




 本文介绍了Python编程的基础知识,包括缩进、输入输出、字符串处理、列表操作、字典使用、函数与方法、异常处理、文件读写、模块导入、面向对象编程等。特别提到了`update()`方法用于更新字典中的键值对,`*`和`**`在函数参数中的意义,以及`__call__`方法的作用。此外,文章还探讨了元组、命名元组、列表推导式、字典的`keys()`, `values()`, `items()`方法,以及`isinstance()`、`hasattr()`等函数的用法。文章最后提及了Python中的`f-string`、文件路径处理、进程间通信、模块导入策略等高级特性。"
78785602,7413069,CLion创建多可执行文件项目教程,"['C++', 'IDE', 'CLion', 'CMake工具', '项目构建']
本文介绍了Python编程的基础知识,包括缩进、输入输出、字符串处理、列表操作、字典使用、函数与方法、异常处理、文件读写、模块导入、面向对象编程等。特别提到了`update()`方法用于更新字典中的键值对,`*`和`**`在函数参数中的意义,以及`__call__`方法的作用。此外,文章还探讨了元组、命名元组、列表推导式、字典的`keys()`, `values()`, `items()`方法,以及`isinstance()`、`hasattr()`等函数的用法。文章最后提及了Python中的`f-string`、文件路径处理、进程间通信、模块导入策略等高级特性。"
78785602,7413069,CLion创建多可执行文件项目教程,"['C++', 'IDE', 'CLion', 'CMake工具', '项目构建']
1.缩进是灵魂, if for while 都要加: 然后用缩进
2.scanf用: temp = input(‘输入你要的东西: ‘)
3.字符串
单引号 双引号 三引号都可以
只是单引号遇到字符 ’ 时候,要加转义字符 \ ,或者字符串前加 r , str = r’ ’
三引号,可以输入多行字符,自动加\n!
4.alt+3 注释 alt+4 取消注释 Pycharm注释 : CON+/ “”" “”"
5. print(name.title())以首字母大写输出
upper()以全大写, lower()以全小写.
6. 制表符 \t :print("\t")
7. 剔除空格: 字符前空格,全部空格,末尾空格:
lstrip() , strip() , rstrip()
.strip() # 去掉回车’\n’
8. ** 表示 乘方运算!a**b , a 的 b次方
9. 使用 str() , 将非字符转换字符. int ----- char
not None == not False == not ‘’ == not 0 == not [] == not {} == not () 就是有东西传
列表:
10. 列表访问,使用大括号: A = [‘1’, ‘2’] A[0] = 1
-1 访问末尾元素: A[-1] = 2
实例:
k = ‘/home/rlc/ObjectDetection-OneStageDet/yolo/utils/test/VOCdevkit/VOC2007/JPEGImages/000001.jpg’
k.split(’/’) = [’’, ‘home’, ‘rlc’, ‘ObjectDetection-OneStageDet’, ‘yolo’, ‘utils’, ‘test’, ‘VOCdevkit’, ‘VOC2007’, ‘JPEGImages’, ‘000001.jpg’]
name = k.split(’/’)[-1][:-4] = ‘000001’
[-1]表列表最后一个元素,[:-4]表示从0到倒数第四个为止
我十分确定,即使在torch.Tensor中 -1也表示倒数第一个元素
-
append() , 有两个作用:给列表末尾加新的元素;
动态创建列表!!!这很重要!!!!!动态创建列表!!!这很重要!!!!!
motorbycle.append(‘honda’) 先创建一个默认列表 motorbycle = [ ]
列表合并–“+”, 效果与extend()相同,也可用于列表的合并。A = [1] , B = [2], A+B = [1, 2]a = [1, 2, 3]
b = [5, 6, 7]
print(a+b) [1, 2, 3, 5, 6, 7]
列表元素复制的方法:
1.在python中, 如果用一个列表list1乘一个数字n 会得到一个新的列表list2, 这个列表的元素是list1的元素重复n次
num_2 = [1, 2, 3] copy_num_2 = num_2 * 3 # 列表乘数字,将列表元素复制三次 print(copy_num_2) 输出:[1, 2, 3, 1, 2, 3, 1, 2, 3]2.没见过的,for循环创建列表: 列表解析!!!!!!
num = 24 copy_num = [num for x in range(10)] # 创建列表,for循环创建num数字 print(copy_num) 输出:[24, 24, 24, 24, 24, 24, 24, 24, 24, 24]
-
motorbycle.insert(0,‘AAA’) 在 motorbycle 的 0位置插入AAA
del motorbycle[0] 删除 0 位置的元素 -
pop 栈 弹出末尾元素,并使用 motorbycle.pop() ; motorbycle.pop(1)
-
这个厉害了!!!!
根据值删除元素: remove() -
排序: sort() 永久性排序 motorbycle.sort() , sorted(AA)临时排序
关键词参数key,结合lambda隐函数;x表示列表中的一个元素,x只是临时起的一个名字,你可以使用任意的名字;x[0]表示元组里的第一个元素,当然第二个元素就是x[1];所以这句命令的意思就是按照列表中第一个元素排序
我遇到的代码:sorted(glob.glob(os.path.join(video_dir, "img/*.jpg")), key=lambda x: int(os.path.basename(x).split('.')[0])) # os.path.basename(x).split('.')[0]获得路径最后 . 前面的字符进行比较

–
os.path.dirname(path)
语法:os.path.dirname(path)
功能:去掉文件名,返回目录
如:
print(os.path.dirname("E:/Read_File/read_yaml.py"))
#结果:
E:/Read_File
结合:
os.path.realpath(file) 获取当前脚本完整路径
使用更方便
- reverse() 倒序! motorbycle.reverse() 永久倒叙!!!
for 循环列表访问: for M in motorbycle:
print(M) #打印 motorbycle的所有项目
range(1,5)生成数字 1-4: for N in range:
print(N) #打印1-4
range配合 list() 生成数字列表: num = list(range(1,5,2)) 2为步长
print(num)
平方打印: num = []
for VA in range(1,11):
num.append(VA**2)
print(num)
生成数字列表最简单的方式:
num = [VA**3 for VA in range(1,19)]
print(num)
- 切片 , 不输入起始索引 ,或者结束索引。就表示默认从起始位置开始, 或者 到末尾地址。 print(A[1:5]) , 第二个地址是索引到 4 ,这样与 range 相同。
打印倒数几个切片 print(A[-3:]) 加负号 打印!
19.复制列表 , 指明起始结束地址, 可以建立独立的两个列表A ,B A=B[:] 全复制!
A=B , 那么 A 和 B 共同分享同一个内存地址
- 列表 [ ] 可修改 ; 元组 ( ) 不可修改 !!!但是访问还是 : A[2] 用大括号访问元组
- Python
注意else if 写成 elif ; 并且 并不需要 else: 来结尾。
if-elif-else 结构
age = int(input('输入你的年纪: '))
##age = int(age)
if age >= 18 & age <= 60:
print("你已经成你年了!!!")
elif age <18:
print("你还是个小朋友!!")
else:
print('老头子!!')
- in 访问多个列表
AA = ['QW','AS','ZX','RT']
BB = ['JK','QW','FG','EH']
for ip in AA:
if ip in BB: #访问多个列表,在if中 in 列表
print('WE HAVE ' + ip)
else:
print('WE DONT HAVE ' + ip)
print('FINASH')
字典 用 大括号 {} : alien = {‘color’ : 'green ’ , ‘age’ : 15} 访问方法 alien[‘color’]
字典是一系列的 键 值 对 , 值 可以是 ‘数字 字符串 字典 等 任何对象’
update() 方法用于更新字典中的键/值对,可以修改存在的键对应的值,也可以添加新的键/值对到字典中。
字典可以直接复制:字典copy()方法,dict.copy()
https://blog.youkuaiyun.com/LeonTom/article/details/82761319
boxes = self.roidb[i]['boxes'].copy() # 列表roidb[i]每一个元素图片i都是一个字典,键['boxes'],copy他的值
alien = {'color' : 'green ' , 'age' : 15}
print('This is a ' + alien['color'] + ' ,Age is ' + str(alien['age']))
alien['OL'] = 'office lady' #添加字典 , 可以创建一个空字典 慢慢这样添加!
print(alien)
del alien['age'] #和列表一样, del删除元素
print(alien)
24.遍历 字典 方法 items() 包含 ‘ 键 和 值 ’ ; keys() 输出键 ; values() 输出值
con = {'CHINA':'ASIA','ENGLAND':'EU','USA':'AME'}
for I,P in con.items():
print(I + ' is ' + P)
for I in con.keys(): # keys() 就是 输出 键 , 其实默认就是输出键
print(I)
for P in con.values(): # values() 就是输出 所有的 值
print(P)
IM!!!: Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
dict.get(key, default=None)
#key -- 字典中要查找的键。
#default -- 如果指定键的值不存在时,返回该默认值
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 27}
print "Value : %s" % dict.get('Age')
print "Value : %s" % dict.get('Sex', "Never")
以上实例输出结果为:
Value : 27
Value : Never
easydict的作用:可以使得以属性的方式去访问字典的值!
>>> from easydict import EasyDict as edict >>> d = edict({'foo':3, 'bar':{'x':1, 'y':2}}) >>> d.foo 3 >>> d.bar.x 1 >>> d = edict(foo=3) >>> d.foo 3 ```
- 不仅字典可以嵌套字典 列表也可以嵌套字典:还可以 字典存放列表
alll = []
for i in range(30):
new_all = {'color':'red', 'num':i}
alll.append(new_all)
print(alll[:7]) 注意列表默认访问 , 和 matlab一样 [ : 7] 0-6
python中的字典是无序的,因为它是按照hash来存储的,但是python中有个模块collections(英文,收集、集合),里面自带了一个子类OrderedDict,实现了对字典对象中元素的排序。
用OrderedDict会根据放入元素的先后顺序进行排序。所以输出的值是排好序的,OrderedDict对象的字典对象,如果其顺序不同那么Python也会把他们当做是两个不同的对象print 'Regular dictionary:' d2={} d2['a']='A' d2['b']='B' d2['c']='C' d3={} d3['c']='C' d3['a']='A' d3['b']='B' print d2 == d3 import collections print '\nOrderedDict:' d4=collections.OrderedDict() d4['a']='A' d4['b']='B' d4['c']='C' d5=collections.OrderedDict() d5['c']='C' d5['a']='A' d5['b']='B' print d1==d2 输出: Regular dictionary: True OrderedDict: False
- while 循环 使用 True ,Flase 的情况 !! while 条件 必须是 True 否则无法循环!!!
tll = '我们要获取你的名字!!'
tll += '\n你可以自己告诉我们'
flag = True
name = input(tll + ': ')
while flag: #这里一定是 True
name = input(tll + ': ')
if name == 'HJ':
flag = False
else:
print('Wrong Input: ' + name)
- 列表作为循环条件 !!
unconf = ['RLC', 'HJ', 'HYL', 'HXY', 'HXJ']
conf = []
while unconf: #通过 while 列表名 , 以列表非空为循环条件 pop 出元素
current = unconf.pop()
print('Check User : ' + current)
conf.append(current)
print('Confirmed User : ')
for op in sorted(conf):
print(op.lower())
- #列表某元素存在性 作为 循环条件
unconf = ['RLC', 'HJ', 'HYL', 'HXY', 'HXJ', 'MJ']
print(unconf)
while 'MJ' in unconf : #列表某元素存在性 作为 循环条件
unconf.remove('MJ')
print(unconf)
def lover(male, female):
print(male + ' LOVE ' + female)
lover('RLC', 'HJ')
lover(female = 'HJ', male = 'RLC') #指定实参 , 那么形参顺序就无所谓
- 默认形参
def lover(male, female = 'HJ'):
print(male + ' LOVE ' + female)
lover('AA') #默认形参,不用在指定female
lover(male = 'AA', female='BB')#重新指定默认形参
lover( 'AA', 'BB')#重新指定默认形参
#让形参变得可选!
def get_name(firename, lasname, midename = ''): #为可选形参指定空字符串
if midename: #python默认为 True !
full_name = firename + ' ' + midename + ' ' + lasname
else:
full_name = firename + ' ' + lasname
return full_name.title()
mus = get_name('PB', 'KL', 'NM')
print(mus)
mus = get_name('PB', 'NM')
print(mus)
32.函数可以返回字典
def build_person(fname, lname, age=''):
person = {'first':fname, 'last':lname}
if age:
person['age'] = age
return person
mus = build_person('ren', 'licheng', 17)
print(mus)
- Python 强大啊! 可以直接给函数传递列表!! 列表可以包含字典。
def greet(names):
for name in names:
print('Hellow ' + name.title() + ' ,gogogogo!')
uses = ['HJ', 'HXY', 'HYL', 'RLC', 'KL']
greet(uses)
34.两点: 首先python 函数要写在前面 才能调用 因为没有main 。 其次 如果使用pop 但是不想修改列表
就需要 禁止函数修改列表 调用函数时,使用切片
def ppll(AA):
while AA:
co = AA.pop()
print(co)
AAr = [1, 2, 3, 4, 5, 3]
ppll(AAr[:]) # 这里使用切片 禁止修改列表
print(AAr)
- 当不知道有多少个 实参 的时候 , 可以使用 * 来创建元组形参 , 存储任意个实参
def pip(*top): # * 创建元组!
print(top)
pip('a', 'b', 'c')
pip(1, 2, 3, 4)
补充:
https://blog.youkuaiyun.com/wangjvv/article/details/7970350
def call(self, *input, **kwargs):
形参带*与带**的意义:
* : 可以理解为给这个方法定义多个同类的形参,在使用时,带一个*号的在方法中会被存储为元组!即输入多个数据,按照元祖存储!
** :在调用时应写为 (a=2,b=3,c=4)输出结果为 {‘a’:2,‘b’:3,‘c’:4},即输出按照字典!
- 向函数传递 字典 的 键值对
在 *元组 和 **字典 的时候, 确定性形参要写在 未知数量 形参前面, 输入的时候, 先满足确定性参数, 剩余的都是 未知数了实参
# 两个星星 ** 的方式 , 向函数插入 字典的 键——值 对
def pri(fname, lname, **infom): # **infom可以引入 输入的的键值对
profile = {}
profile['first_name'] = fname
profile['last_name'] = lname
for ifoma, infomb in infom.items():
profile[ifoma] = infomb
print(profile)
pri('ren', 'li cheng', school='UCAS', old=24) #注意 形参怎么写, school='UCAS', old=24
- 就函数保存为模块存储在独立文件中,然后要使用时导入主程序。
程序一:函数模块,保存为 pizza.y
def make_pizza(size, *topp):
print('\nmake a ' + str(size) + 'following pizza: ')
for pia in topp:
print(topp)
程序二:主程序模块,调用函数
import pizza
pizza.make_pizza(16, 'AA')
pizza.make_pizza(12, 'ZZ', 'XX', 'CC')
135页 : 导入特定的函数, 给函数指定新名字, 给模块指定新名字
- 编写表示现实世界中的事物和情景的类,并基于这些类来创建对象。根据类来创建对象被称为实例化。使用类可以模拟任何东西。类包含对象的特征信息。
1)类中的函数被称为方法, -init-()是一个特殊的方法,一种约定,避免Python默认方法和普通方法发生命名冲突
形参 self 必不可少 , self会自动传递 , 不需要传递他 , 只需要传递 后面两个形参
2)以 self 为前缀的 变量 , 可以在 类中的 所有方法 中 使用,称为属性
3)我们通过实参向 Dog() 传递名字和年龄 , self 与 实例化以后的名字对应!!!!
class Dog(): # self 与 实例化以后的名字对应!!!!
"""一次模拟小狗的简单尝试 """
def __init__(self, name, age):
"""初始化属性name和age"""
self.name = name
self.age = age
def sit(self):
"""模拟小狗被命令时蹲下"""
print(self.name.title() + " is now sitting. ")
def roll_over(self):
"""模拟小狗被命令时打滚"""
print(self.name.title() + " rolled over:")
my_dog = Dog('Willie', 6) # my_dog 实例 , 传递给方法 -init-
print('My dog\'s name is ' + my_dog.name.title() + '.')
print("My dog is " + str(my_dog.age) + " years old")
your_dog = Dog('Xiao mei', 3) #创建多个实例 , 与 类 的 self 相同使用法
print('\nYour dog\'s name is ' + your_dog.name.title() + '.')
print("Your dog is " + str(your_dog.age) + " years old")
your_dog.sit()
your_dog.roll_over()
4)方法 -init-() 创建一个表示特定小狗的示例, 并使用我们提供的值来 设置属性 name 和 age 。
5) -init-() 并未显式 地 包含 return 语句 , 但 Python 自动返回一个表示这条小狗的实例,我们将这个实例存储在变量 my_dog 中
6)命名约定: 首字母大写 Dog 表示 类 , 小写 my_dog 表示实例
7) \def call__()的作用是使实例能够像函数一样被调用,同时不影响实例本身的生命周期(call()不影响一个实例的构造和析构)。但是__call()可以用来改变实例的内部成员的值。不使用.调用实例的方法,那么就是__call__了
- 类 中的 方法 返回值 return 使用
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self, make, model, year):
"""初始化描述汽车信息"""
self.make = make
self.model = model
self.year = year
def get_inform(self):
"""返回整洁的描述性信息"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title() # 方法 返回值 使用
my_new_car = Car('audi', 'a4', 2018)
print(my_new_car.model)
print('\n' + my_new_car.get_inform()) #调用 方法 的 返回值
- 书 145 页 , 修改 类 中属性的值 的三种方法
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self, make, model, year):
"""初始化描述汽车信息"""
self.make = make
self.model = model
self.year = year
self.lucheng = 0
def get_inform(self):
"""返回整洁的描述性信息"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_lc(self):
"""打印一条指出汽车里程的消息"""
print('This car has ' + str(self.lucheng) + ' on it')
def updata_lucheng(self, miles):
"""将里程表设置为指定的值"""
self.lucheng += miles
my_new_car = Car('audi', 'a4', 2018)
print(my_new_car.model)
print('\n' + my_new_car.get_inform())
my_new_car.lucheng = 23 # 法一 , 直接修改属性的值, 用实例 点方法 去修改
my_new_car.read_lc()
my_new_car.updata_lucheng(50) #法二 , 通过方法修改属性的值 , 然后实例化调用 , self.lucheng = miles
my_new_car.read_lc()
my_new_car.updata_lucheng(50) #法三 , 通过方法递增属性的值 , 然后实例化调用 , self.lucheng += miles
my_new_car.read_lc()
- 继承, 一个类继承另一个类 , 子类 继承 其父类的所有属性和方法 , 同时 还可以定义自己的属性和方法 。 子类,必须在括号内指定 父类的名称
重点是:super() 是一个特殊函数,帮助父类和子类关联起来。这行代码让python调用Electric的父类方法-init-() , 让Electric实例包含父类的所有属性。父类也称 超类(superclass) , 名称super因此得名。
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self, make, model, year):
"""初始化描述汽车信息"""
self.make = make
self.model = model
self.year = year
self.lucheng = 0
def get_inform(self):
"""返回整洁的描述性信息"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_lc(self):
"""打印一条指出汽车里程的消息"""
print('This car has ' + str(self.lucheng) + ' on it')
def updata_lucheng(self, miles):
"""将里程表设置为指定的值"""
self.lucheng += miles
class Electric(Car): # 子类,必须在括号内指定 父类的名称
"""电动车的独到之处"""
def __init__(self, make, model, year):
"""初始化父类的属性"""
super().__init__(make, model, year)
# 或者写作super(Car, self).__init__()
my_tesla = Electric('tesla', 'model s', 2018)
print(my_tesla.get_inform())
- 给子类 添加新的 方 法 和 属 性
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self, make, model, year):
"""初始化描述汽车信息"""
self.make = make
self.model = model
self.year = year
self.lucheng = 0
def get_inform(self):
"""返回整洁的描述性信息"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_lc(self):
"""打印一条指出汽车里程的消息"""
print('This car has ' + str(self.lucheng) + ' on it')
def updata_lucheng(self, miles):
"""将里程表设置为指定的值"""
self.lucheng += miles
class Electric(Car):
"""电动车的独到之处"""
def __init__(self, make, model, year):
"""初始化父类的属性"""
"""然后添加新的 属性 和 方法"""
super().__init__(make, model, year)
self.battery_size = 90 # 新的属性
def describe_battery(self): # 新的方法
"""打印一条描述电瓶容量/"""
print("This car has a " + str(self.battery_size) + "-kWh battery")
my_tesla = Electric('tesla', 'model s', 2018)
print('\n' + my_tesla.get_inform())
my_tesla.describe_battery()
- 将实例用作属性:给类添加的细节越来越多,可能需要将类的一部分作为一个独立的类提取出来。你可以将大型类拆分为多个协同工作的小类。
类 中 调用 类!
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self, make, model, year):
"""初始化描述汽车信息"""
self.make = make
self.model = model
self.year = year
self.lucheng = 0
def get_inform(self):
"""返回整洁的描述性信息"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_lc(self):
"""打印一条指出汽车里程的消息"""
print('This car has ' + str(self.lucheng) + ' on it')
def updata_lucheng(self, miles):
"""将里程表设置为指定的值"""
self.lucheng += miles
class Battery(): # 定义一个电池容量 类 , 拆分原来大型 类 ! 默认形参 70
"""一次模拟电动汽车电瓶的简单尝试"""
def __init__(self, battery_size=70): # 默认形参70
"""初始化电瓶的属性"""
self.battery_size = battery_size
def describ_battery(self):
print("This car has a " + str(self.battery_size) + "-kWh battery.")
class Electric(Car):
"""电动车的独到之处"""
def __init__(self, make, model, year):
"""初始化父类的属性"""
"""然后添加新的 属性 和 方法"""
super().__init__(make, model, year)
self.battery = Battery() # 调用 类 Battery() , 默认形参 70
def describe_battery(self):
"""打印一条描述电瓶容量"""
self.battery.describ_battery() # 这一句, 很重要, 他是怎么调用方法, 实现打印的
my_tesla = Electric('tesla', 'model s', 2018)
print('\n' + my_tesla.get_inform())
my_tesla.describe_battery()
- 将 类 存储为模块, 在 主程序 中导入。 和 导入 函数 一样的道理!
158页 , 模块中导入模块
from car import Car, Electric # 从一个模块 导入 多个类 ,也可以 import car
my_beetle = Car('volkswagen', 'beetle', 2018)
print(my_beetle.get_inform())
my_tesla = Electric('tesla', 'roadstar', 2016)
print(my_tesla.get_inform())
类名字首字母大写,模块和实例小写并且单词之间加下划线
45.第一个 文件读取程序 ,163页, open() 打开文件, 打开文件的名称。
open以后, 在当前目录寻找 指定文件 ; close( ) 关闭文件。
重要:关闭文件,让Python 去确定,他会自己选择合适的时机自动将其关闭。
.read() 将文件读取出来。
with open('pi_digits.txt') as file_object:
contents = file_object.read()
print(contents)
- 使用 文件路径 打开文件 , 绝对路径。注意 OPEN( ) 里面的应该是字符串 ‘ ’
file_path = 'F:\python\LICENSE.txt' # 绝对路径, 可以打开任意文件中的文件
with open(file_path) as file_object:
contents = file_object.read()
print(contents.rstrip())
- 除了 read( ) 读取文件以外, 还可以 逐行读取
记住:字符串,会在末尾自动加一个换行符 \n
file_path = 'pi_digits.txt'
with open(file_path) as file_object:
for line in file_object: # 逐行读取!!
print(line.rstrip())
- .readlines( ) 从文件中读取每一行, 并将他存储在一个列表中!
file_path = 'F:\python\LICENSE.txt'
with open(file_path) as file_object:
lines = file_object.readlines() # 读取每一行, 并存储在列表中
for line in lines:
print(line.rstrip())
- 空字符串
file_path = 'pi_digits.txt'
with open(file_path) as file_object:
lines = file_object.readlines()
pi = '' #空字符串
for line in lines:
pi += line.strip()
print(pi[:10]) #只打印前十行
print(len(pi))
- 写入空文件!!
重点:Python 只能 将 字符串写入 文本文件 。 要将数值数据存储到文本文件中,必须先 str()
filename = 'programming.txt'
with open(filename,'w') as file_object: #注意这一行,'w'
file_object.write("I love my self!")
w 代表 write!
a 代表 attach ,附加在之前文件后面!
open(filename, ‘a’)
- try-except 代码块
告诉程序 , 代码可能 会错 但是坚持运行
173页 ,如何处理异常。
try:
print(5/0)
except ZeroDivisionError:
print("CCCC")
- json , 存储数据 , json是一种数据格式
python善于使用这种方式存储数据
- json.dump 存储数据
import json
numbers = [2, 3, 5, 7, 11, 13]
filename = 'num.json'
with open(filename, 'w') as f_obj:
json.dump(numbers,f_obj) # dump , 存储数据 , 将 number 存储到 f_obj 。
2) json.load 读取数据
import json
filename = 'num.json'
with open(filename) as f_obj:
numbers = json.load(f_obj) # load 读取 json 数据 , 数据格式 就是 json
print(numbers)
- . 书 188 页 , Python标准库中的 unittest 提供了代码测试工具!书 188 页 , Python标准库中的 unittest 提供了代码测试工具!
测试 函数 类 添加的程序
54.使用 \ 来换行表示
cross_entorpy = \
tf.reduce_mean(-tf.reduce_sum(y_* tf.log(y)))
# 指定随机种子seed(N),使得不同执行操作N相同时,随机数相同 from numpy.random import seed seed(10) # 指定随机数种子 from tensorflow import set_random_seed set_random_seed(20)
random.randint(0, 100) 整数随机
56.python使用zip时出现 zip object at 0x02A9E418
https://blog.youkuaiyun.com/oMoDao1/article/details/82150972
57.lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
lambda所表示的匿名函数的内容应该是很简单的,如果复杂的话,干脆就重新定义一个函数了,使用lambda就有点过于执拗了。
lambda就是用来定义一个匿名函数的,如果还要给他绑定一个名字的话,就会显得有点画蛇添足,通常是直接使用lambda函数。如下所示:
add = lambda x, y : x+y
add(1,2) # 结果为3
58.namedtuple()
namedtuple主要用来产生可以使用名称来访问元素的数据对象,通常用来增强代码的可读性, 在访问一些tuple类型的数据时尤其好用。
namedtuple由自己的类工厂namedtuple()进行创建,而不是由表中的元组进行初始化,通过namedtuple创建类的参数包括类名称和一个包含元素名称的字符串
from collections import namedtuple
p = namedtuple("person", "name,age,sex")
print (type(p))
zhanglin = p("zhanglin",30,"male")
print(zhanglin)
print(zhanglin.name,zhanglin.age)
59.python 加法广播机制,自动扩展矩阵
https://www.jianshu.com/p/fadd169cd396
60. 使用enumerate对列表和元组进行操作时,同时返回元素的索引和元素的值。
61.
x1 = d.top() if d.top() > 0 else 0 # if可以这样判断
labs = np.array([[0,1] if lab == my_faces_path else [1,0] for lab in labs])
- OS模块
os.walk(path)返回三个值:parent,dirnames,filenames,分别表示path的路径、path路径下的文件夹的名字和path路径下文件夹以外的其他文件Debug一下Facedection文件就懂了| |
os.path.join(FLAGS.output_directory, output_filename) # 路径拼接,两个字符拼接在一起
分离文件名与扩展名os.path.splitext(“文件路径”)
os.path.splitext(“文件路径”) 分离文件名与扩展名;默认返回(fname,fextension)元组,可做分片操作
os.path.splitext(‘weights/yolov2_60200.dw’)
<class ‘tuple’>: (‘weights/yolov2_60200’, ‘.dw’)
os.path.basename()作用
返回path最后的文件名。若path以/或\结尾,那么就会返回空值。
eg:
path='D:\优快云'
os.path.basename(path)
‘优快云’
os.path.basename('c:\test.csv')
'test.csv'
os.path.basename('c:\csv')
'csv' (这里csv被当作文件名处理了)
os.path.basename('c:\csv\')
''
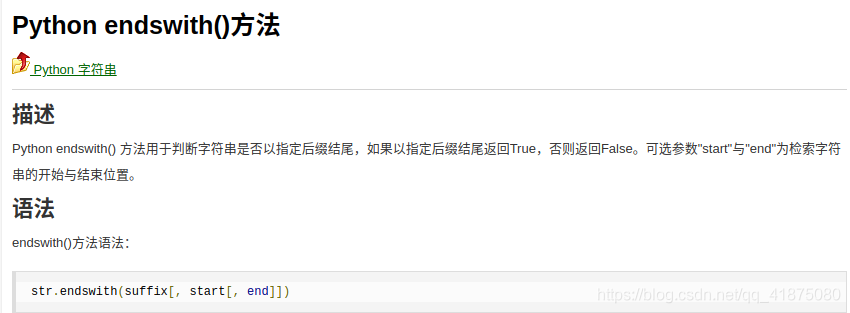
Python中startswith和endswith的用法
描述
Python endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数”start”与”end”为检索字符串的开始与结束位置。
语法
endswith()方法语法:
str.endswith(suffix[, start[, end]])
参数
suffix – 该参数可以是一个字符串或者是一个元素。
start – 字符串中的开始位置。
end – 字符中结束位置。
返回值
如果字符串含有指定的后缀返回True,否则返回False。
实例
if filename.endswith('.jpg'): # 字符串end,starwith的用法
print('Being processed picture %s' % index)
img_path = path+'/'+filename
64.顺便复习一下相对路径和绝对路径的概念
绝对路径就是文件的真正存在的路径,是指从硬盘的根目录(盘符)开始,进行一级级目录指向文件。
相对路径就是以当前文件为基准进行一级级目录指向被引用的资源文件。
以下是常用的表示当前目录和当前目录的父级目录的标识符
../ 表示当前文件所在的目录的上一级目录
./ 表示当前文件所在的目录(可以省略)
/ 表示当前站点的根目录(域名映射的硬盘目录)
img.shape[:2] 取彩色图片的长、宽。
如果img.shape[:3] 取彩色图片的长、宽、通道。
关于img.shape[0]、[1]、[2]
img.shape[0]:图像的垂直尺寸(高度)
img.shape[1]:图像的水平尺寸(宽度)
img.shape[2]:图像的通道数
66.python可以直接给函数传递列表、元组、字典,因为可以直接传递数组,他们三就是三种数组
def weightVariable(shape):
init = tf.random_normal(shape, stddev=0.01) # 随机正态分布
return tf.Variable(init)
W1 = weightVariable([3, 3, 3, 32])
67.assert使用,不满足就报错,无法执行
assert语句用来声明某个条件是真的
线程与文件数相对应(倍数相等),否则报错,无法执行,not可选
assert not FLAGS.train_shards % FLAGS.num_threads, ( '在测试集中:线程数量应用建立文件个数想对应')
68.glob方法:
glob模块的主要方法就是glob,该方法返回所有匹配的文件路径列表(list);该方法需要一个参数用来制定匹配的路径字符串(字符串可以为绝对路径也可以为相对路径),其返回文件名只包括当前目录里的文件名,不包括子文件夹里的文件。
比如:
import glob
glob.glob('*.txt') #这里就是获取此文件的路径下所有的txt文件并返回一个list。如QQ.txt、44.txt
glob.glob('glob_?.png') #这里就是获取路径下所有的 glob_().png文件并返回一个list,如:glob_1.png\glob_q.png
glob.glob('glob_[0-9].png') #这里就是获取次路径下下划线后面数字是-0-9的文件并返回为一个list
glob.glob('glob_[0-9].*') #这里就是获取路径下所有文件名为glob_(0-9范围内)的所有文件
通配符* , ? :第一个是多字符,第二个单字符
glob提取的文件是打乱了原始排列顺序的lisi!所以要求顺序时需要排序!
69.
# 随机打乱,注意对列表进行洗牌的快速操作
shuffled_index = list(range(len(filenames))) # 数字label都连在一起,不利于训练,打乱
random.seed(12345) # 随机数种子。每次随机数都是一样的
random.shuffle(shuffled_index) # 洗牌
# 全部进行重新排列,重点是快速洗牌的方法
filenames = [filenames[i] for i in shuffled_index]
texts = [texts[i] for i in shuffled_index]
labels = [labels[i] for i in shuffled_index]
70.强制刷新缓冲区 sys.stdout.flush()
缓冲区的刷新方式:
1.flush()刷新缓存区
2.缓冲区满时,自动刷新
3.文件关闭或者是程序结束自动刷新。
当我们打印一些字符时,并不是调用print函数后就立即打印的。一般会先将字符送到缓冲区,然后再打印。这就存在一个问题,如果你想等时间间隔的打印一些字符,但由于缓冲区没满,不会打印。就需要采取一些手段。如每次打印后强行刷新缓冲区。
for i in range(n):
print " * ",
sys.stdout.flush() #刷新缓冲区
time.sleep(1)
-
输出字符占几个位置
%.5d
A = 1
print(’%.5d’ % A) # 小数点后五位
00001
print(’%5d’ % A) # 小数点前五位
1
print(’%d’ % A)
1
print(’%-5d’ % A) # 小数点前5位,A做开头
1
print(’%-5d%d’ % (A, A)) # 方便你观察%-5d一共占五个字符
1 1
其他格式化字符:https://blog.youkuaiyun.com/huangfu77/article/details/54807835
72.Python文件读写的几种模式:
r,rb,w,wb 那么在读写文件时,有无b标识的的主要区别在哪里呢?
https://www.cnblogs.com/nulige/p/6128948.html
73.
argarse.ArgumentParser.parse_known_args()解析
import argparse # 这个包用来我们控制参数的,用于解析命令行选项和参数的标准模块。
import sys
parse=argparse.ArgumentParser()
# 如果没有default默认值,就需要使用args = parser.parse_args(sys.argv[1:])的方式传递
parse.add_argument("--learning_rate",type=float,default=0.01,help="initial learining rate")
parse.add_argument("--max_steps",type=int,default=2000,help="max")
parse.add_argument("--hidden1",type=int,default=100,help="hidden1")
# 解析参数,FLAGS是namespace所有参数,包含程序定义了的命令行参数;unparsed为程序没有定义的命令行参数列表
flags,unparsed=parse.parse_known_args(sys.argv[1:])
print flags.learning_rate
print flags.max_steps
print flags.hidden1
print unparsed
运行 python test.py --learning_rate 20 --max_steps 10 --hidden1 100 --arg_int 2 这是未定义参数,从sys.argv[1:]开始
其效果等同于python test.py --learning_rate=20 --max_steps=10 --hidden1=100 --arg_int=2
输出:
20.0
10
100
['--arg_int', '2']
flags为namespace空间,结果是Namespace(hidden1=100, learning_rate=20.0, max_steps=10),包含程序定义了的命令行参数,而unparsed为程序没有定义的命令行参数
tf.app.run(argv=[sys.argv[0]] + unparsed) # 直接执行参数,进入main函数, tf.app.run相当于main(),将“sys.argv[0]表示代码本身文件路径按照列表传递给主函数
列表合并–“+”, 效果与extend()相同,也可用于列表的合并。A = [1] , B = [2], A+B = [1, 2]
74.
python split()函数介绍
表示为分隔符,默认为空格,但是不能为空(’’),或者按照特定字符 ‘+’ 如加号分割
若字符串中没有分隔符,则把整个字符串作为列表的一个元 https://www.cnblogs.com/yyxayz/p/4034299.html
https://www.jb51.net/article/135377.htm
zip(a,b),zip()函数分别从a和b依次各取出一个元素组成元组,再将依次组成的元组组合成一个新的迭代器–新的zip类型数据
list(zip(self.classes, list(range(self.num_classes))))
class:zip , 加了list后 class:list
Python中eval()函数的功能及使用方法:
https://blog.youkuaiyun.com/ChowYoungyoung/article/details/78879926
将字符串str当成有效的表达式来求值并返回计算结果
eval(str)函数是将str去掉双引号后把str当做表达式来执行
这里可能会发生数据类型的转换,
例如eval(“123”),去掉双引号后,函数返回的结果变成了数值型
eval函数,eval去除引号后会检查到它是不是可计算的,如果可计算会将计算的结果打印出来,如果不可计算直接返回结果
https://www.jianshu.com/p/b8da66952291
如:
'''字符串str当成有效的表达式来求值并返回计算结果,去掉引号以后计算(不能计算直接返回结果),然后按照合适格式输出
这里的结果是,去掉引号:self.gt_roidb , 调用属性。method = 'gt' '''
method = eval('self.' + method + '_roidb')
f-string,拼接字符
f-string,学名叫作 “Literal String Interpolation”。用法如下:
>>>defupper(s):
... returns.upper()
...
>>>stock= 'tsmc'
>>>close= 217.5
>>>f'{stock} price: {close}'
'tsmc price: 217.5'
空格也是一个字符
還可以這樣:
>>>f'{upper(stock)} price: {close}'
'TSMC price: 217.5'
>>>
dict 属性用于查看对象内部存储的所有属性名和属性值组成的字典,通常程序直接使用该属性即可。
程序使用 dict 属性既可查看对象的所有内部状态,也可通过字典语法来访问或修改指定属性的值。例如如下程序:
纯文本复制
class Item:
def __init__ (self, name, price):
self.name = name
self.price = price
im = Item('鼠标', 28.9)
print(im.__dict__) # ①
# 通过__dict__访问name属性
print(im.__dict__['name'])
# 通过__dict__访问price属性
print(im.__dict__['price'])
# 通过__dict__修改属性
im.__dict__['name'] = '键盘'
im.__dict__['price'] = 32.8
print(im.name) # 键盘
print(im.price) # 32.8
上面程序中 ① 号代码直接输出对象的 dict 属性,这样将会直接输出该对象内部存储的所有属性名和属性值组成的 dict 对象;接下来的两行代码通过 dict 属性访问对象的 name、 price 两个属性;再后边两行代码通过 dict 属性对 name、 price 两个属性赋值。
运行上面程序,可以看到如下输出结果:
{'name': '鼠标', 'price': 28.9}
鼠标
28.9
键盘
32.8
Yolo一个复杂情况:
56行: net = models.__dict__[model_name](hyper_params.classes, weights, train_flag=2, test_args=test_args)
将model文件下的所有 .py 文件都进行操作
将.py作为key,然后把所有.py里面的class作为key
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
以下是 isinstance() 方法的语法:
isinstance(object, classinfo)
object – 实例对象。
classinfo – 可以是直接或间接类名、基本类型或者由它们组成的元组
返回值
如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。
判断object是不是类别classinfo
>>>a = 2
>>> isinstance (a,int)
True
>>> isinstance (a,str)
False
>>> isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
python中的and和or
在python里面,0、’’、[]、()、{}、None为假,其它任何东西都为真。ok,在此前提下
https://blog.youkuaiyun.com/qq_17550379/article/details/78173227
Python hasattr() 函数
hasattr() 函数用于判断对象是否包含对应的属性。
hasattr 语法:
hasattr(object, name)
参数
object – 对象。
name – 字符串,属性名。
返回值
如果对象有该属性返回 True,否则返回 False。
if hasattr(self.loss, 'seen'): # hasattr() 函数用于判断对象是否包含对应的属性。
self.loss.seen = self.seen
很简单,判断类self.loss中有没有属性seen,没有的话就赋予!
- /是精确除法,//是向下取整除法,%是求模
- %求模是基于向下取整除法规则的
- 四舍五入取整round, 向零取整int, 向下和向上取整函数math.floor, math.ceil
- //和math.floor在CPython中的不同
- /在python 2 中是向下取整运算
- C中%是向零取整求模。
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9] 如果希望把list的每个元素都作平方,就可以用map()函数:
因此,我们只需要传入函数f(x)=xx,就可以利用map()函数完成这个计算:
def f(x):
return xx
print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
输出结果: [1, 4, 9, 10, 25, 36, 49, 64, 81]注意:map()函数不改变原有的 list,而是返回一个新的 list。
且:如果函数f有两个参数—F(x, y),那么就需要两个列表一起传入!map(F, list1, list2)
ids.extend(map(str.strip,str.strip))
'''
使用函数str.strip去除list:str.strip所有的回车
'''
map( )接收的函数 f 有两个参数时,必须加list:(干脆都加!)
def amulb(x, y):
return x * y
a = [1, 2, 3, 4]
b = [6, 7, 8, 9]
# 必须加上list.不知道为什么!不然结果为:<map object at 0x7f8306a45240>
print(list(map(amulb, a, b)))
# print: [6, 14, 24, 36]
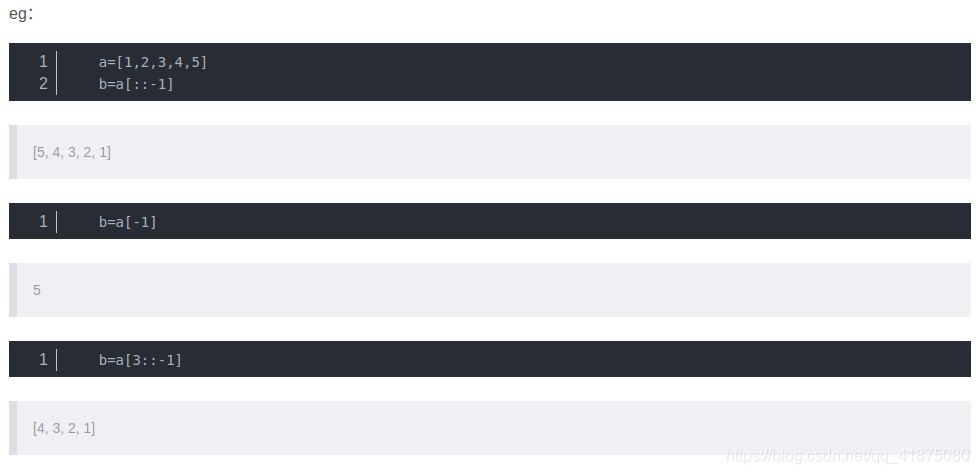
python[::-1]和[-1]用法:
[::-1] 顺序相反操作
[-1] 读取倒数第一个元素
[3::-1] 从下标为3(从0开始)的元素开始翻转读取
同样适用于字符串
85.
sys.exit(main()) 主函数定义
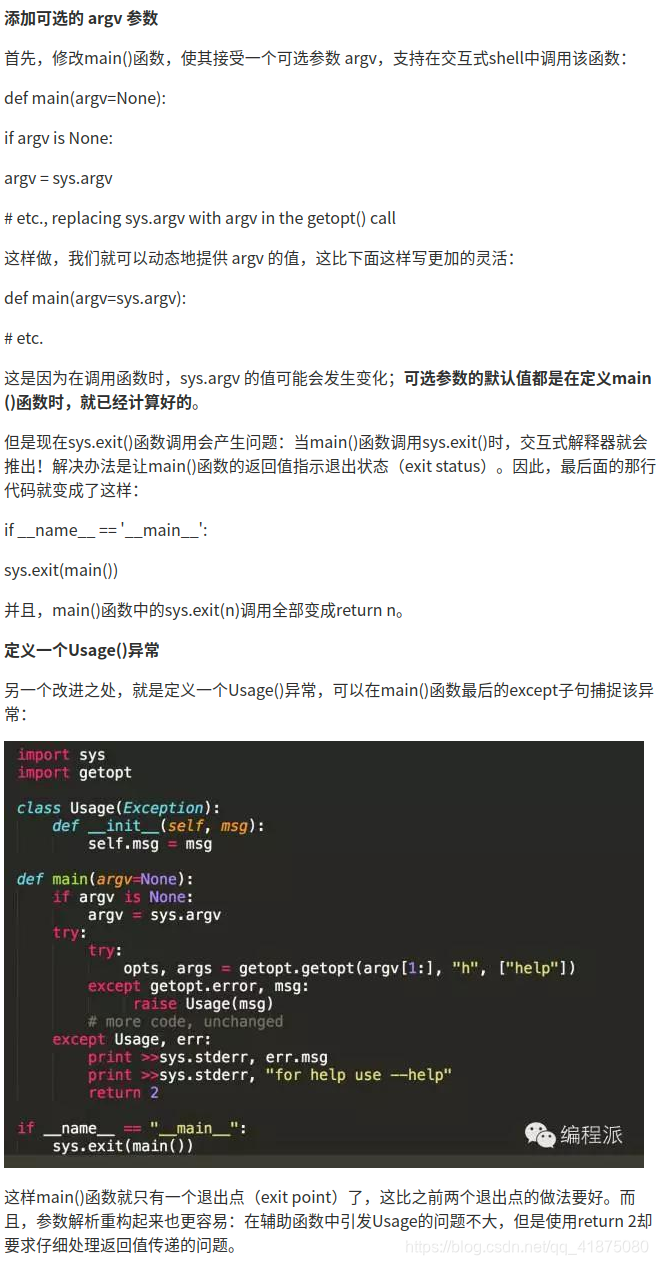
python 中__name__ = ‘main’ 的作用,到底干嘛的?
首先用最简洁的语言来说明一下 if name == ‘main’: 的作用:防止在被其他文件导入时显示多余的程序主体部分。
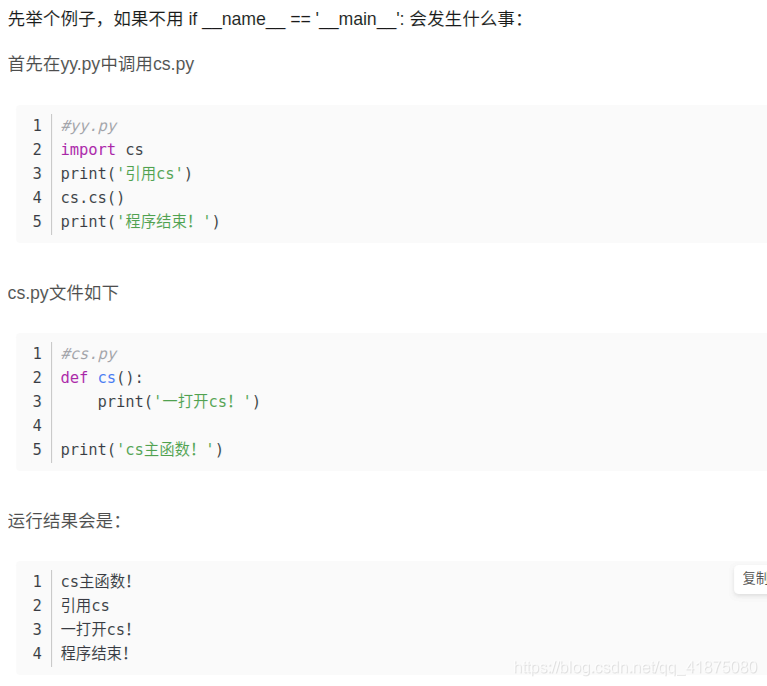
为什么!引用cs.py时,会先执行一次!
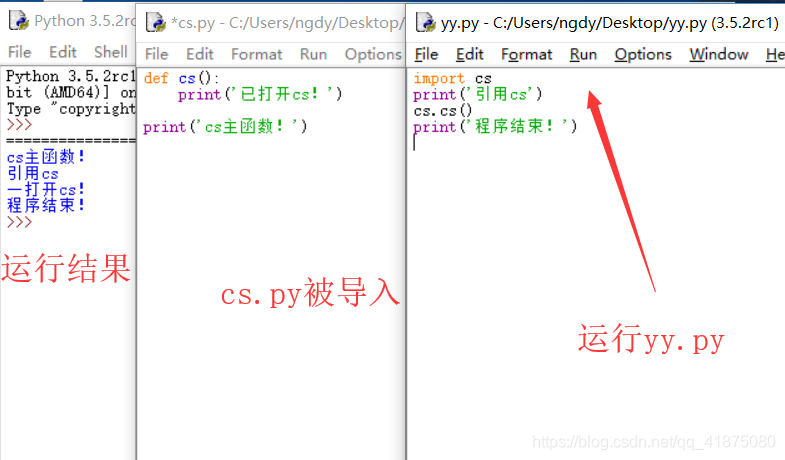
这里博客说得很明白
因为一旦你使用了import cs
那么在运行至这一句导入代码时会自动运行一次cs.py,cs.py中的函数被封装不会被直接运行,但是cs.py中有没被封装的语句:
print(‘cs主函数!’) 因此,这一句就会被多余地运行,哪怕你完全不需要这一句,你的目的只是调用cs.py中的cs()函数
就算是使用
from cs import cs 运行结果还是一样。
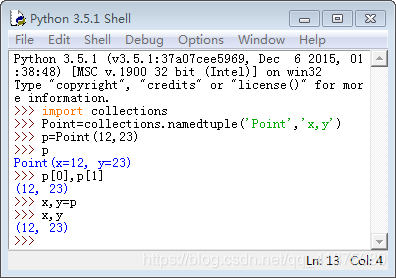
命名元组
名元组与普通元组一样,有相同的表现特征,其添加的功能就是可以根据名称引用元组中的项。
collections 模块提供了namedtuple()函数,用于创建自定义的元组数据类型,函数定义为:
collections.namedtuple(typename,field_names,verbose=False, rename=False)
第一个参数typename是想要创建的自定义元组数据类型的名称。
第二个参数field_names是一个字符串,其中包含使用空格或逗号分隔的名称,例如:’x y’ or ‘x, y’,每个名称代表该元组数据类型的一项。另外,field_names也可以是一个字符串序列[‘x’,’y’].
该函数返回一个自定义的类,可用于创建命名的元组。
下面讲一下字典变成命名元组的方法,代码发现的:
hp = namedtuple('hp', hp.keys())(**hp)
evaluation = namedtuple('evaluation', evaluation.keys())(**evaluation)
run = namedtuple('run', run.keys())(**run)
env = namedtuple('env', env.keys())(**env)
design = namedtuple('design', design.keys())(**design)
hp.keys()输出key的list,作为命名元组namedtuple的数据类型的项
使用 (**hp) 赋值,两个 * 表示字典的值,一颗 * 表示字典的键
python import 小结
原文: Python3 基础语法
关于 import 的小结,以 time.py 模块为例:
1、将整个模块导入,例如:import time,在引用时格式为:time.sleep(1)。
2、将整个模块中全部函数导入,例如:from time import *,在引用时格式为:sleep(1)。
3、将模块中特定函数导入,例如:from time import sleep,在引用时格式为:sleep(1)。
4、将模块换个别名,例如:import time as abc,在引用时格式为:abc.sleep(1)。
我想强调第二个!他甚至可以直接使用time.py中import的库!比如time.py中import的torch,numpy
tmdq模块显示进度条
简介
Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。
总之,它是用来显示进度条的,很漂亮,使用很直观(在循环体里边加个tqdm),而且基本不影响原程序效率。名副其实的“太强太美”了!这样在写运行时间很长的程序时,是该多么舒服啊!
给一张GIF图看一下实际效果
for i in tqdm(range(100)):
time.sleep(0.01)
functools.partial函数

预先为函数add设定参数的函数,比如例子中,为add函数余弦设定参数 a.
这样,调用对象p时,只需要输入参数b和c.
字符串中字符替换replace方法
先讨论一下它的用法:
str = “abcdef”
str.replace(old,new,[max])方法用于字符串的修改,将字符串str中的字符old替换为新的new字符串,max是可选参数,可以写也可以不写,不写的情况下,表示将str中所有的old替换为new,写之后表示最大替换次数。最后将修改后的字符串给返回,他是有返回值的
例如:
str= “abcdef”
print(str.replace(“abc”,’AAA’))
运行结果:
AAAdef
raise NotImplementedError() 的使用:
raise可以实现报出错误的功能,而报错的条件可以由程序员自己去定制。在面向对象编程中,可以先预留一个方法接口不实现,在其子类中实现。如果要求其子类一定要实现,不实现的时候会导致问题,那么采用raise的方式就很好。而此时产生的问题分类是NotImplementedError。
Python.__getitem__方法
getitem_ 可以让对象实现迭代功能,这样就可以使用for…in… 来迭代该对象了.
意思是,在循环中出现对象,自动寻找对象的_getitem_方法!!!
ex:
class Animal:
def __init__(self, animal_list):
self.animals_name = animal_list
def __getitem__(self, index):
return self.animals_name[index]
animals = Animal(["dog","cat","fish"])
for animal in animals:
print(animal)
dog
cat
fish
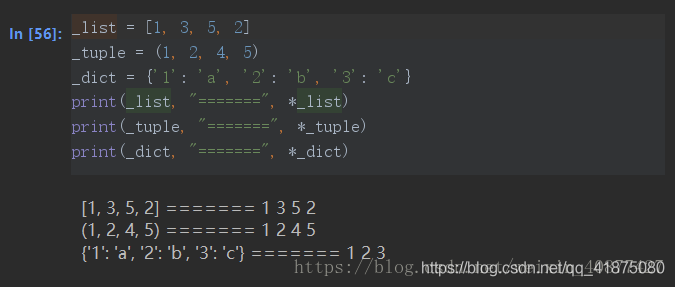
python 在列表,元组,字典变量前加*号
可以发现,在列表前加*号,会将列表拆分成一个一个的独立元素,不光是列表、元组、字典,由numpy生成的向量也可以拆分;
Python getattr() 函数
getattr() 函数用于返回一个对象属性值。
getattr(object, name[, default])
参数
object – 对象。
name – 字符串,对象属性。
default – 默认返回值,如果不提供该参数,在没有对应属性时,将触发AttributeError。
>>>class A(object):
... bar = 1
...
>>> a = A()
>>> getattr(a, 'bar') # 获取属性 bar 值
1
>>> getattr(a, 'bar2') # 属性 bar2 不存在,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'A' object has no attribute 'bar2'
>>> getattr(a, 'bar2', 3) # 属性 bar2 不存在,但设置了默认值
3
>>>
Python filter() 函数
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
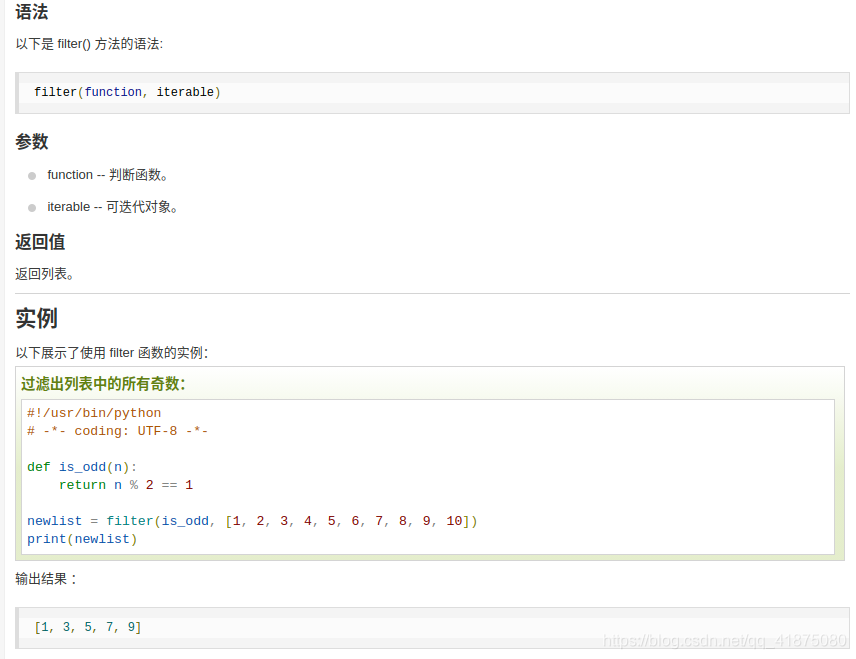
98.
Python 中 (&,|)和(and,or)之间的区别:
位运算和是否非0来决定输出
原文链接:https://blog.youkuaiyun.com/weixin_40041218/article/details/80868521

















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









