






1 基本概念
1.1客户端
b/s:必须使用http协议
c/s:协议可以随意选择
1.2 服务器
Nginx:
- 能处理静态请求 html,jpg
- 动态请求无法处理
- 服务器集群之后,每台服务器上部署的内容必须相同
fastCGI:帮助服务器处理动态请求
1.3 反向代理服务器:
- 客户端并不能直接访问web服务器,直接访问到的是反向代理服务器
- 客户端请求发送给反向代理服务器,反向代理将客户端请求转发给web服务器
1.4 关系型数据库:存储文件属性信息,用户的属性信息
1.5 redis非关系型数据库:提高程序效率,存储是服务器经常要从关系型数据库中读取的数据
1.6 FASTDFS分布式文件系统:存储文件内容,供用户下载
1.7 分布式文件系统:文件系统的全部,不在同一台主机上,而是在很多台主机上,多个分散的文件系统组合在一起,形成一个完整的文件系统
- 需要有网络
- 多台主机:不需要在同一地点
- 需要管理者
- 编写应用层的管理程序
2 FastDFS
是用c语言编写的一款开源的分布式文件系统,为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,注重高可用、高性能等指标,可以很容易搭建一套高性能的文件服务器集群,提供文件上传、下载等服务。
2.1 fastDFS框架的三个角色
-
追踪器:管理者 管理存储节点 – 守护进程
-
存储节点:存储节点是有多个的 – 守护进程
-
客户端:不是守护进程,是程序员编写的程序,文件的上传和下载
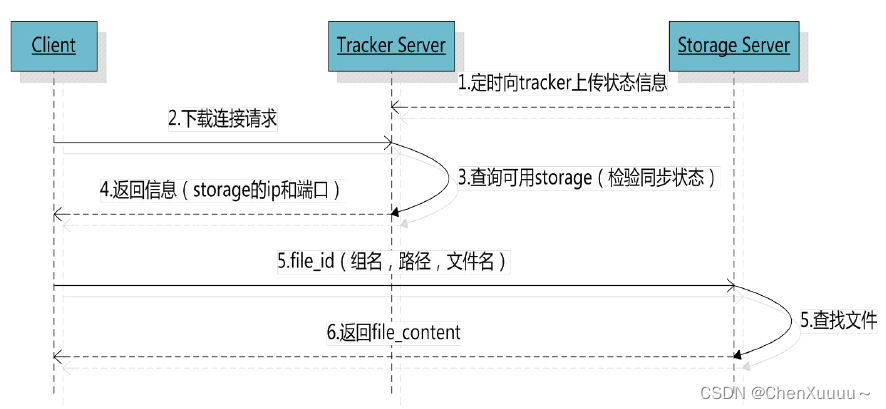
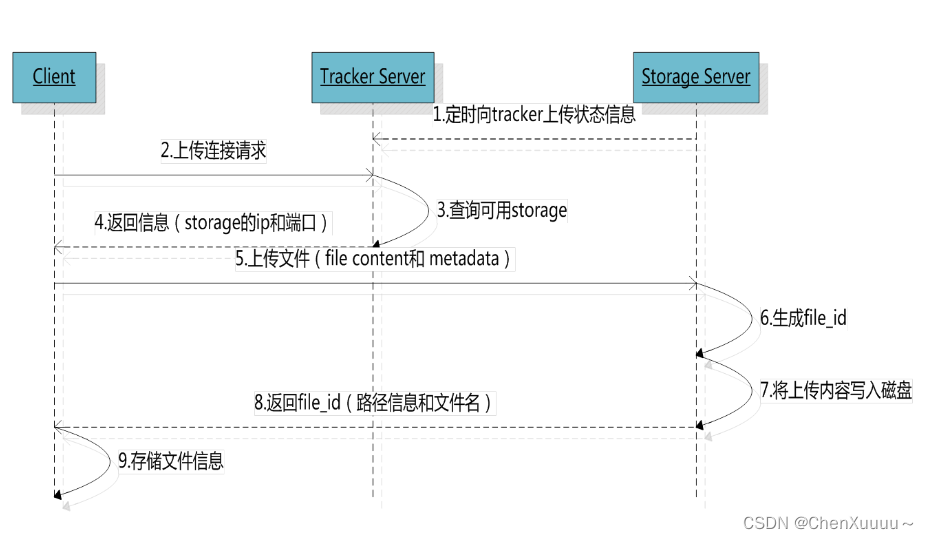
-
追踪器:最先启动追踪器
-
存储节点:第二个启动的角色,存储节点启动之后会单独开一个线程:汇报当前存储节点的容量和剩余容量、汇报数据的同步情况、汇报数据被下载的次数
-
客户端:最后启动,
- 上传,链接追踪器,询问存储节点的信息
- 哪个存储节点有足够的容量
- 追踪器查询,得到结果
- 追踪器将查到的存储节点的IP和端口发送到客户端
- 通过得到IP和端口连接存储节点
- 将文件内容发送给存储节点
- 下载,连接追踪器,询问存储节点的信息
- 要下载的文件在哪个存储节点
- 追踪器查询,得到结果
- 追踪器将查到的存储节点的IP和端口发送给客户端
- 通过得到IP和端口连接存储节点
- 下载文件
- 上传,链接追踪器,询问存储节点的信息
2.2 追踪器集群
为什么集群:避免单点故障
多个tracker如何工作:轮询工作
如何实现集群:修改配置文件
集群方式:横向扩容和纵向扩容
- 横向扩容:增加容量,添加一台新的主机,即新的分组,主机之间不需要通信
- 纵向扩容:数据备份,假设当前有两个组group1和group2,将新的主机放到现有的组中,每个组主机的数量从1->N ,这n台主机就是相互备份的关系,同一个组主机之间需要通信,每个组的容量等于容量最小的主机。
fastDFS配置文件:
tracker配置文件:tracker.conf
# 将追踪器和部署的主机的IP地址进程绑定, 也可以不指定
# 如果不指定, 会自动绑定当前主机IP, 如果是云服务器建议不要写
bind_addr=本地IP
# 追踪器监听的端口
port=22122
# 追踪器存储日志信息的目录, xxx.pid文件, 必须是一个存在的目录
base_path=/home/xxx/fastdfs
storage配置文件:storage.conf
# 当前存储节点对应的主机属于哪一个组
group_name=group1
# 当前存储节点和所应该的主机进行IP地址的绑定, 如果不写, 有fastdfs自动绑定
bind_addr=
# 存储节点绑定的端口
port=23000
# 存储节点写log日志的路径
base_path=/home/xxx/fastdfs
# 存储节点提供的存储文件的路径个数
store_path_count=2
# 具体的存储路径
store_path0=/home/xxx/fastdfs
store_path1=/home/xxx/fastdfs1
# 追踪器的地址信息
tracker_server=IP:22122
tracker_server=IP:22122
客户端配置文件:
# 客户端写log日志的目录
# 该路径必须存在
# 当前的用户对于该路径中的文件有读写权限
# 当前用户robin
# 指定的路径属于root
base_path=/home/xxx/fastdfs
# 要连接的追踪器的地址信息
tracker_server=IP:22122
tracker_server=IP:22122
fastDFS的启动:
第一个启动追踪器 --守护进程
# 启动程序在 /usr/bin/fdfs_*
# 启动
fdfs_trackerd 追踪器的配置文件(/etc/fdfs/tracker.conf)
# 关闭
fdfs_trackerd 追踪器的配置文件(/etc/fdfs/tracker.conf) stop
# 重启
fdfs_trackerd 追踪器的配置文件(/etc/fdfs/tracker.conf) restart
第二个启动存储节点 --守护进程
# 启动
fdfs_storaged 存储节点的配置文件(/etc/fdfs/stroga.conf)
# 关闭
fdfs_storaged 存储节点的配置文件(/etc/fdfs/stroga.conf) stop
# 重启
fdfs_storaged 存储节点的配置文件(/etc/fdfs/stroga.conf) restart
最后启动客户端 --普通进程
# 上传
fdfs_upload_file 客户端的配置文件(/etc/fdfs/client.conf) 要上传的文件
# 得到的结果字符串: group1/M00/00/00/wKj3h1vC-PuAJ09iAAAHT1YnUNE31352.c
# 下载
fdfs_download_file 客户端的配置文件(/etc/fdfs/client.conf) 上传成功之后得到的字符串(fileID)
fastDFS状态检测:
命令:fdfs_monitor /etc/fdfs/client.conf
# FDFS_STORAGE_STATUS:INIT :初始化,尚未得到同步已有数据的源服务器
# FDFS_STORAGE_STATUS:WAIT_SYNC :等待同步,已得到同步已有数据的源服务器
# FDFS_STORAGE_STATUS:SYNCING :同步中
# FDFS_STORAGE_STATUS:DELETED :已删除,该服务器从本组中摘除
# FDFS_STORAGE_STATUS:OFFLINE :离线
# FDFS_STORAGE_STATUS:ONLINE :在线,尚不能提供服务
# FDFS_STORAGE_STATUS:ACTIVE :在线,可以提供服务
int upload_file1(const char *confFile,const char* myFile,char* fileID)
{
char group_name[FDFS_GROUP_NAME_MAX_LEN + 1];
ConnectionInfo *pTrackerServer;
int result;
int store_path_index;
ConnectionInfo storageServer;
if ((result=fdfs_client_init(confFile)) != 0)
{
return result;
}
pTrackerServer = tracker_get_connection();
if (pTrackerServer == NULL)
{
fdfs_client_destroy();
return errno != 0 ? errno : ECONNREFUSED;
}
*group_name = '\0';
if ((result=tracker_query_storage_store(pTrackerServer, \
&storageServer, group_name, &store_path_index)) != 0)
{
fdfs_client_destroy();
fprintf(stderr, "tracker_query_storage fail, " \
"error no: %d, error info: %s\n", \
result, STRERROR(result));
return result;
}
result = storage_upload_by_filename1(pTrackerServer, \
&storageServer, store_path_index, \
myFile, NULL, \
NULL, 0, group_name, fileID);
if (result == 0)
{
printf("%s\n", fileID);
}
else
{
fprintf(stderr, "upload file fail, " \
"error no: %d, error info: %s\n", \
result, STRERROR(result));
}
tracker_disconnect_server_ex(pTrackerServer, true);
fdfs_client_destroy();
return result;
}
//使用多进程的方式来实现
int upload_file2(const char* confFile,const char* uploadFile,char* fileID,int size){
//创建管道
int fd[2];
int ret = pipe(fd);
if(ret ==-1){
perror("pipe error");
return -1;
}
//创建子进程
pid_t pid = fork();
if(pid==0){ //子进程
//标准输出重定向到管道的写端
dup2(fd[1],STDOUT_FILENO);
//关闭读端
close(fd[0]);
//执行命令
execlp("fdfs_upload_file","xxx",confFile,uploadFile,NULL);
perror("execlp error");
}else{
close(fd[1]);
read(fd[0],fileID,size);
wait(NULL);
}
}
3 数据库类型
3.1 基本概念
关系型数据库sql
- 操作数据库必须使用sql语句
- 数据存储在磁盘
- 存储的数据量大
- 例如:MySQL,oracle,sqlite,sql server
非关系型数据库:nosql
- 操作不使用sql语句
- 数据默认存储在内存,速度快,效率高,存储的数据量小
- 不需要数据库表,以键值对的方式存储
关系型和非关系型搭配使用:
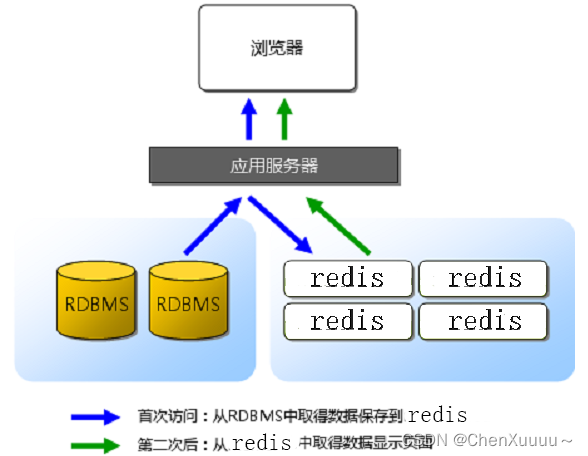
所有数据默认存储在关系型数据库中,客户端访问服务器,有一些数据,服务器需要频繁的查询数据,所以服务器首先将数据从关系型数据库中读出,将数据写入到redis中,客户端以后在访问服务器,服务器就从redis中直接读取数据。
redis的两个角色:
# 服务器 - 启动
redis-server # 默认启动
redis-server confFileName # 根据配置文件的设置启动
# 客户端
redis-cli # 默认连接本地, 绑定了6379默认端口的服务器
redis-cli -p 端口号
redis-cli -h IP地址 -p 端口 # 连接远程主机的指定端口的redis
# 通过客户端关闭服务器
shutdown
# 客户端的测试命令
ping [MSG]
redis中数据的组织格式:
键值对key:value
key:必须是字符串
value是可选的:String类型,List类型,Set类型,SortedSet类型,Hash类型
常用数据类型:
String类型:字符串
List类型:存储多个String字符串
Set类型:
集合:stl集合,默认是排序的,元素不重复
redis集合:元素不重复,数据无序
SortedSet类型:排序集合,集合中的每个元素分为两部分[分数,成员]->[66,“tom”]
Hash类型:跟map数据组织方式一样:key:value
redis常用命令:
string类型:
key -> string
value -> string
# 设置一个键值对->string:string
SET key value
# 通过key得到value
GET key
# 同时设置一个或多个 key-value 对
MSET key value [key value ...]
# 同时查看过个key
MGET key [key ...]
# 如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾
# key: hello, value: world, append: 12345
APPEND key value
# 返回 key 所储存的字符串值的长度
STRLEN key
# 将 key 中储存的数字值减一。
# 前提, value必须是数字字符串 -"12345"
DECR key
List类型 -存储多个字符串
key -> string
value -> list
# 将一个或多个值 value 插入到列表 key 的表头
LPUSH key value [value ...]
# 将一个或多个值 value 插入到列表 key 的表尾 (最右边)。
RPUSH key value [value ...]
# list中删除元素
LPOP key # 删除最左侧元素
RPOP key # 删除最右侧元素
# 遍历
LRANGE key start stop
start: 起始位置, 0
stop: 结束位置, -1
# 通过下标得到对应位置的字符串
LINDEX key index
# list中字符串的个数
LLEN key
Set类型:
key -> string
value -> set类型 ("string", "string1")
# 添加元素
# 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略
SADD key member [member ...]
# 遍历
SMEMBERS key
# 差集
SDIFF key [key ...]
# 交集
SINTER key [key ...]
# 并集
SUNION key [key ...]
SortedSet类型:
key -> string
value -> sorted ([socre, member], [socre, member], ...)
# 添加元素
ZADD key score member [[score member] [score member] ...]
# 遍历
ZRANGE key start stop [WITHSCORES] # -> 升序集合
ZREVRANGE key start stop [WITHSCORES] # -> 降序集合
# 指定分数区间内元素的个数
ZCOUNT key min max
Hash类型:
key ->string
value -> hash ([key:value], [key:value], [key:value], ...)
# 添加数据
HSET key field value
# 取数据
HGET key field
# 批量插入键值对
HMSET key field value [field value ...]
# 批量取数据
HMGET key field [field ...]
# 删除键值对
HDEL key field [field ...]
#判断哈希表key中的field是否存在,存在返回1,不存在返回0
HEXISTS key field
#返回哈希表key中所有域的值
HVALS key
Key相关的命令:
# 删除键值对
DEL key [key ...]
# 查看key值
KEYS pattern
查找所有符合给定模式 pattern 的 key 。
KEYS * 匹配数据库中所有 key 。
KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
KEYS h*llo 匹配 hllo 和 heeeeello 等。
KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
# 给key设置生存时长
EXPIRE key seconds
# 取消生存时长
PERSIST key
# key对应的valued类型
TYPE key
#以秒为单位,返回给定key的剩余生存时间
TTL key
redis配置文件:
配置文件给redis服务器使用,配置文件位置:从源码安装目录找 -> redis.conf
配置文件配置项
# redis服务器绑定谁之后, 谁就能访问redis服务器
# 任何客户端都能访问服务器, 需要注释该选项
bind 127.0.0.1 192.168.1.100
# 保护模式, 如果要远程客户端访问服务器, 该模式要关闭
protected-mode yes
# reids服务器启动时候绑定的端口, 默认为6379
port 6379
# 超时时长, 0位关闭该选项, >0则开启
timeout 0
# 服务器启动之后不是守护进程
daemonize no
# 如果服务器是守护进程, 就会生成一个pid文件
# ./ -> reids服务器启动时候对应的目录
pidfile ./redis.pid
#日志级别
loglevel notice
#如果服务器是守护进程,才会写日志文件
logfile "" -> 这是没写
logfile ./redis.log
#redis中数据库的个数
database 16
-切换 select dbID [dbID == 0~16-1]
redis数据持久化:数据从内存到磁盘的过程
持久化的两种方式:
rdb方式:
- 默认的持久化方式,默认打开
- 磁盘的持久化文件xxx.rdb
- 将内存数据以二进制的方式直接写入磁盘文件
- 文件比较小,恢复时间短,效率高
- 以用户设定的频率->容易丢失数据
- 数据完整性相对较低
aof方式
- 默认是关闭的
- 磁盘的持久化文件xxx.aof
- 直接将生成数据的命令写入磁盘文件
- 文件比较大,恢复时间长,效率低
- 以某种频率->1sec
- 数据完整性高
# rdb的同步频率,任意一个满足都可以
save 999 1
save 300 10
save 60 10000
# rdb文件的名字
dbfilename dump .rdb
# 生成的持久化文件保存的那个目录下,rdb和aof
dir ./
#是不是要打开aof模式
appendonly no
-> 打开: yes
#设置aof文件的名字
appendfilename "appendonly.aof"
# aof更新的频率
# appendfsync always
appendfsync everysec
# appendfsync no
rdb如何关闭 save ""
两种模式同时开启,如果进行恢复,如何选择?
效率上考虑:rdb模式
数据的完整性:aof模式
hiredis的使用:
API的使用:
// 连接数据库
redisContext *redisConnect(const char *ip, int port);
redisContext *redisConnectWithTimeout(const char *ip,
int port, const struct timeval tv);
执行redis命令:
// 执行redis命令
void *redisCommand(redisContext *c, const char *format, ...);
// redisCommand 函数实际的返回值类型
typedef struct redisReply {
/* 命令执行结果的返回类型 */
int type;
/* 存储执行结果返回为整数 */
long long integer;
/* str变量的字符串值长度 */
size_t len;
/* 存储命令执行结果返回是字符串, 或者错误信息 */
char *str;
/* 返回结果是数组, 代表数据的大小 */
size_t elements;
/* 存储执行结果返回是数组*/
struct redisReply **element;
} redisReply;
redisReply a[100];
element[i]->str
释放资源:
void freeReplyObject(void *reply);
void redisFree(redisContext *c);
hiredis向内存中写数据:
#include <stdio.h>
#include <hiredis.h>
int main(){
//1.连接redis服务器
redisContext* c = redisConnect("127.0.0.1",6379);
if(c->err != 0){
return -1;
}
void *prt = redisCommand(c,"hmset user userName zhangsan passwd 123456 age 23 sex man");
redisReply* ply = (redisReply*)prt;
if(ply->type == 5){
printf("状态:%s\n",ply->str);
}
freeReplyObject(ply);
//从数据库中取数据
prt=redisCommand(c,"hgetall user");
ply = (redisReply*)prt;
if(ply->type == 2){
for(int i=0;i<ply->elements;i+=2){
printf("key:%s,value:%s\n",ply->element[i]->str,ply->element[i+1]->str);
}
}
freeReplyObject(ply);
redisFree(c);
return 0;
}
命令:gcc -o myredis myredis.c -I/usr/local/include/hiredis/ -lhiredis
若报错找不到.so文件,则sudo
4 Nginx
作为web服务器,解析http协议;反向代理服务器;邮件服务器
4.1 正向代理:为用户服务
正向代理是位与客户端和原始服务器之间的服务器,为了能够从原始服务器获取请求的内容,客户端需要将请求发送给代理服务器,然后再由代理服务器将请求转发给原始服务器,原始服务器接受到代理服务器的请求并处理,然后将处理好的数据转发给代理服务器,之后再由代理服务器转发给客户端,完成整个请求过程。
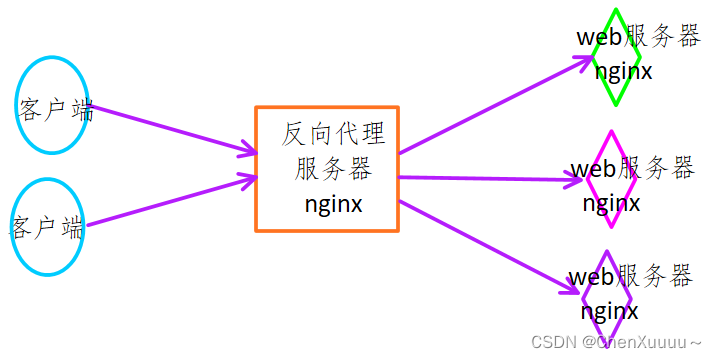
4.2反向代理
反向代理方式是指代理原始服务器来接受来自Internet的链接请求,然后将请求转发给内部网络上的原始服务器,并将从原始服务器上得到的结果转发给Internet上请求数据的客户端。所以,反向代理就是位于Internet和原始服务器之间的服务器,对于客户端来说就表现为一台服务器,客户端所发送的请求都是直接发送给反向代理服务器,然后由反向代理服务器统一调配。
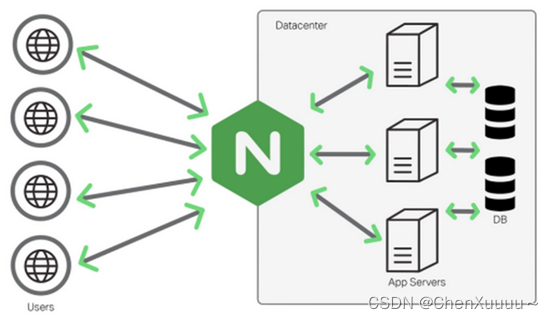
- 客户端给服务器发送请求,连接服务器,用户不知道服务器地址,只有反向代理服务器的地址是公开的
- 请求直接发给反向代理服务器
- 反向代理服务器将请求转发给后边的web服务器:web服务器N台,反向代理服务器转发请求会轮询进行
- web服务器收到请求进行处理,得到结果
- web服务器将处理结果发送给反向代理服务器
- 反向代理服务器将拿到的结果转发给客户端
4.3 域名和IP
什么是域名:www.baidu.com,www.jd.com
什么是IP地址:点分十进制的字符串:11.22.33.44
域名和IP地址的关系:域名绑定IP,一个域名只能绑定一个IP,一个IP地址被多个域名绑定
4.4 Nginx的安装和配置
下载:
官方地址: http://nginx.org/
Nginx相关依赖:
OpenSSL: http://www.openssl.org/
密码库
使用https进行通信的时候使用
ZLib下载: http://www.zlib.net/
数据压缩
安装:
./configure
make
sudo make install
PCRE下载: http://www.pcre.org/
解析正则表达式
安装
./configure
make
sudo make install
安装:
# nginx工作时候需要依赖三个库
# 三个参数=这三个库对应的源码安装目录
# 根据自己的电脑的库安装包的位置进行指定
./configure --with-openssl=../openssl-1.0.1t --with-pcre=../pcre-8.40 --withzlib=../zlib-1.2.11
make
sudo make install
Nginx相关的指令:
Nginx 的默认安装目录:
/usr/local/nginx
conf -> 存储配置文件的目录
html -> 默认的存储网站(服务器)静态资源的目录 [图片, html, js, css]
logs -> 存储log日志
sbin -> 启动nginx的可执行程序
Nginx可执行程序的路径:
/usr/local/nginx/sbin/nginx
# 快速启动的方式
# 1. 将/usr/local/nginx/sbin/添加到环境变量PATH中
# 2. /usr/local/nginx/sbin/nginx创建软连接, 放到PATH对应的路径中, 比如: /usr/bin
ln -s /usr/local/nginx/sbin/nginx /usr/bin/nginx
启动Nginx -需要管理器权限
# 假设软连接已经创建完毕
sudo nginx # 启动
关闭Nginx:
# 第一种, 马上关闭
sudo nginx -s stop
# 第二种, 等nginx作为当前操作之后关闭
sudo nginx -s quit
重新加载Nginx:
sudo nginx -s reload # 修改了nginx的配置文件之后, 需要执行该命令
检测是否安装成功:
知道nginx对应的主机IP地址 ->xxx.xxx.xx.xxx
在浏览器中访问该IP地址
看到一个welcome nginx的欢迎界面
配置:
1.Nginx配置文件的位置:/usr/local/nginx/conf/nginx.conf
2.Nginx配置文件的组织格式:
http -> 模块, http相关的通信设置
server模块 -> 每个server对应的是一台web服务器
location 模块
处理的是客户端的请求
mail -> 模块, 处理邮件相关的动作
3.常用配置介绍:
user nobody; # 启动之后的worker进程属于谁
- 错误提示: nginx操作xxx文件时候失败, 原因: Permission denied
- 将nobody -> root
worker_processes 1; # 设置worker进程的个数, 最大 == cpu的核数 (推荐)
error_log logs/error.log; # 错误日志, /usr/local/nginx
pid logs/nginx.pid; # pid文件, 里边是nginx的进程ID
# nginx的事件处理
events {
use epoll; # 多路IO转接模型使用epoll
worker_connections 1024; // 每个工作的进程的最大连接数
}
http->server -> 每个server模块可以看做一台web服务器
server{
listen 80; # web服务器监听的端口, http协议的默认端口
server_name localhost; # 对应一个域名, 客户端通过该域名访问服务器
charset utf8; # 字符串编码
location { // 模块, 处理客户端的请求
}
# 客户端 (浏览器), 请求:
http://192.168.10.100:80/login.html
# 服务器处理客户端的请求
服务器要处理的指令如何从url中提取?
- 去掉协议: http
- 去掉IP/域名+端口: 192.168.10.100:80
- 最后如果是文件名, 去掉该名字: login.html
- 剩下的: /
服务器要处理的location指令:
location /
{
处理动作
}
4.5 Nginx的使用:
部署静态网页:
静态网页存储目录:/usr/local/nginx/html
自己创建新的目录:mkdir /usr/local/nginx/mydir
访问地址:http://xxx.xxx.xx.xxx/login.html
login.html放在自己创建的目录中
服务器要处理的动作:
# 对应这个请求服务器要添加一个location
location 指令(/)
{
# 找一个静态网页
root yundisk; # 相对于/usr/local/nginx/来找
# 客户端的请求是一个目录, nginx需要找一默认显示的网页
index index.html index.htm;
}
# 配置之后重启nginx
sudo nginx -s reload
访问地址:http://xxx.xxx.xx.xxx/hello/reg.html
hello是一个目录
reg.html放在自己创建的目录中
添加location:
location /hello/
{
root hello;
index xx.html;
}
访问地址:http://xxx.xxx.xx.xxx/upload/ 浏览器显示upload.html
直接访问一个目录,得到一个默认网页
upload是一个目录,upload.html应该在upload目录中
location /upload/
{
root yundisk;
index upload.html;
}
反向代理和负载均衡:
准备工作:
- 需要客户端 1个:window中的浏览器作为客户端
- 反向代理服务器 ->1个:window作为反向代理服务器
- web服务器 ->2个:Ubuntu robin:xxx Ubuntu luffy:xxx
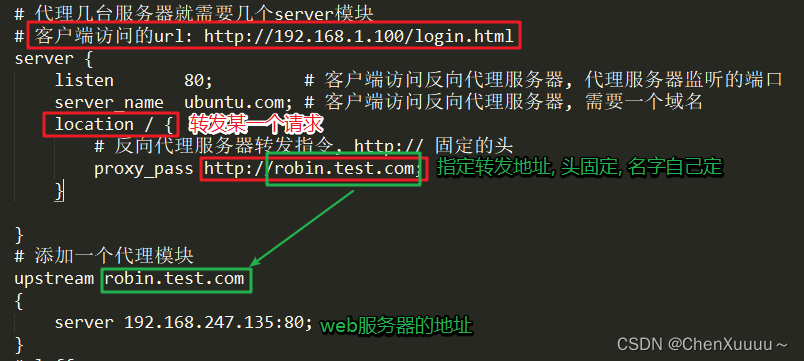
找window上对应的nginx的配置文件
- conf/nginx.conf
# 代理几台服务器就需要几个server模块
# 客户端访问的url: http://192.168.1.100/login.html
server {
listen 80; # 客户端访问反向代理服务器, 代理服务器监听的端口
server_name ubuntu.com; # 客户端访问反向代理服务器, 需要一个域名
location / {
# 反向代理服务器转发指令, http:// 固定
proxy_pass http://robin.test.com;
}
}
# 添加一个代理模块
upstream robin.test.com
{
server 192.168.247.135:80;
}
# luffy
server {
listen 80; # 客户端访问反向代理服务器, 代理服务器监听的端口
server_name hello.com; # 客户端访问反向代理服务器, 需要一个域名
location / {
# 反向代理服务器转发指令, http:// 固定
proxy_pass http://luffy.test.com;
}
}
# 添加一个代理模块
upstream luffy.test.com
{
server 192.168.26.250:80;
}
}
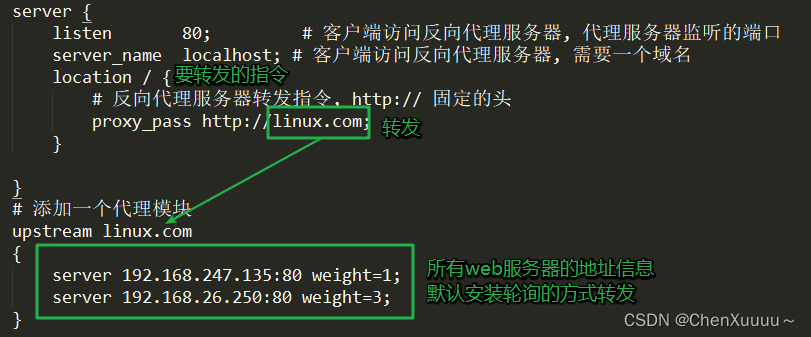
负载均衡设置:
server {
listen 80; # 客户端访问反向代理服务器, 代理服务器监听的端口
server_name localhost; # 客户端访问反向代理服务器, 需要一个域名
location / {
# 反向代理服务器转发指令, http:// 固定的头
proxy_pass http://linux.com;
}
location /hello/ {
# 反向代理服务器转发指令, http:// 固定的头
proxy_pass http://linux.com;
}
location /upload/ {
# 反向代理服务器转发指令, http:// 固定的头
proxy_pass http://linux.com;
}
}
# 添加一个代理模块
upstream linux.com
{
weight设置权重,让每个服务器处理的服务数量不同
server 192.168.247.135:80 weight=1;
server 192.168.26.250:80 weight=3;
}
## =====================================
web服务器需要做什么?
# 192.168.247.135
location /
{
root xxx;
index xxx;
}
location /hello/
{
root xx;
index xxx;
}
location /upload/
{
root xxx;
index xx;
}
# 192.168.26.250
location /
{
root xxx;
index xxx;
}
location /hello/
{
root xx;
index xxx;
}
location /upload/
{
root xxx;
index xx;
}
5 Nginx作为web服务器处理请求
静态请求:客户端访问服务器的静态网页,不涉及任何数据的处理
动态请求:客户端会将数据提交给服务器
# 使用get方式提交数据得到的url
http://localhost/login?user=zhang3&passwd=123456&age=12&sex=man
- http: 协议
- localhost: 域名
- /login: 服务器端要处理的指令
- ? : 连接符, 后边的内容是客户端给服务器提交的数据
- & : 分隔符
动态的url如何找服务器端处理的指令?
- 去掉协议
- 去掉域名/IP
- 去掉端口
- 去掉?和它后边的内容
# 如果看到的是请求行, 如何找处理指令?
POST /upload/UploadAction HTTP/1.1
GET /?username=tom&phone=123&email=hello%40qq.com&date=2018-01-
01&sex=male&class=3&rule=on HTTP/1.1
1. 找请求行的第二部分
- 如果是post, 处理指令就是请求行的第二部分
- 如果是get, 处理指令就是请求行的第二部分, ? 以前的内容
http协议:
请求消息:客户端发送给服务器的数据格式
四部分: 请求行, 请求头, 空行, 请求数据
请求行: 说明请求类型, 要访问的资源, 以及使用的http版本
请求头: 说明服务器要使用的附加信息
空行: 空行是必须要有的, 即使没有请求数据
请求数据: 也叫主体, 可以添加任意的其他数据
get方式提交:
第一行: 请求行
第2-9行: 请求头(键值对)
第10行: 空行
get方式提交数据, 没有第四部分, 提交的数据在请求行的第二部分, 提交的数据会全部显示在地址栏中
post方式提交数据:
第一行: 请求行
第2 -12行: 请求头 (键值对)
第13行: 空行
第14行: 提交的数据
响应消息:服务器给客户端发送的数据
四部分: 状态行, 消息报头, 空行, 响应正文
状态行: 包括http协议版本号, 状态码, 状态信息
消息报头: 说明客户端要使用的一些附加信息
空行: 空行是必须要有的
响应正文: 服务器返回给客户端的文本信息
第一行:状态行
第2 -11行: 响应头(消息报头)
第12行: 空行
第13-18行: 服务器给客户端回复的数据
fastCGI:
CGI:通用网关接口:描述了客户端和服务器程序之间传输数据的一种标准
- 用户通过浏览器访问服务器,发送了一个请求
- 服务器接收数据,对接收的数据进行解析
- nginx对于一些登录数据不知道如何处理,nginx将数据发送给cgi程序,服务器会创建一个cgi进程
- CGI进程执行:加载配置,连接其他服务器,逻辑处理,得到结果,将结果发送给服务器,退出
- 服务器将CGI处理结果发送给客户端
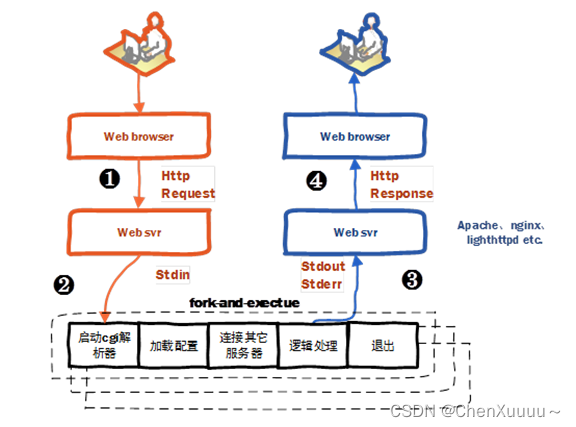
fastCGI致力于减少web服务器与CGI进程之间的互动开销,从而使服务器可以同时处理更多的web请求。
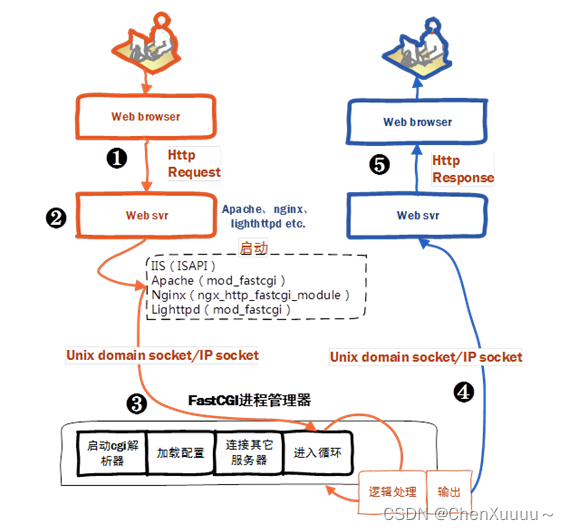
nginx和fastCGI:
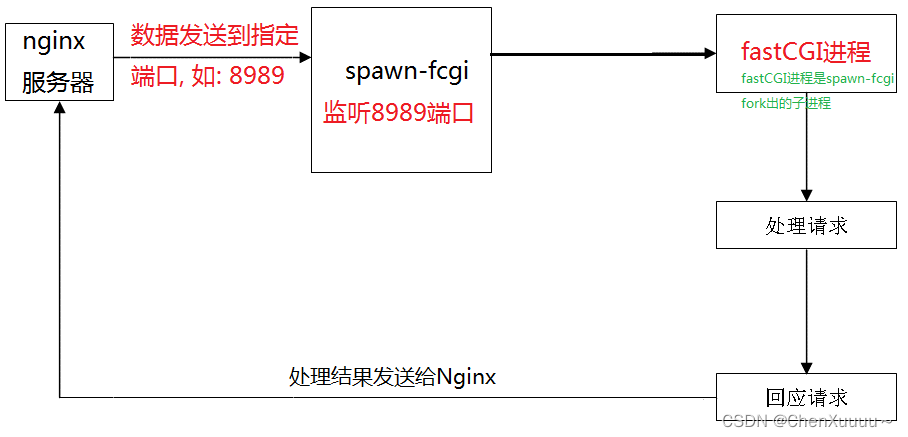
- 客户端访问,发送请求
- nginx web服务器,无法处理用户提交的数据
- spawn-fcgi通信过程中的服务器角色,被动接收数据,在spawn-fcgi启动的时候给其绑定IP和端口
- fastCGI程序,程序员写可执行程序,使用spawn-fcgi进程管理器启动login程序得到一进程。
nginx的数据转发,修改nginx.conf文件
通过请求的url http://localhost/login?user=zhang3&passwd=123456&age=12&sex=man 转换为一个
指令:
- 去掉协议
- 去掉域名/IP + 端口
- 如果尾部有文件名 去掉
- 去掉 ? + 后边的字符串
- 剩下的就是服务器要处理的指令: /login
location /login
{
# 转发这个数据, fastCGI进程
fastcgi_pass 地址信息:端口;
# fastcgi.conf 和nginx.conf在同一级目录: /usr/local/nginx/conf
# 这个文件中定义了一些http通信的时候用到环境变量, nginx赋值的
include fastcgi.conf;
}
地址信息:
- localhost
- 127.0.0.1
- 192.168.1.100
端口: 找一个空闲的没有被占用的端口即可
spawn-fcgi的启动:
# 前提条件: 程序猿的fastCGI程序已经编写完毕 -> 可执行文件 login
spawn-fcgi -a IP地址 -p 端口 -f fastcgi可执行程序
- IP地址: 应该和nginx的 fastcgi_pass 配置项对应
- nginx: localhost -> IP: 127.0.0.1
- nginx: 127.0.0.1 -> IP: 127.0.0.1
- nginx: 192.168.1.100 -> IP: 192.168.1.100
- 端口:
应该和nginx的 fastcgi_pass 中的端口一致
fastCGI程序:
// http://localhost/login?user=zhang3&passwd=123456&age=12&sex=man
// 要包含的头文件
#include "fcgi_config.h" // 可选
#include "fcgi_stdio.h" // 必须的, 编译的时候找不到这个头文件, find->path , gcc -I
// 编写代码的流程
int main()
{
// FCGI_Accept()是一个阻塞函数, nginx给fastcgi程序发送数据的时候解除阻塞
while (FCGI_Accept() >= 0)
{
// 1. 接收数据
// 1.1 get方式提交数据 - 数据在请求行的第二部分
// user=zhang3&passwd=123456&age=12&sex=man
char *text = getenv("QUERY_STRING");
// 1.2 post方式提交数据
char *contentLength = getenv("CONTENT_LENGTH");
// 根据长度大小判断是否需要循环
// 2. 按照业务流程进行处理
// 3. 将处理结果发送给nginx
// 数据回发的时候, 需要告诉nginx处理结果的格式 - 假设是html格式
printf("Content-type: text/html\r\n");
printf("<html>处理结果</html>");
}
}
http协议:
1.请求消息-客户端(浏览器)发送给服务器的数据格式。
四部分:请求行,请求头,空行,请求数据
- 请求行:说明请求类型,要访问的资源,以及使用的http版本
- 请求头:说明服务器要使用的附加信息
- 空行:空行是必须要有的,即使没有请求数据
- 请求数据:也叫主体,可以添加任意的其他数据
get方式提交数据:
- 第一行:请求头
- 第2-9行:请求头(键值对)
- 第10行:空行
get方式提交数据没有第四部分,提交的数据在请求行的第二部分,提交的数据会全部显示在地址栏中
post方式提交数据:
- 第一行:请求行
- 第2-12行:请求头(键值对)
- 第13行:空行
- 第14行:提交的数据
GET请求:
GET /?username=tom&phone=123&email=hello%40qq.com&date=2018-01-01&sex=male&class=3&rule=on HTTP/1.1
Host: 192.168.26.52:6789
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh,zh-CN;q=0.9,en;q=0.8
第十行
POST请求:
POST / HTTP/1.1
Host: 192.168.26.52:6789
Connection: keep-alive
Content-Length: 84
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: null
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh,zh-CN;q=0.9,en;q=0.8
第十三行
username=tom&phone=123&email=hello%40qq.com&date=2018-01-
01&sex=male&class=3&rule=on
2.响应消息:服务器给客户端发送的数据
四部分:状态行,消息报头,空行,响应正文
- 状态行:包括http协议版本号,状态码,状态消息
- 消息报头:说明客户端要使用的一些附加消息
- 空行:空行是必须要有的
- 响应正文:服务器返回给客户端的文本信息
第一行:状态行
第2 -11行: 响应头(消息报头)
第12行: 空行
第13-18行: 服务器给客户端回复的数据
HTTP/1.1 200 Ok
Server: micro_httpd
Date: Fri, 18 Jul 2014 14:34:26 GMT
/* 告诉浏览器发送的数据是什么类型 */
Content-Type: text/plain; charset=iso-8859-1 (必选项)
/* 发送的数据的长度 */
Content-Length: 32
Location:url
Content-Language: zh-CN
Last-Modified: Fri, 18 Jul 2014 08:36:36 GMT
Connection: close
#include <stdio.h>
int main(void)
{
printf("hello world!\n");
return 0;
}
3.http状态码
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
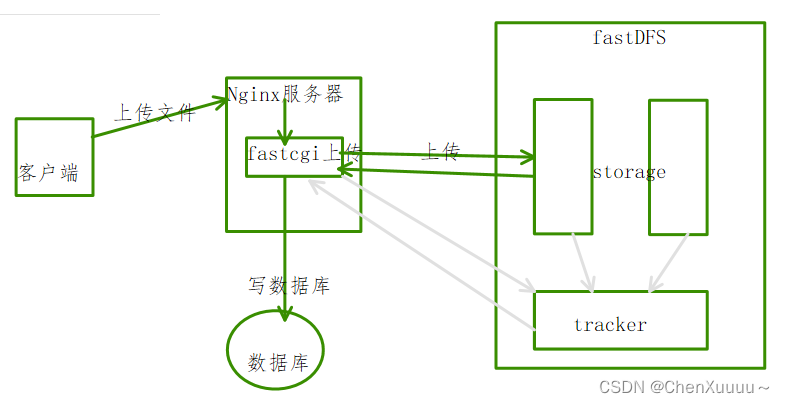
文件上传下载流程
上传流程:
下载流程:
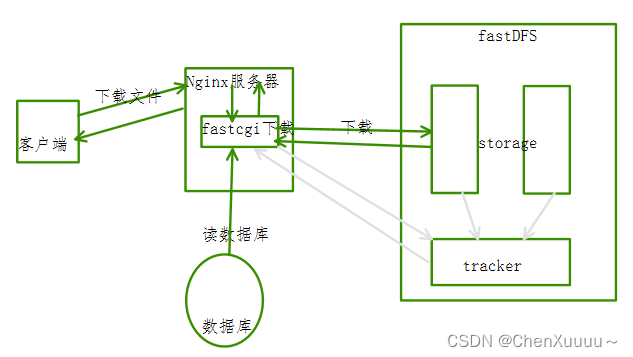
优化下载:让客户端连接fastdfs的存储节点,实现文件下载
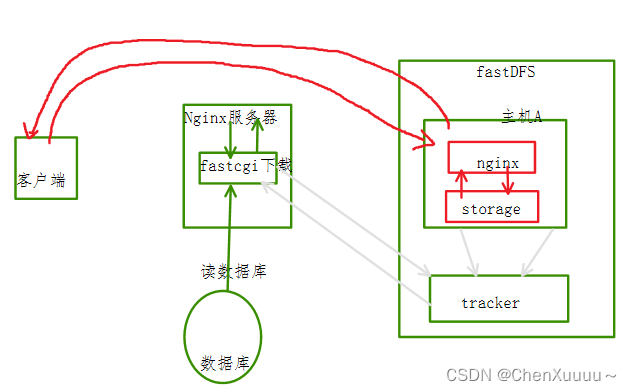
1.客户端发送请求使用的协议http
- fastDFS不能解析http协议
- nginx能解析http协议:nginx中安装fastDFS的插件
上传的时候将fileID和存储节点IP地址都进行存储就可以知道文件存储在对应的那个存储节点上
登录和注册协议:
客户端:
# URL
http://192.168.1.100:80/reg
# post数据格式
{
userName:xxxx,
nickName:xxx,
firstPwd:xxx,
phone:xxx,
email:xxx
}
服务器端:Nginx
配置:
location /reg
{
# 转发数据
fastcgi_pass localhost:10000;
include fastcgi.conf;
}
fastcgi程序:
int main()
{
while(FCGI_Accept() >= 0)
{
// 1. 根据content-length得到post数据块的长度
// 2. 根据长度将post数据块读到内存
// 3. 解析json对象, 得到用户名, 密码, 昵称, 邮箱, 手机号
// 4. 连接数据库 - mysql, oracle
// 5. 查询, 看有没有用户名, 昵称冲突 -> {"code":"003"}
// 6. 有冲突 - 注册失败, 通知客户端
// 7. 没有冲突 - 用户数据插入到数据库中
// 8. 成功-> 通知客户端 -> {"code":"002"}
// 9. 通知客户端回传的字符串的格式
printf("content-type: application/json\r\n");
printf("{\"code\":\"002\"}");
}
}
登陆协议:
客户端:
#URL
http://127.0.0.1:80/login
# post数据格式
{
user:xxxx,
pwd:xxx
}
服务端:
location /login
{
# 转发数据
fastcgi_pass localhost:10001;
include fastcgi.conf;
}
单例模式:
单例模式的优点:
- 在内存中只有一个对象,节省内存空间
- 避免频繁的创建销毁对象,可以提高性能
- 避免对共享资源的多重占用
- 可以全局访问
适用场景:
- 需要频繁实例化然后销毁的对象
- 创建对象耗时过多或者耗资源过多,但又经常用到的对象
- 有状态的工具类对象
- 频繁访问数据库或文件的对象
- 要求只有一个对象的场景
如何保证单例对象只有一个:
// 在类外部不允许进行new操作
class Test
{
public:
// 1. 默认构造
// 2. 默认析构
// 3. 默认的拷贝构造
}
// 1. 构造函数私有化
// 2. 拷贝构造私有化
单例模式的实现方式:
懒汉模式:单例对象在使用的时候被创建出来,线程安全问题需要考虑
class Test
{
public:
static Test* getInstance()
{
if(m_test == NULL)
{
m_test = new Test();
}
return m_test;
}
private:
Test();
Test(const Test& t);
// 静态变量使用之前必须初始化
static Test* m_test;
}
Test* Test::m_test = NULL; // 初始化
//*******************************
class Test
{
public:
static Test* getInstance();
private:
Test();
Test(const Test& t);
// 静态变量使用之前必须初始化
static Test* m_test;
}
Test* Test::m_test = NULL; // 初始化
// 第一种实现方式
Test::Test* getInstance()
{
if(m_test == NULL)
{
m_test = new Test();
}
return m_test;
}
// 弊端: 有线程安全问题, 会创建多个对象, 每个线程创建一个
// 解决方案: 线程同步, 加锁
// 第2种实现方式
// 假设在c++中有一个mutex对象, lock, unlock
Test::Test* getInstance()
{
mutex.lock(); // 加锁
if(m_test == NULL)
{
m_test = new Test();
}
mutex.unlock(); // 解锁
return m_test;
}
// 弊端: 效率很低, 每个线程得到单例对象是, 线性执行的
// 第3种实现方式
// 假设在c++中有一个mutex对象, lock, unlock
Test::Test* getInstance()
{
if(m_test == NULL)
{
mutex.lock(); // 加锁
if(m_test == NULL)
{
m_test = new Test();
}
mutex.unlock(); // 解锁
}
return m_test;
}
// 弊端: 第一次获取单例对象的时候, 线程是线性执行的, 第二次以后是并行的
// 第四种 : 要求编译器支持c++11
class Test
{
public:
static Test* getInstance();
private:
Test();
Test(const Test& t);
}
Test::Test* getInstance()
{
static Test test;
return &test;
}
饿汉模式:单例对象在使用之前被创建出来
class Test
{
public:
static Test* getInstance()
{
return m_test;
}
private:
Test();
Test(const Test& t);
// 静态变量使用之前必须初始化
static Test* m_test;
}
Test* Test::m_test = new Test(); // 初始化
在单例类中存储数据:
// 实现了一个单例模式的类
// 存储用户名/密码/服务器的iP/端口
class Test
{
public:
static Test* getInstance()
{
return &m_test;
}
// 设置数据
void setUserName(QString name)
{
// 多线程-> 加锁
m_user = name;
// 解锁
}
// 获取数据
QString getUserName()
{
return m_user;
}
private:
Test();
Test(const Test& t);
// 静态变量使用之前必须初始化
// static Test* m_test;
static Test m_test;
// 定义变量 -> 属于唯一的单例对象
QString m_user;
QString m_passwd;
QString m_ip;
QString m_port;
QString m_token;
}
// Test* Test::m_test = new Test(); // 初始化
Test Test::m_test;
QT中处理json数据:
内存中的json数据 -> 写磁盘
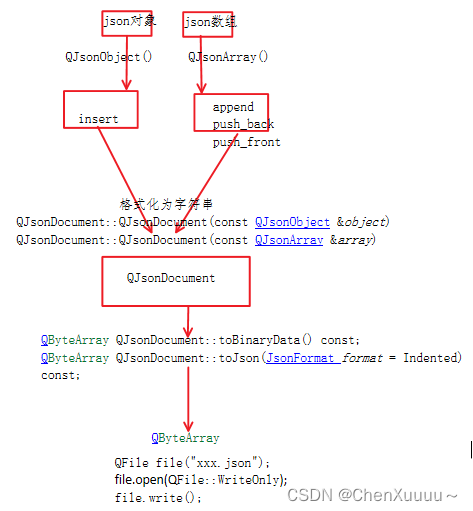
磁盘中的json字符串 -> 内存
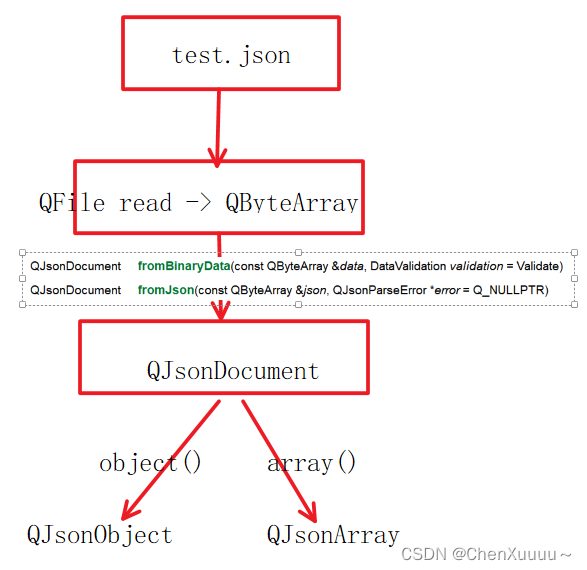
给服务器发送数据:
void Login::on_regButton_clicked()
{
//1.从控件中取出用户输入的数据
QString userName = ui->reg_userName->text();
QString nickName = ui->reg_NickName->text();
QString passwd = ui->reg_passwd->text();
QString email = ui->reg_mail->text();
QString phone = ui->reg_phone->text();
QString confirmPwd = ui->reg_confirmPwd->text();
//2.数据校验
QRegExp regexp;
QString User = "^[a-zA-Z0-9_@#-\\*]\\{3,16\\}$";
regexp.setPattern(User);
if(!regexp.exactMatch(userName)){
QMessageBox::warning(this,"ERROR","用户名格式不正确");
return;
}
// 3. 用户信息发送给服务器
QNetworkAccessManager* pManager = new QNetworkAccessManager(this);
QNetworkRequest request;
QString url = QString("http://%1:%2/reg").arg(ui->ip->text()).arg(ui->ip->text());
request.setUrl(url);
request.setHeader(QNetworkRequest::ContentTypeHeader,"application/json");
QJsonObject obj;
/*
{
userName:xxxx,
nickName:xxx,
firstPwd:xxx,
phone:xxx,
email:xxx
}
*/
//将用户提交的数据拼接成json对象字符串
obj.insert("userName",userName);
obj.insert("nickName",nickName);
obj.insert("passwd",passwd);
obj.insert("phone",phone);
obj.insert("email",email);
QJsonDocument doc(obj);
QByteArray json = doc.toJson();
QNetworkReply* reply = pManager->post(request,json);
// 4. 接收服务器发送的响应数据
connect(reply,&QNetworkReply::readyRead,this,[=](){
// 5. 对服务器响应进行分析处理, 成功or失败
// 5.1 接收数据
QByteArray all = reply->readAll();
// 5.2 需要知道服务器往回发送的字符串的格式
QJsonDocument doc = QJsonDocument::fromJson(all);
QJsonObject myobj = doc.object();
QString status = myobj.value("code").toString();
if("002"==status){
//成功
}
else if("003"==status){
//用户已经存在
}else{
//失败
}
});
QSS样式表
选择器类别:
- 通用选择器(*):匹配所有部件匹配当前窗口所有的子窗口
- 类型选择器(QWidget):匹配QWidget及其子类窗口的实例
- 类选择器(.QPushButton):匹配QPushButton的实例,但不包含子类
- ID选择器(QPushButton#okButton):匹配所有objectName为okButton的QPushButton实例
- 后代选择器(QDialogQPushButton):匹配属于QDialog后代(孩子,孙子等)的QPushButton所有实例
- 子选择器(QDialog>QPushButton):匹配属于QDialog直接子类的QPushButton所有实例
QSS的使用步骤:
- 根据介绍的选择器对所有的控件样式设置,写入qss文件中
- 在程序中读样式表文件,得到一个字符串 -> 样式字符串
- 将读出的样式设置给qt的应用程序
- 在qt中有一个全局的应用程序指针qApp
- qApp->setStyleSheet(“样式字符串”);
- QFile读磁盘文件,磁盘文件的编码格式必须是utf-8
//设置样式表
QFile file("mytest.qss");
bool bl = file.open(QFile::ReadOnly);
if(!bl){
qDebug()<<"文件未打开";
}
QByteArray all = file.readAll();
file.close();
qApp->setStyleSheet(all);
QT中组织post数据块:
// 组织数据块 - > QHttpPart
QHttpPart::QHttpPart();
// 设置数据头
void QHttpPart::setHeader(QNetworkRequest::KnownHeaders header, const QVariant &value);
- header:
- QNetworkRequest::ContentDispositionHeader
- QNetworkRequest::ContentTypeHeader
- value:
"form-data; 自定义的数据, 格式 xxx=xxx, 中间以;间隔"
// 适合传递少量的数据
void QHttpPart::setBody(const QByteArray &body);
- body: 传递的数据串
// 传递大文件
void QHttpPart::setBodyDevice(QIODevice *device);
- 使用参数device, 打开一个磁盘文件
// QHttpMulitPart
QHttpMultiPart::QHttpMultiPart(ContentType contentType, QObject *parent =Q_NULLPTR);
- 参数contentType: QHttpMultiPart::FormDataType
// 调用该函数会自动添加分界线 -> 使用频率高的函数
void QHttpMultiPart::append(const QHttpPart &httpPart);
// 查看添加的分界线的值
QByteArray QHttpMultiPart::boundary() const;
// 自己设置分界线, 一般不需要自己设置
void QHttpMultiPart::setBoundary(const QByteArray &boundary);
// 使用post方式发送数据
QNetworkReply *QNetworkAccessManager::post(const QNetworkRequest &request,QHttpMultiPart *multiPart);
void MainWindow::on_uploadBtn_clicked()
{
//1.创建networkmanager对象
QNetworkAccessManager* pManager = new QNetworkAccessManager(this);
//2.发送数据 post
QNetworkRequest request;
request.setUrl(QUrl("http://10.102.17.151/uploadFile"));
request.setHeader(QNetworkRequest::ContentTypeHeader,"multipart/form-data");
//post数据块
QFileInfo info(ui->filePath->text());
QHttpPart part;
QString disp = QString("form-data; user=\"%1\"; filename=\"%2\"; md5=\"%3\";size=%4")
.arg(LoginInstance::getInstance()->getName()).arg(info.fileName()).arg(getMd5(ui->filePath->text())).arg(info.size());
QString sufix = info.suffix();
part.setHeader(QNetworkRequest::ContentDispositionHeader,disp);
QFile *file = new QFile(ui->filePath->text());
file->open(QFile::ReadOnly);
part.setBodyDevice(file);
//传输的数据库的格式
part.setHeader(QNetworkRequest::ContentTypeHeader,"xxxx");
QHttpMultiPart *multiPart = new QHttpMultiPart(QHttpMultiPart::FormDataType,this);
multiPart->append(part);
ui->recordMsg->append("开始发送数据....");
QNetworkReply* reply = pManager->post(request,multiPart/*QHttpMultiPart *multiPart*/);
connect(reply,&QNetworkReply::readyRead,this,[=](){
//3.接收数据
QByteArray all = reply->readAll();
//4.格式解析 -> 纯文本
//5.判断是否上传成功
ui->recordMsg->append("服务器响应数据:"+all);
//释放内存 deleteLater 会自己把自己析构掉,自己释放自己
multiPart->deleteLater();
file->close();
file->deleteLater();
reply->deleteLater();
});
//进度条
connect(reply,&QNetworkReply::uploadProgress,this,[=](qint64 bytesSent,qint64 bytesTotal){
//更新进度条
qDebug()<<"当前进度:"<<bytesSent<<",总数:"<<bytesTotal;
if(bytesSent>0){
ui->progressBar->setValue(bytesSent * 100 / bytesTotal);
}
});
}
fastcgi程序
int recv_save_file(char *user, char *filename, char *md5, long *p_size)
{
int ret = 0;
char *file_buf = NULL;
char *begin = NULL;
char *p, *q, *k;
char content_text[512] = {0}; //文件头部信息
char boundary[512] = {0}; //分界线信息
//==========> 开辟存放文件的 内存 <===========
file_buf = (char *)malloc(4096);
if (file_buf == NULL)
{
return -1;
}
//从标准输入(web服务器)读取内容
int len = fread(file_buf, 1, 4096, stdin);
if(len == 0)
{
ret = -1;
free(file_buf);
return ret;
}
//===========> 开始处理前端发送过来的post数据格式 <============
begin = file_buf; //内存起点
p = begin;
/*
------WebKitFormBoundary88asdgewtgewx\r\n
Content-Disposition: form-data; user="mike"; filename="xxx.jpg"; md5="xxxx"; size=10240\r\n
Content-Type: application/octet-stream\r\n
\r\n
真正的文件内容\r\n
------WebKitFormBoundary88asdgewtgewx
*/
//get boundary 得到分界线, ------WebKitFormBoundary88asdgewtgewx
p = strstr(begin, "\r\n");
if (p == NULL)
{
ret = -1;
free(file_buf);
return ret;
}
//拷贝分界线
strncpy(boundary, begin, p-begin);
boundary[p-begin] = '\0'; //字符串结束符
//LOG(UPLOAD_LOG_MODULE, UPLOAD_LOG_PROC,"boundary: [%s]\n", boundary);
p += 2; //\r\n
//已经处理了p-begin的长度
len -= (p-begin);
//get content text head
begin = p;
//Content-Disposition: form-data; user="mike"; filename="xxx.jpg"; md5="xxxx"; size=10240\r\n
p = strstr(begin, "\r\n");
if(p == NULL)
{
ret = -1;
free(file_buf);
return ret;
}
strncpy(content_text, begin, p-begin);
content_text[p-begin] = '\0';
p += 2;//\r\n
len -= (p-begin);
//========================================获取文件上传者
//Content-Disposition: form-data; user="mike"; filename="xxx.jpg"; md5="xxxx"; size=10240\r\n
q = begin;
q = strstr(begin, "user=");
q += strlen("user=");
q++; //跳过第一个"
k = strchr(q, '"');
strncpy(user, q, k-q); //拷贝用户名
user[k-q] = '\0';
//========================================获取文件名字
//"; filename="xxx.jpg"; md5="xxxx"; size=10240\r\n
begin = k;
q = begin;
q = strstr(begin, "filename=");
q += strlen("filename=");
q++; //跳过第一个"
k = strchr(q, '"');
strncpy(filename, q, k-q); //拷贝文件名
filename[k-q] = '\0';
//========================================获取文件MD5码
//"; md5="xxxx"; size=10240\r\n
begin = k;
q = begin;
q = strstr(begin, "md5=");
q += strlen("md5=");
q++; //跳过第一个"
k = strchr(q, '"');
strncpy(md5, q, k-q); //拷贝文件名
md5[k-q] = '\0';
//========================================获取文件大小
//"; size=10240\r\n
begin = k;
q = begin;
q = strstr(begin, "size=");
q += strlen("size=");
k = strstr(q, "\r\n");
char tmp[256] = {0};
strncpy(tmp, q, k-q); //内容
tmp[k-q] = '\0';
*p_size = strtol(tmp, NULL, 10); //字符串转long
begin = p;
p = strstr(begin, "\r\n");
// 跳过最后一个请求头行和空行
p += 4; //\r\n\r\n
// len就是正文的起始位置到数组结束的长度
len -= (p-begin);
//下面才是文件的真正内容
/*
------WebKitFormBoundary88asdgewtgewx\r\n
Content-Disposition: form-data; user="mike"; filename="xxx.jpg"; md5="xxxx"; size=10240\r\n
Content-Type: application/octet-stream\r\n
\r\n
真正的文件内容\r\n
------WebKitFormBoundary88asdgewtgewx
*/
begin = p;
// 将数组中剩余的数据(文件的内容), 写入到磁盘中
int fd = open(filename, O_CREAT | O_WRONLY, 0664);
write(fd, begin, len);
// 1. 文件已经读完了
// 2. 文件还没读完
if(*p_size > len)
{
// 读文件 -> 接收post数据
// fread , read , 返回值>0== 实际读出的字节数; ==0, 读完了; -1, error
while( (len = fread(file_buf, 1, 4096, stdin)) > 0 )
{
// 读出的数据写文件
write(fd, file_buf, len);
}
}
// 3. 将写入到文件中的分界线删除
ftruncate(fd, *p_size);
close(fd);
free(file_buf);
return ret;
}
int main(){
while(FCGI_Accept()>=0){
//处理流程
//1.读一次数据,buf,保证能够将分界线和两个头都装进去
char user[24];
char fileName[32];
char md5[64];
long size;
recv_save_file(user,fileName,md5,&size);
//filename对应的文件上传到fastdfs
//上传得到的文件ID需要写数据库
//给客户端发送响应数据
printf("Content-type:text/plain\r\n\r\n");
printf("用户名:%s\n",user);
printf("文件名:%s,md5:%s,size:%ld\n",fileName, md5, size);
printf("客户端处理数据完毕,恭喜。。");
}
}
启动命令:spawn-fcgi -a IP地址 -p 端口 -f ./fastcgi程序
QT中的哈希算法:
//构造哈希对象
QCryptographicHash(Algorithm method);
// 添加数据
// c格式添加数据
void QCryptographicHash::addData(const char *data, int length);
// qt中的常用方法
void QCryptographicHash::addData(const QByteArray &data);
// 适合操作大文件
bool QCryptographicHash::addData(QIODevice *device); // QFile
- 使用device打开一文件, 在addData进行文件的读操作
// 计算结果
QByteArray QCryptographicHash::result() const;
// 一般适合,哈希值都是使用16进制格式的数字串来表示
QByteArray QByteArray::toHex() const;
[static] QByteArray QCryptographicHash::hash(const QByteArray &data, Algorithm method);
- 参数data: 要运算的数据
- 参数method: 使用的哈希算法
- 返回值: 得到的哈希值
QString MainWindow::getMd5(QString path){
QCryptographicHash hash(QCryptographicHash::Md5);
//1.添加数据
QFile file(path);
file.open(QFile::ReadOnly);
hash.addData(&file);
//2.数据运算 -> 结果
QByteArray res = hash.result().toHex();
//3.return result
return res;
}
总结
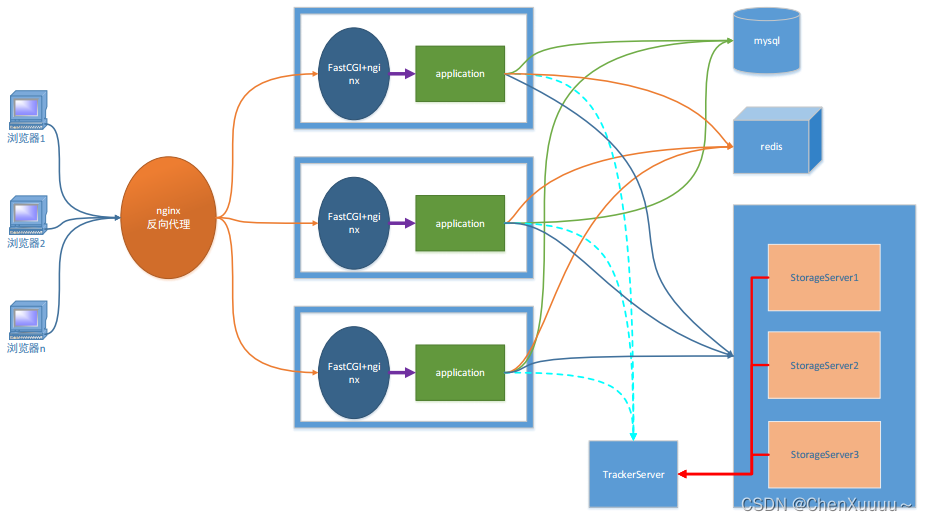
1.客户端
QT:了解Qt中http通信
2.nginx反向代理服务器
为web服务器服务
web服务器需要集群
3.web服务器 - nginx
处理静态请求 -> 访问服务器文件
处理动态请求 -> 客户端给服务器提交的数据
借助fastCGI进行处理
单线程或多线程的处理,使用spawn-fcgi启动
4.mysql
关系型数据库-服务器端
存储什么?项目中所有用到的数据
5.redis
非关系型数据库 - 服务器端使用
数据默认存在内存,不需要sql语句,不需要数据库表
键值对存储,操作数据使用的是命令
和关系型数据库配合使用
存储服务器端经常访问的数据
6.fastDFS
分布式文件系统
追踪器,存储节点,客户端
存储节点的集群
横向扩容 -> 增加容量
添加新组,将新主机放到该组中
纵向扩容 -> 备份
将主机放到已经存在的组中
存储用户上传的所有文件
给用户提高下载服务器
存储节点反向代理:
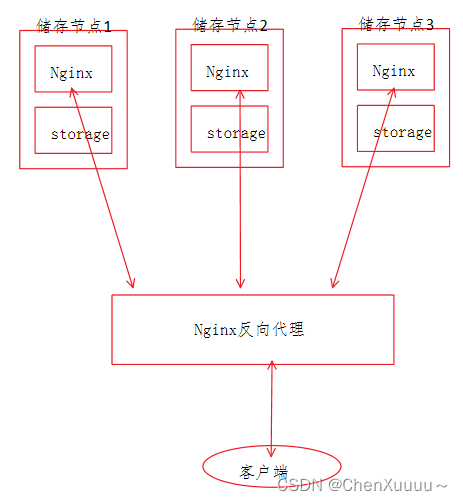
上图的反向代理服务器代理的是每个存储节点上部署的Nginx
- 每个存储节点上的Nginx的职责: 解析用户的http请求, 帮助用户快速下载文件客户端上传了一个文件, 被存储到了fastDFS上, 得到一个文件ID
/group1/M00/00/00/wKgfbViy2Z2AJ-FTAaM3Asg3Z0782.mp4"
因为存储节点有若干个, 所有下载的时候不知道对应的存储节点的访问地址
给存储节点上的nginx web服务器添加反向代理服务器之后, 下载的访问地址:
- 只需要知道nginx反向代理服务器的地址就可以了: 192.168.31.109
- 访问的url:http://192.168.31.109/group1/M00/00/00/wKgfbViy2Z2AJ-FTAaM3Asg3Z0782.mp4
客户端的请求发送给了nginx反向代理服务器
- 反向代理服务器不处理请求, 只转发, 转发给存储节点上的nginx服务器
反向代理服务器的配置 - nginx.conf
- 找出处理指令: 去掉协议, iP/域名, 末尾文件名, ?和后边的字符串
- /group1/M00/00/00/ - 完整的处理指令
- 添加location
http:
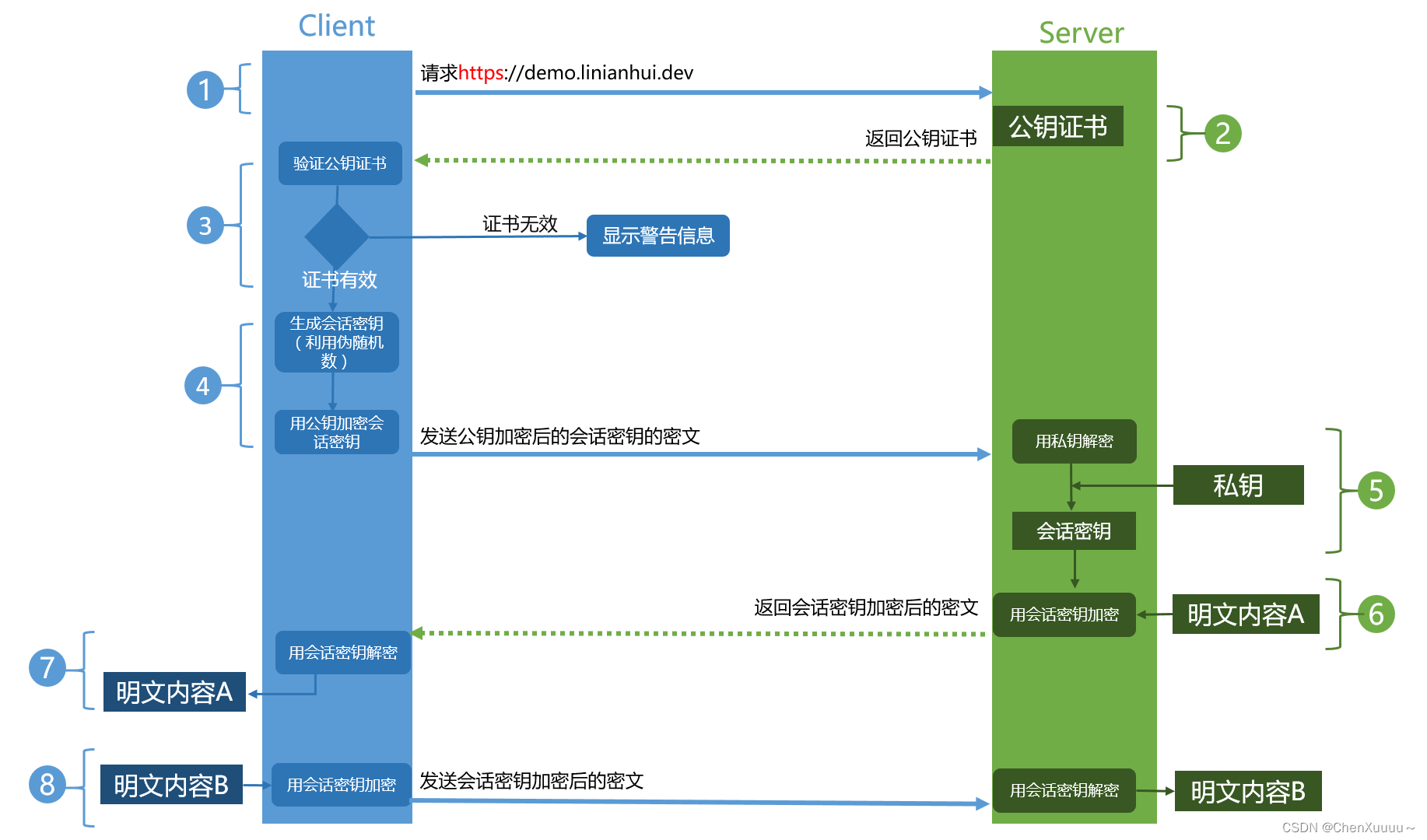
- 在百度服务器端首先生成一个密钥对 -> 对公钥分发
- 百度将公钥给到了CA认证机构,ca对私钥进行签名->生成了证书
- 第一部第二部只做一次
- 客户端访问百度,将百度ca生成的证书发送给客户端
- 浏览器对收到的证书进行认证
- 如果证书没有问题 -> 使用ca的公钥将服务器的公钥从证书中取出
- 得到了百度的公钥
- 浏览器端生成一个随机数,使用得到的公钥进行加密,发送给服务器
- 服务器端使用私钥解密,得到了随机数,这个随机数就是对称加密的密钥
- 现在密钥分发已经完成,后边的通信使用对称加密的方式
1.对称加密:加解密密钥是同一个
2.非对称加密
公钥,私钥
rsa:公钥私钥都是两个数字
ecc:椭圆曲线,两个点
公钥加密,私钥解密
数据传输的时候使用
私钥加密,公钥解密
数字签名
3.哈希函数
md5/sha1/sha2
得到散列值,散列值是定长的
4.消息认证码
生成消息认证码(将原始数据+共享密钥)*进行哈希运算=散列值
验证消息认证码:
(接收的原始数据+共享密钥)*哈希运算=新的散列值
新散列值和旧散列值进行比较,看是不是相同
作用:验证数据的一致性
弊端:两端共享密钥必须相同,共享密钥分发困难
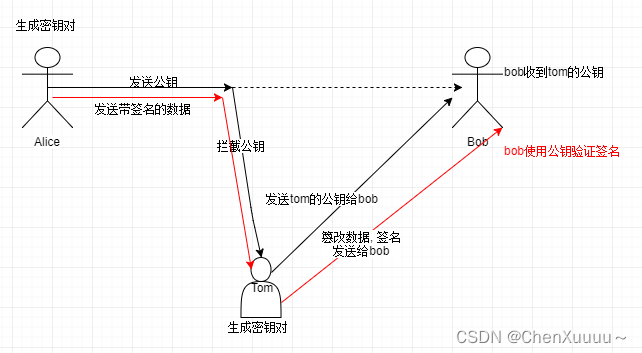
5.数字签名 -> 目的告诉所有人这个数据的所有者是xxx,就是拿私钥的人
生成一个非对称加密的密钥对
公钥,私钥
生成签名:
对原始数据进行哈希运算 -> 散列值
使用非对称加密的私钥,对散列值进行签名(私钥加密) -> 密文
得到的密文就是数字签名
签名的校验:
校验会受到签名者发送的数据
原始数据
数字签名
对接受的数据进行哈希运算 -> 散列值
使用非对称加密的公钥,对数字签名进行解密->明文==签名者生成的散列值
校验者的散列值和签名者的散列值进行比较
相同->校验成功,数据属于签名的人
失败->数据不属于签名的人
弊端:
接收公钥的人没有办法校验公钥的所有者
6.证书
有一个受信赖的机构CA对某人的公钥进行数字签名
ca有一个密钥对
使用ca的私钥对某个人的公钥进行加密->证书

















 4476
4476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









