







 本文介绍了如何在Spark SQL中通过继承UserDefinedAggregateFunction和Aggregator来创建自定义聚合函数,包括处理json文件的场景,并提供了测试结果。
本文介绍了如何在Spark SQL中通过继承UserDefinedAggregateFunction和Aggregator来创建自定义聚合函数,包括处理json文件的场景,并提供了测试结果。
json文件:
{"name":"cc", "age":18}
{"name":"qiqi", "age":19}
{"name":"xiaohei", "age":17}继承UserDefinedAggregateFunction
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.log4j.Level
import org.apache.log4j.Logger
object SparkSession_UDAF {
def main(args: Array[String]) {
Logger.getLogger("org").setLevel(Level.ERROR)
val spark = SparkSession.builder.
master("local")
.appName("spark session example")
.getOrCreate()
//进行转换之前,需要引入隐式转换规则
//import spark.implicits._
//这里的spark不是包名的意思,是sparkSession对象的名字
import spark.implicits._
//自定义聚合函数
//创建聚合函数对象
val udaf=new MyAgeAvgFunction
//注册聚合函数
spark.udf.register("avgAge",udaf)
//使用聚合函数
val frame=spark.read.json("G:/ccData/person.json")
frame.createOrReplaceTempView("user")
spark.sql("select avgAge(age) from user").show
//释放资源
spark.stop
}
}
//声明用户自定义聚合函数
//继承UserDefinedAggregateFunction
//实现方法
class MyAgeAvgFunction extends UserDefinedAggregateFunction{
//函数输入的数据结构
override def inputSchema:StructType={
new StructType().add("age", LongType)
}
//计算时的数据结构
override def bufferSchema:StructType={
new StructType().add("sum", LongType).add("count",LongType)
}
//函数返回的数据类型
override def dataType:DataType=DoubleType
//函数是否稳定
override def deterministic:Boolean=true
//计算之前的缓冲区的初始值
override def initialize(buffer:MutableAggregationBuffer):Unit={
//因为他有结构顺序的概念,所以根据下标来取
buffer(0)=0L //sum
buffer(1)=0L //count
}
//根据查询结果更新缓冲区数据
override def update(buffer:MutableAggregationBuffer,input:Row):Unit={
buffer(0)=buffer.getLong(0)+input.getLong(0)
buffer(1)=buffer.getLong(1)+1
}
//将多个节点的缓冲区合并
override def merge(buffer1:MutableAggregationBuffer,buffer2:Row):Unit={
//sum
buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)
//count
buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)
}
//计算(把最终的结果计算输出)
override def evaluate(buffer:Row):Any={
buffer.getLong(0).toDouble / buffer.getLong(1)
}
}
输出结果:

继承Aggregator
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders}
import org.apache.spark.sql.types._
import org.apache.log4j.Level
import org.apache.log4j.Logger
object SparkSession_UDAF2 {
def main(args: Array[String]) {
Logger.getLogger("org").setLevel(Level.ERROR)
val spark = SparkSession.builder.
master("local")
.appName("spark session example")
.getOrCreate()
//进行转换之前,需要引入隐式转换规则
//import spark.implicits._
//这里的spark不是包名的意思,是sparkSession对象的名字
import spark.implicits._
//创建聚合函数对象
val udaf=new MyAgeAvg
//将聚合函数转换为查询列
val avgCol=udaf.toColumn.name("avgAge")
val frame=spark.read.json("G:/ccData/person2.json")
val userDS=frame.as[UserBean]
//应用函数
userDS.select(avgCol).show
//释放资源
spark.stop
}
}
//声明用户自定义聚合函数
//继承Aggregator,设定泛型
//实现方法
case class UserBean(name:String,age:BigInt)
case class AvgBuffer(var sum:BigInt, var count:Int)
class MyAgeAvg extends Aggregator[UserBean,AvgBuffer,Double]{
//初始化
override def zero:AvgBuffer={
AvgBuffer(0,0)
}
/**
* 聚合函数
*@param b
*@param a
*@return
*/
override def reduce(b:AvgBuffer,a:UserBean):AvgBuffer={
b.sum=b.sum+a.age
b.count=b.count+1
b
}
//缓冲区的合并操作
override def merge(b1:AvgBuffer,b2:AvgBuffer):AvgBuffer={
b1.sum=b1.sum+b2.sum
b1.count=b1.count+b2.count
b1
}
//完成计算
override def finish(reduction:AvgBuffer):Double={
reduction.sum.toDouble / reduction.count
}
//转码(固定的,不用改),如果是你自定义的,就使用Encoders.product
override def bufferEncoder:Encoder[AvgBuffer]=Encoders.product
//转码(固定的,不用改),如果是基本类型的,就使用Encoders.scalaDouble
override def outputEncoder:Encoder[Double]=Encoders.scalaDouble
}
测试结果:
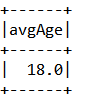

















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









