







前面
集合的重要性不言而喻,我们在日常的开发中总离不开他们,面试中也是重点,但是我们这里只分析非并发包中的集合。
概述
HashMap,TreeMap都有红黑树实现的,如果小伙伴对红黑树有兴趣,请移步:https://blog.youkuaiyun.com/qq_41861259/article/details/103008703 ,我们都知道面试时,容器源码是非常重要的问点,所以我打算利用这次机会好好的分析下集合的源码。在JDK1.8下,常用的集合自然是包括List、Set、Map、Queue,而我们的目的是要掌握其中的原理,使用到的数据结构,以便在开发的过程中使用合适的对象。
首先我用StarUML画了一个简单的UML图,比较丑陋,如果各位实在受不了我也没得法了,从总体上看,其实容器主要分为Map、Collection,其中Collection又分为Set、List、Queue。小伙伴们注意了,很明显Map是独立在Collection之外的,且没有实现Iterable接口,然后我们分别对Map、List、Set进行分析。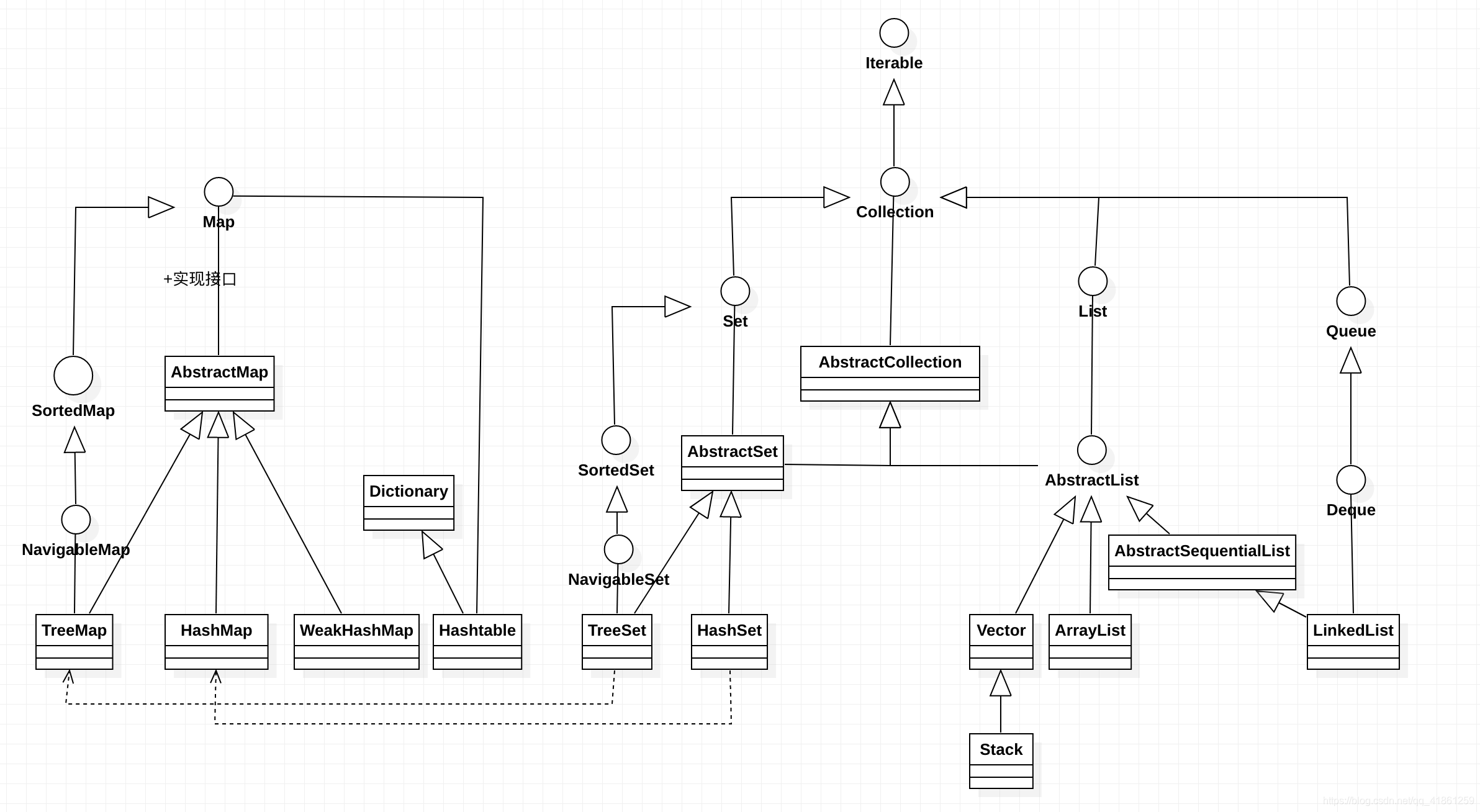
Map
Map四个分支HashMap、TreeMap(有序)、WeakHashMap、Hashtable(线程安全),我们分析一个就行了,TreeMap是基于红黑树实现的,HashMap是链表过长然后转化成红黑树,那么二者有什么区别呢?二者适应的场景是不同的,HashMap适用在Map中的插入、删除、定位,TreeMap适用于按自然顺序或自定义顺序遍历键(key),两者实现原理类似,所以介绍一个,HashTable我们在并发包中分析。
HashMap
1.首先,我们先来谈谈hashmap的初始化吧!,hashmap有这样几个构造函数
//一些需要的参数
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int MAXIMUM_CAPACITY = 1 << 30;
//不指定参数
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//指定初始容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//执行容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
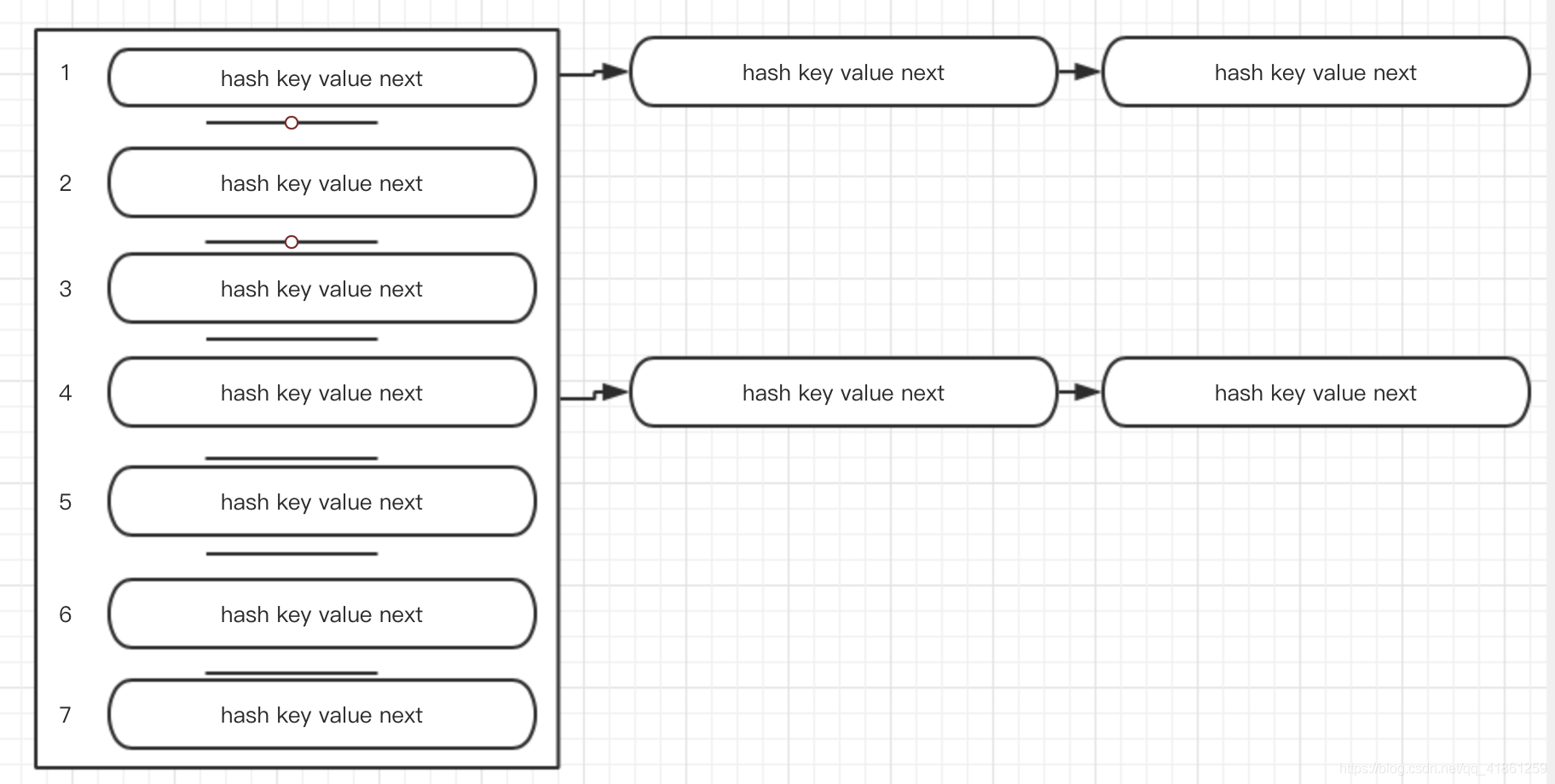
}initialCapacity : 初始的容器的大小。其次就是DEFAULT_LOAD_FACTOR = 0.75f叫做负载因子,那它是干什么用的呢?要想知道这两个参数的作用,我们需要先了解下HashMap的存储结构,它采用的是一种叫做散列桶的存储结构,如图所示。我们HashMap中维护的是一个Entry<k,v> table,他有一个初始的长度DEFAULT_INITIAL_CAPACITY = 1 << 4,当我们桶装满时就需要扩容,那怎样判断是否满了呢?这里就需要负载因子,当节点数超过容量 * LOAD_FACTOR时,就需要扩容。其中对于initialCapacity也是有讲究的,他必须时2^n,我们看下源码中初始化initialCapacity的方法tableSizeFor(),之后给定的位操作我就不进行解释了,不懂的就百度吧!方法上的注释:对于给定的tartget,返回2的power size。对于为什么有这样的规定,我们稍后会提到。
/**
* Returns a power of two size for the given target capacity.
* 对于给定的target,返回一个2的power size
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
2.初始化参数指定好了过后便可以进行相关的操作啦,包括put/get以及map接口中的那些,我们一个一个看
- put():
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }hashmap在添加key:value时,我们需要先获取key的hash值,然后通过hash值在散列桶找到正确的位置,如果某下标处不为空,需要以链表的形式连接,如果节点达到一定的阀值,链表将会转换成红黑树
1.key的hash值求法:如下代码,获取key的hashcode值 ^(h>>>16),然后通过获取到的hashstatic final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
2.然后进入我们真正的操作函数大体流程如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; ///判断数组是否为空,如果为空就需要进行初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //判断对应下标处的node是否为空,如果为空直接初始化一个新的节点 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { //否则,这里可以说是非常重要的代码 Node<K,V> e; K k; //如果下标处就是带插入的重复节点,直接替换 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //如果是一个树节点,就需要进行红黑树的增加操作了,比较复杂,数据结构分类专栏会仔细讲解 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //不是树节点,遍历链表即可 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; //判断数据是否满了,是否需要扩容 if (++size > threshold) resize(); //模版方法,是个空方法 afterNodeInsertion(evict); return null; }-
先用hash值,通过公式(n-1)&hash求的下标位置
-
判断所处的下标位置是否位空,如果为空,直接创建新的节点
-
否则,查看此hash值是否在该下标对应的链表,如果存在,判断存储结构,替换,如果不存在,加入节点
-
判断容量是否需要扩容,这里其实还有个重要的点(红黑树:)
-
对应的容器的节点数size进行相应的变化
-
- get()
首先也是获取key的hash值,判断数据是否为空,不为空,就判断是否在红黑树模式或者链表下进行遍历查找,get方法比较简单,难点在put方法中就有体现
List
从图中我们能直接看到属于List的有Vector、ArrayList、LinkedList、Vector。三者方法基本相同,都实现数据的添加、删除、定位以及都有迭代器进行数据的查找。Vector是线程安全的List,但是同步是需要额外性能的,所以不是线程安全的场景不必使用,底部也是基于数组实现,具体的在并发包中分析。LinkedList与ArrayList都不是线程安全的,但是两者在许多操作上都体现出不同的性能,下面我们对ArrayList与LinkedList进行分析
ArrayList
我们也还是先看下构造方法来了解初始化,代码如下,构造方法同样分为是否指定初始容量的大小,从代码中可以看出ArrayLIst中维护了一个Object数组elementData,如果没有指定初始容量的话,初始化为空数组,我们稍后会看到在add元素时会监测时候初始化。
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}下面我们就来看下add方法,size记录下一个元素存放的位置,在add元素之前会判断容量是否满了,我们进入ensureCapacityInternal方法一探究竟
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}当我们进入过后并没有发现key point,有点小失望,一路跟踪 终于在grow方法中的到答案,在grow方法中,根据oldCapacity计算出新的长度后,调用了Arrays.copyOf()方法,我们发现扩容时对整个数组进行了复制,如果数据量比较大就比较耗费性能了
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}我们在进入remove()方法看看,就像我在注释里写的一样,删除一个元素也要进行大量数据的移动,不得不说这是ArrayList的缺点,但是ArrayList的定位、查询都是极快的。
public E remove(int index) {
//检查索引是否符合
rangeCheck(index);
//操作更新
modCount++;
//获取需要移出的值
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//删除一个元素也要进行大量数据的复制
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
LinkedList
看完了ArrayList,知道ArrayList的优缺点,我们再来看下LinkedList,LinkedList到底有那些优缺点呢?LinkedList的remove以及扩容也会进行数据的大量移动嘛?下面我们来找答案
LinedLIst的构造器是不需要指定初始容量的,LinedList底层维护的是一个链表,每次增加节点时直接在尾部加入
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
接下来我们看下remove(),就像操作链表一样,删除节点也不需要大量数据的移动,只需要将对应的节点剔除
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}总结:通过对二者的分析,我们明白了不同的结构在不同的使用场景性能还是有非常大的差异的,所以要谨慎选择
Set
set中的元素是无序五重复的,他的实现包括TreeSet和HashSet,我们分别来看一下
HashSet&TreeSet
老规矩,我们首先看下HashSet的初始化,代码如下:看到代码我们都惊呆了,Set里怎么维护的是一个HashMap,并且指定的参数也都是HashMap需要的,那它到底如何利用HashMap来达到它需要的特性呢?
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}为了解决我们的困惑我们来到add():插入的数据变成了Map的key-value中的key,我们知道在HashMap中key是唯一的,所以set利用了这个key唯一,保证了set中的数据不是重复的,HashSet原理是基于HashMap实现的,我们彻底恍然大悟了。然后我们通过TreeSet的源码发现他是基于TreeMap的,那么我们也就不必多说了,所以我们一定要好好的学习学习HashMap中的知识啊!
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}Queue
从我们开始画的体系结构表我们能看到Queue是基于Linkedlist实现的,内部维护了一个这样的链表来达到队列的特性(先进先出),我们更加经常使用的应该是双端队列、阻塞队列,线程安全的队列吧,这部分留到并发容器中讲解,因为队列在并发中是一个大头。

















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









