、运行和更新软件包及其依赖项。Conda可以轻松地在本地计算机上的环境中创建,保存,加载和切换。它是为Python程序创建的,但可以打包和分发适用于任何语言的软件。
作为软件包管理器,可以帮助您查找和安装软件包。如果您需要一个能够使用不同版本Python的软件包,则无需切换到其他环境管理器,因为conda也是环境管理器。仅需几个命令,您就可以设置一个完全独立的环境来运行不同版本的Python,同时继续在正常环境中运行喜欢的Python版本。
在默认配置下,conda可以安装和管理来自repo.anaconda.com仓库的7,500多个软件包,该仓库由Anaconda生成,审查和维护。
也可以与Travis CI和AppVeyor等持续集成系统结合使用,以提供对代码的频繁,自动化测试。
所有版本的Anaconda, Miniconda和 Anaconda存储库均包含conda软件包和环境管理器 。Conda也被包含在Anaconda Enterprise中,该公司为Python,R,Node.js,Java和其他应用程序堆栈提供现场企业包和环境管理。Conda还可以在社区频道conda- forge上获取 。当然,也可以在PyPI中获取Conda,但是通过这种方法可能不是最新的。
python逆向工程:依据Python代码自动绘制UML类图、函数调用图:
https://blog.youkuaiyun.com/Bit_Coders/article/details/120722430
1. 引言
在设计软件、分析代码时,我们常常会借助UML以及函数调用图,来帮自己梳理思路。
尤其是遇到bug时,借助这些可视化手段,也可以帮你在调试过程中发现逻辑错误。
本文主要介绍以下两个方法:
借助graphviz+pyreverse,自动提取python代码的UML类图和包依赖关系。
借助graphviz+pycallgraph,自动提取python代码的动态调用流程图。
2. 绘制UML类图
2.1 安装graphviz
Graphviz 是一个开源图形可视化软件。
Graphviz 以简单的文本语言对图形进行描述,并以多种有用的格式制作图表,例如用于网页的图像和 SVG,用于包含在 PDF 或其他文档中的 Postscript;或显示在交互式图形浏览器中。
步骤①:从官网下载graphviz软件
下载exe安装包,完成graphviz软件安装,并找到bin路径。
步骤②:设置环境变量
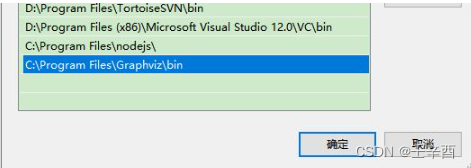
在这里插入图片描述
步骤③:安装对应python库
$
conda install python-graphviz
2.2 安装pyreverse
pyreverse是一组用于对 Python 代码进行逆向工程的实用程序。
可以分析Python代码并提取 UML 类图和包依赖关系1:
- 类属性,及其类型
- 类方法
- 类之间的继承链接
- 类之间的关联链接
- 异常和接口的表示
Pyreverse 现在已集成到 pylint 中:http://pypi.python.org/pypi/pylint/
安装pylint:
$
pip install pylin
注意:pip install pyreverse时,会发现已经找不到这个库了:ERROR: Could not find a version that satisfies the requirement pyreverse,不过pylint中已经包含了pyreverse,所以直接安装pylint即可。
2.3 绘制UML类图
UML类图常用于面向对象的建模中,UML类图的每个方框是一个对象类,每个框从上到下分为三部分,第一部分是对象类名称,第二部分是类的属性,第三部分是类的函数。
在命令行输入语句,生成package的UML图:
$
pyreverse -o png -p Pyreverse pylint/pyreverse/
[…]
creating diagram packages_Pyreverse.png
creating diagram classes_Pyreverse.png
-o :设置保存图像的格式,如png
-p Name: 输出图形以packages_Name.png为名称保存
3. 绘制函数调用图
函数调用图(Call Graph)是一个控制流程图,用于表示程序中各个单元之间的调用关系。每个节点之间的边缘表示调用过程。循环曲线表示递归过程调用。
绘制Call Graph的常用工具有:pycallgraph、pyan(静态调用图)、gprof2dot 、code2flow等。本文主要介绍pycallgraph的用法。
pycallgraph是一个python模块,可以对python代码进行动态调用图分析。包括模块之间的调用流程、函数调用次数及耗时等。
3.1 安装graphviz
同2.1节。
步骤①:从官网下载graphviz软件
官网下载:http://www.graphviz.org/download/
下载exe安装包,完成graphviz软件安装,并找到bin路径。
步骤②:设置环境变量
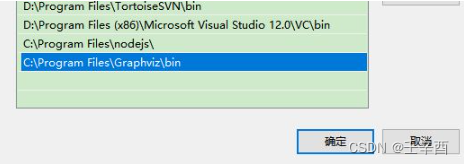
步骤③:安装对应python库
$
pip install graphviz
3.2 安装pycallgraph
安装pycallgraph:
$
pip install pycallgraph
3.3 使用示例
第一种:从命令行调用
$ pycallgraph graphviz -- ./mypythonscript.py
第二种:从API调用
最简单的例子,直接在要分析的函数调用前,加上with PyCallGraph(output=GraphvizOutput())::
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
with PyCallGraph(output=GraphvizOutput()):
# 调用你要分析的函数
code_to_profile()
如果需要指定调用图中包含(include)哪些函数、排除(exclude)哪些函数,就要用到GlobbingFilter(include=[....])、GlobbingFilter(exclude=[....]),例如这样:
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
from pycallgraph import Config
from pycallgraph import GlobbingFilter
def main():
# TODO: 调用各种类、函数
return
if __name__ == "__main__":
config = Config()
# 调用图中包括(include)哪些函数
# 用moduleName.*表示,包含某个模块内的所有函数
config.trace_filter = GlobbingFilter(include=[
'main',
'app.*',
'widgets.list_widget.*',
'utils.RegionInfo.*'
])
# 调用图中不包括(exclude)哪些函数
# config.trace_filter = GlobbingFilter(exclude=[
# 'moduleA.*',
# 'moduleB.*',
# '*.funcB'
# ])
graphviz = GraphvizOutput()
graphviz.output_file = 'graph.png'
with PyCallGraph(output=graphviz, config=config):
main()
在程序正常运行完之后,就会在当前路径生成graph.png文件。
越是复杂的程序,生成的调用图就会越大,注意选取你最关注的函数进行可视化。
其他高级用法可以参考:
小结
本文介绍了两个python代码可视化工具:
- 借助graphviz+pyreverse,可以自动提取python代码的UML类图。
- 借助graphviz+pycallgraph,可以自动提取python代码的动态调用图。
😡😡😡😡😡😡
list
python多维list去重
【python多维list去重】
一维的list去重可以用set(list),但是二维的list转set就会报错 unhashable type: ‘list’
原因是set传进来的是不可哈希的变量
Python中:
- 可哈希的元素:int、float、str、tuple
- 不可哈希的元素:list、set、dict
list 不可哈希,tuple 可哈希原因:
- 因为 list 是可变的在它的生命期内,你可以在任意时间改变其内的元素值。
- 所谓元素可不可哈希,意味着是否使用 hash 进行索引
- list 不使用 hash 进行元素的索引,自然它对存储的元素有可哈希的要求;而 set 使用 hash 值进行索引
正确做法:将list转成tuple,这样就可以用set去重。
# 对二维list去重:
# >>> list1=[1,1,2]
# >>>set(list1)
# {1, 2}
# >>> list2=[[2,2],[2,2]]
#
# >>> set(list2)
# Traceback (most recent call last):
# File “”, line 1, in
# TypeError: unhashable type: ‘list’
# >>> unique_list2= list(set([tuple(t) for t in list2]))
# >>> unique_list2
# [(2, 2)]
# >>>
python多维list:按特定列排序
>>> envelopes = [[5,4],[6,4],[6,7],[2,3],[8,1]]
>>>envelopes0=sorted(envelopes,key=lambda x:x[0])
>>> envelopes0
[[2, 3], [5, 4], [6, 4], [6, 7], [8, 1]]
>>>envelopes1=sorted(envelopes,key=lambda x:x[1])
>>> envelopes1
[[8, 1], [2, 3], [5, 4], [6, 4], [6, 7]]
>>> envelopes
[[5, 4], [6, 4], [6, 7], [2, 3], [8, 1]]
>>>
>>>envelopes.sort(key=lambda x:x[1])
>>> envelopes
[[8, 1], [2, 3], [5, 4], [6, 4], [6, 7]]
>>>
按第一列升序排列,若第一列值一样,则按第二列降序排列
envelopes.sort(key=lambda x: (x[0], -x[1]))
list常用方法
list常用方法:
- 比较:
python2.x:cmp(l1,l2)
python3.x:无cmp方法,若需要比较功能,需要引入operator模块,适用于任何对象。
import operator
operator.lt(a, b)
operator.le(a, b)
operator.eq(a, b)
operator.ne(a, b)
operator.ge(a, b)
operator.gt(a, b)
operator.__lt__(a, b)
operator.__le__(a, b)
operator.__eq__(a, b)
operator.__ne__(a, b)
operator.__ge__(a, b)
operator.__gt__(a, b)- 排序:
list1,sort()区别sorted(list1)- 去重:
set(list1)- 反转:
list1.reverse()- 插:
尾部追加:list1.append(obj)
特定位置index处插:list1.insert(index, obj)- 查:
查元素x的索引位置:list1.index(x [,start [,end]]),返回x第一次出现的位置
查x的出现次数:list1.count(x)- 删:
删尾:类似于弹栈操作,list1.pop()
删特定元素obj:list1.remove(obj),删第一个匹配的obj- 改:list为可变序列,可修改,
list1[i]=new_value- 其它可迭代非list强制转为list:
使用list()方法list2=list(set(sorted(list1)))
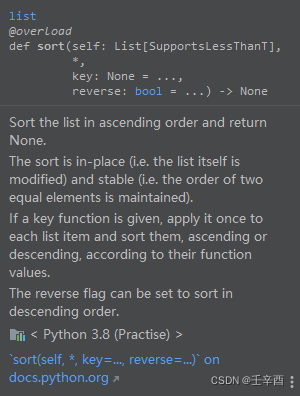
NOTE:注意区别【list的sort方法】和【python的内置方法sorted】
list_name.sort()
原地修改 列表listsorted(list_name)
返回按默认升序排序 新列表,原有列表不变。
list_name2=sorted(list_name1)
list_name2:按升序排列
list_name1:原列表保持不变
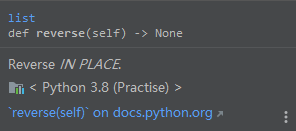
若想按降序排列:list_name2.reverse(),reverse方法 原地反转。

>>> list1=[2,1]
>>>list1.sort()
>>> list1
[1, 2]
>>>list1.reverse()
>>> list1
[2, 1]
>>>list1.append(1)
>>> list1
[2, 1, 1]
>>>set(list1)
{1, 2}
>>> list1
[2, 1, 1]
>>>list2=list(set(list1))
>>> list2
[1, 2]
>>>list1.insert(1,3)
>>> list1
[2, 3, 1, 1]
>>>list3=sorted(list1)
>>> list3
[1, 1, 2, 3]
>>> list1
[2, 3, 1, 1]
>>>list1.sort()
>>> list1
[1, 1, 2, 3]
>>>
二维数组初始化
Python中初始化一个【3行5列】每项为0的数组,最好方法是:
multilist = [[0 for col in range(5)] for row in range(3)]
or
multilist = [[0] * 5 for row in range(3)]
NOTE: 对于m行n列的二维数组
java二维数组初始化:int[][] dp = new int[m + 1][n + 1];前行后列
python二维数组初始化:dp = [[0 for col in range(n+1)] for row in range(m+1)]前列后行
我们知道,为了初始化一个一维数组,我们可以这样做:
alist = [0] * 5
没错,那我们初始化一个二维数组时,是否可以这样做呢:
>>>multi = [[0] * 5] * 3
其实,这样做是不对的,因为[0] *
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











