







文章思想:在深度学习中使用定点数来代替浮点数。传统的定点数取舍是最近邻取舍,本文引出了一种新的取舍方式:随机取舍 。即在产生下溢的时候是随机舍入到跟它最接近的两个数之一,其概率与他们之间的距离成反比。如 x=1.735 要保留一位小数,那么距离它最近的两个数分别是 1.7和1.8 。因为 |x-1.7|=0.35,|x-1.8|=0.65 所以x舍为1.7的概率是65%,入为1.8的概率是35%
论文中说这样的可以使得期望误差达到0。比最近邻舍入效果好一些。
浮点数量化为定点数的好处在于:
1.浮点数运算慢,每次运算要对阶之类的操作
2.定点数可以用一半的bit位达到浮点数的效果,可以节省空间
以下是论文中给出的这两种取舍方法的定义:
 符号意义:
符号意义:
IL:定点数的整数位数
FL:定点数的小数部分
<IL,FL>:表示一个定点数
WL:表示定点数的位数 ,即WL=IL+FL
x:表示原数字
e:表示最小的单位 e=2^(-FL)
Round-to-nearest:表示最近邻取舍
Stochastic:随机取舍
w.p:以概率为…
.
.
.
.
如果上溢了,则用最大或者最小的来代替它

.
.
.
.
论文接着设计实验来比对了该结论:
.
(一)使用mnist数据集在DNN上的效果如下:
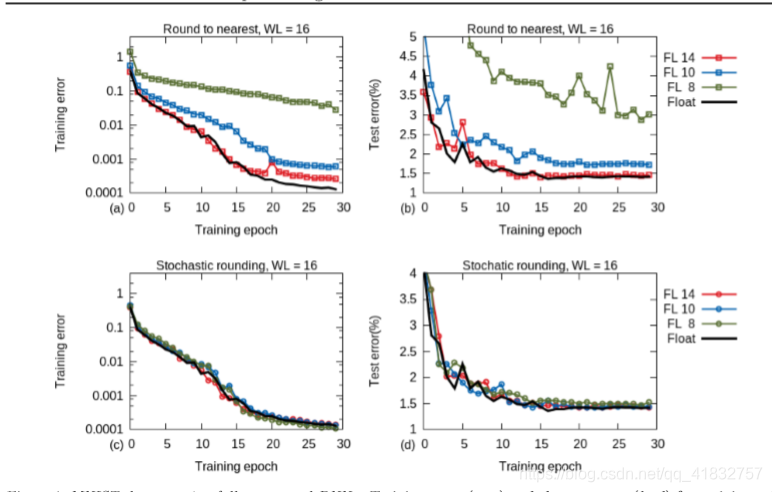
上面两幅图是采用16位的定点数,在最近邻舍入的情况下和32bit浮点数之间的比对,左边是训练集的误差(注意:训练集没有百分号),右边是测试集的误差。当然他们都没有浮点数好,但是随机舍入更加接近浮点数效果。
下面两幅图是采用16位定点数,在随机舍入的情况下和浮点数的比对,同样左边训练数据集,右边测试数据集。可以发现表现上跟浮点数相当了
.
.
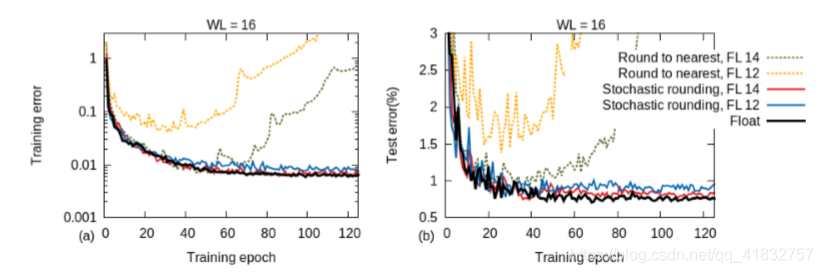
(二)使用mnist数据集在CNN上的效果如下:
 (三)实验设计部分:
(三)实验设计部分:
使用浮点数DNN全连接网络在mnist上的效果:
DNN网络结构如下:
两个隐层都是1000个结点
初始化连接权:均值为0,方差为0.01的正太分布,即N(0,0.01)
初始化偏置:全0
采用随机梯度下降,每次batch=100
结果:在测试数据集上的误差为1.4%
 对此我用tensorflow来验证了一下:
对此我用tensorflow来验证了一下:
同时使用了l2正则化和学习效率逐步递减的小操作。看论文中是训练了30轮。因为mnist数据集训练集有55000个,一个batch是100,所以应该迭代 30*55000/100=16500次,每55000/100=550次输出一次结果。实验结果与论文中基本一致
调试了好久,正则化参数最终设置为0.005
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
batch=100
input_node = 28*28
output_node = 10
fc_node1 = 1000
fc_node2=1000
regularization_rate=0.0005
epoch=40000
def trains(mnist):
init = tf.truncated_normal_initializer(stddev=0.01)
initb = tf.constant_initializer(0.0)
x=tf.compat.v1.placeholder(dtype=tf.float32,shape=[None,input_node],name='x-input')
y_=tf.compat.v1.placeholder(dtype=tf.float32,shape=[None,output_node],name='y-input')
weight1=tf.get_variable("weight1",[input_node,fc_node1],initializer=init)
bias1=tf.get_variable('bais1',[fc_node1],initializer=initb)
weight2=tf.get_variable('weight2',[fc_node1,fc_node2],initializer=init)
bias2=tf.get_variable('bias2',[fc_node2],initializer=initb)
weight3 = tf.get_variable('weight3', [fc_node2, output_node], initializer=init)
bias3=tf.get_variable('bias3',[output_node],initializer=initb)
hidden1 = tf.nn.relu(tf.matmul(x, weight1) + bias1)
hidden2=tf.nn.relu(tf.matmul(hidden1,weight2)+bias2)
y=tf.matmul(hidden2,weight3)+bias3
regularizer = tf.contrib.layers.l2_regularizer(regularization_rate)
loss=regularizer(weight1)+regularizer(weight2)
global_step = tf.Variable(0, trainable=False)
losses=loss+tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1)))
learning_rate = tf.compat.v1.train.exponential_decay(0.8, global_step, mnist.train.num_examples / batch, 0.95)
train_step = tf.compat.v1.train.GradientDescentOptimizer(learning_rate).minimize(losses, global_step=global_step)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.compat.v1.Session() as sess:
tf.global_variables_initializer().run()
validata_feed = {
x: mnist.validation.images, y_: mnist.validation.labels}
test_feed = {
x: mnist.test.images, y_: mnist.test.labels}
for i in range(epoch):
if i % 1000 == 0:
validata_acc = sess.run(accuracy, feed_dict=validata_feed)
print("训练 %d 轮后,训练数据集的精度为: %g%%" % (i, validata_acc*100))
print("当前学习效率为:%g"%(sess.run(learning_rate)))
if i%5000==0:
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("训练 %d 轮后,测试数据集的精度为: %g%%" % ( i, test_acc*100,))
xs, ys = mnist.train.next_batch(batch)
sess.run(train_step, feed_dict={
x: xs, y_: ys})
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("训练 %d 轮后,测试数据集的精度为: %g%%" % (epoch, test_acc * 100,))
def main(argv=None):
mnist = input_data.read_data_sets("C:/Users/tang/Desktop/deeplearning/mnist数据集", one_hot=True)
trains(mnist)
if __name__ == '__main__':
tf.app.run()
运行结果如下:
训练 0 轮后,验证数据集的精度为: 11.63%
训练 0 轮后,训练数据集的精度为: 11.4927%
训练 1 轮后,验证数据集的精度为: 96.34%
训练  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









