







以下是对这五个问题的详细回答:
1. 图像分类任务的定义及应用场景
-
定义:图像分类任务是指给定一张输入图像,通过计算机视觉算法和模型,将其自动分配到预定义的一个或多个类别标签中。例如,输入一张动物的照片,模型需要判断这张照片中的动物是猫、狗还是其他种类。其本质是从图像的像素数据中提取有意义的特征,并根据这些特征进行分类决策。
-
应用场景:
- 安防监控:对监控摄像头拍摄的图像进行实时分类,识别出人员、车辆、动物等不同类别,以便及时发现异常情况,如非法入侵、交通违规等。例如,在机场安检区域,通过图像分类可以快速识别出旅客携带的物品类别,辅助安检人员进行安全检查。
- 医疗影像诊断:对医学影像(如X光、CT、MRI等)进行分类,帮助医生识别病变组织、正常器官等,辅助疾病诊断。例如,在肺癌筛查中,对肺部CT影像进行分类,判断是否存在结节以及结节的性质(良性或恶性)。
- 工业质检:在生产线上对产品图像进行分类,检测产品是否存在缺陷以及缺陷的类型,如表面划痕、裂纹、颜色异常等,提高产品质量和生产效率。例如,对手机外壳的图像进行分类,筛选出合格与不合格的产品。
- 社交媒体和内容管理:社交媒体平台可以对用户上传的图片进行分类,以便更好地组织和推荐内容。例如,将用户上传的照片分为风景、人物、美食、宠物等类别,方便用户浏览和平台进行个性化推荐。
2. 图像分类任务的难点
-
光照变化:不同的光照条件会导致图像的亮度、对比度和颜色发生变化,从而影响图像的特征提取和分类准确性。例如,同一物体在白天和夜晚拍摄的照片可能看起来差异很大,给分类模型带来挑战。

-
视角变化:物体的拍摄视角不同,其在图像中的形状、大小和外观可能会有很大差异。例如,从正面、侧面、俯视等不同角度拍摄的汽车图像,需要模型能够适应这些视角变化,准确识别出汽车类别。

-
尺度变化:图像中物体的大小可能会因拍摄距离等因素而不同,小尺度的物体可能细节不明显,大尺度的物体可能占据图像的大部分区域,这对模型的尺度不变性提出了要求。例如,远处的行人在图像中可能只是一个小点,而近处的行人则占据较大面积,模型需要能够正确识别不同尺度下的行人。

-
背景干扰与遮挡:复杂的背景可能会干扰对目标物体的识别和分类。例如,在森林中拍摄的动物照片,树木、草地等背景元素可能会与动物的特征混淆,使模型难以准确分类。

-
类内差异(形变)和类间相似性:同一类别中的物体可能具有较大的外观差异,而不同类别中的物体可能在某些方面具有相似性。例如,不同品种的狗在外观上可能差异很大,但某些狗可能与其他动物(如狼)在外观上有一定的相似性,这增加了分类的难度。

-
数据不平衡:在实际应用中,不同类别的图像数据数量可能存在很大差异。例如,在某些场景中,正常样本(如正常的产品图像)数量远远多于异常样本(如带有缺陷的产品图像),这可能导致模型在训练过程中偏向于多数类,对少数类的分类效果不佳。
-
运动模糊:

-
类别繁多:

3. 图像分类基于规则的方法是否可行
-
基于规则的方法在一定程度上可行,但存在局限性:
- 早期尝试:在深度学习兴起之前,基于规则的方法曾被用于图像分类。例如,对于简单的几何形状分类,可以通过定义一些规则来判断图像中的形状,如根据边的数量、角度等特征来区分三角形、正方形、圆形等。对于特定领域的图像,如车牌识别,可以根据车牌的颜色、字符的位置和形状等规则来进行分类。
- 局限性:然而,对于复杂的自然图像分类任务,基于规则的方法面临诸多挑战。首先,图像中的物体具有丰富的外观变化和多样性,很难用一套固定的规则来涵盖所有情况。其次,规则的制定往往需要大量的领域知识和人工干预,且随着图像数据的增加和任务的复杂化,规则的维护和更新变得非常困难。此外,规则方法难以捕捉图像中物体的语义信息和上下文关系,例如,仅通过规则很难准确判断一张风景照片中包含的具体场景(如海滩、山脉、森林等)以及场景中的各种元素之间的关系。
4. 数据驱动的图像分类范式及举例说明
- 数据驱动的图像分类范式:是指利用大量的标注数据,通过机器学习或深度学习算法,让模型自动从数据中学习图像的特征和分类规律,而不是依赖人工制定的规则。这种方法的核心思想是模型通过对大量数据的学习,能够自动发现数据中的模式和特征,从而实现对新图像的分类。

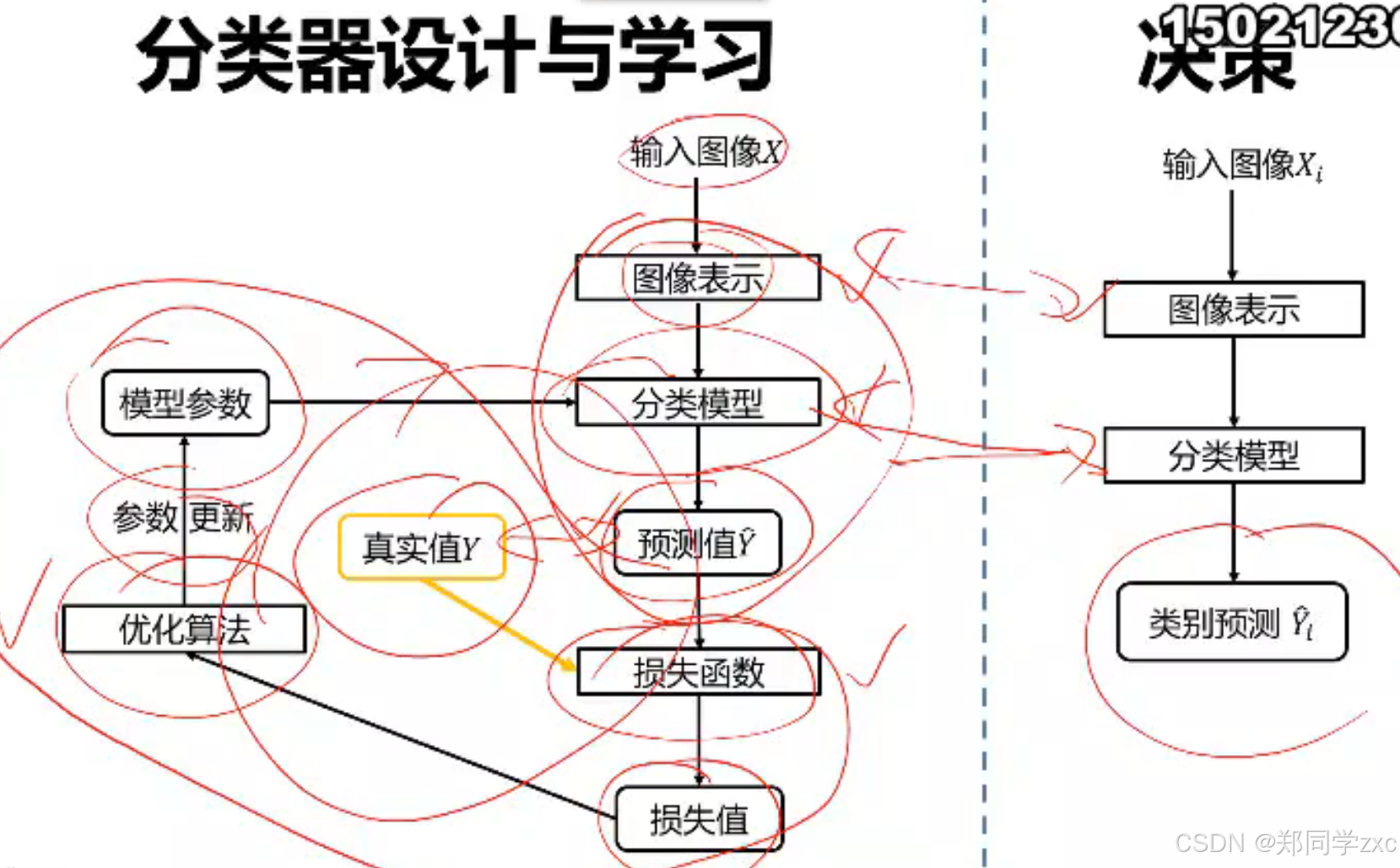
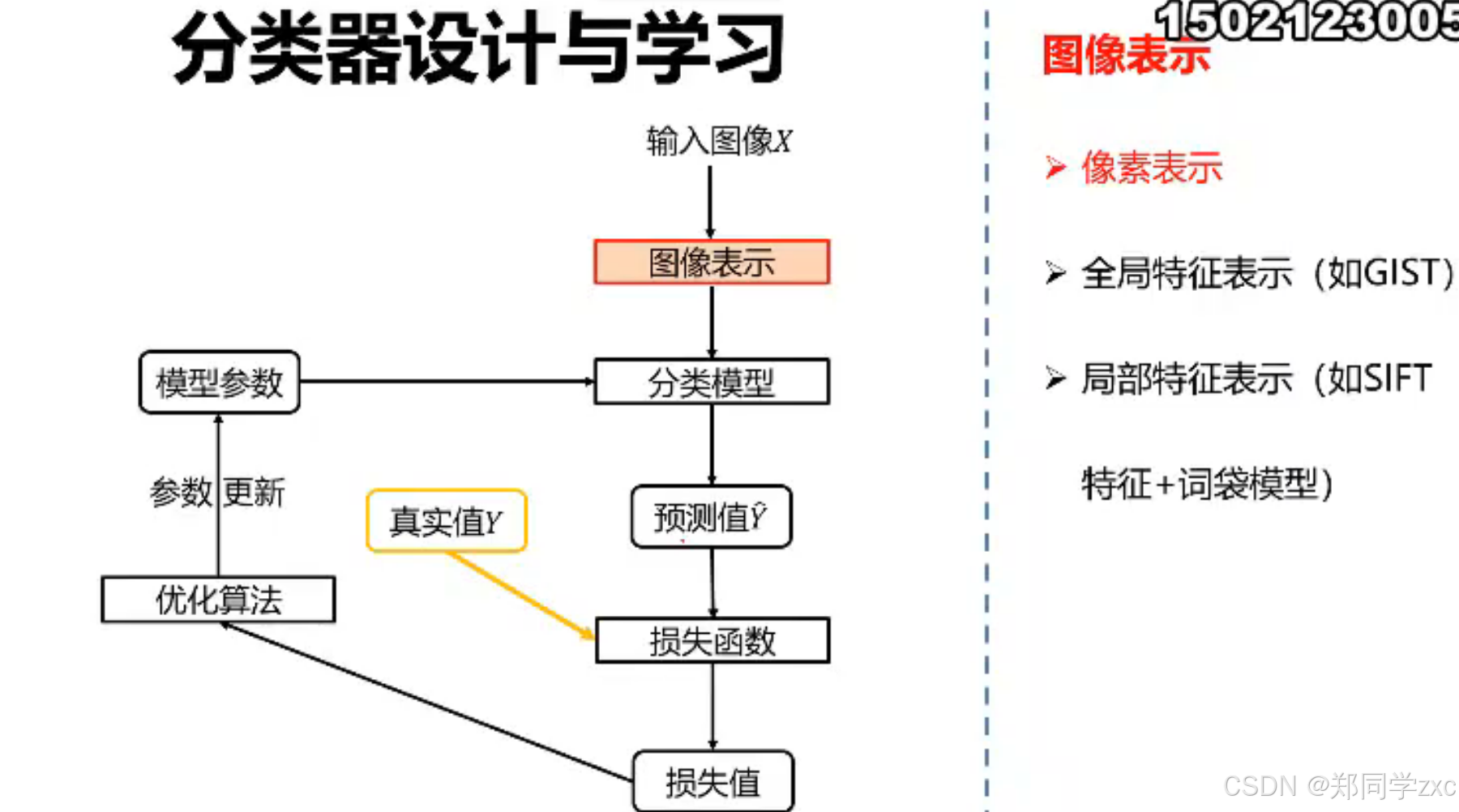
- 举例说明:
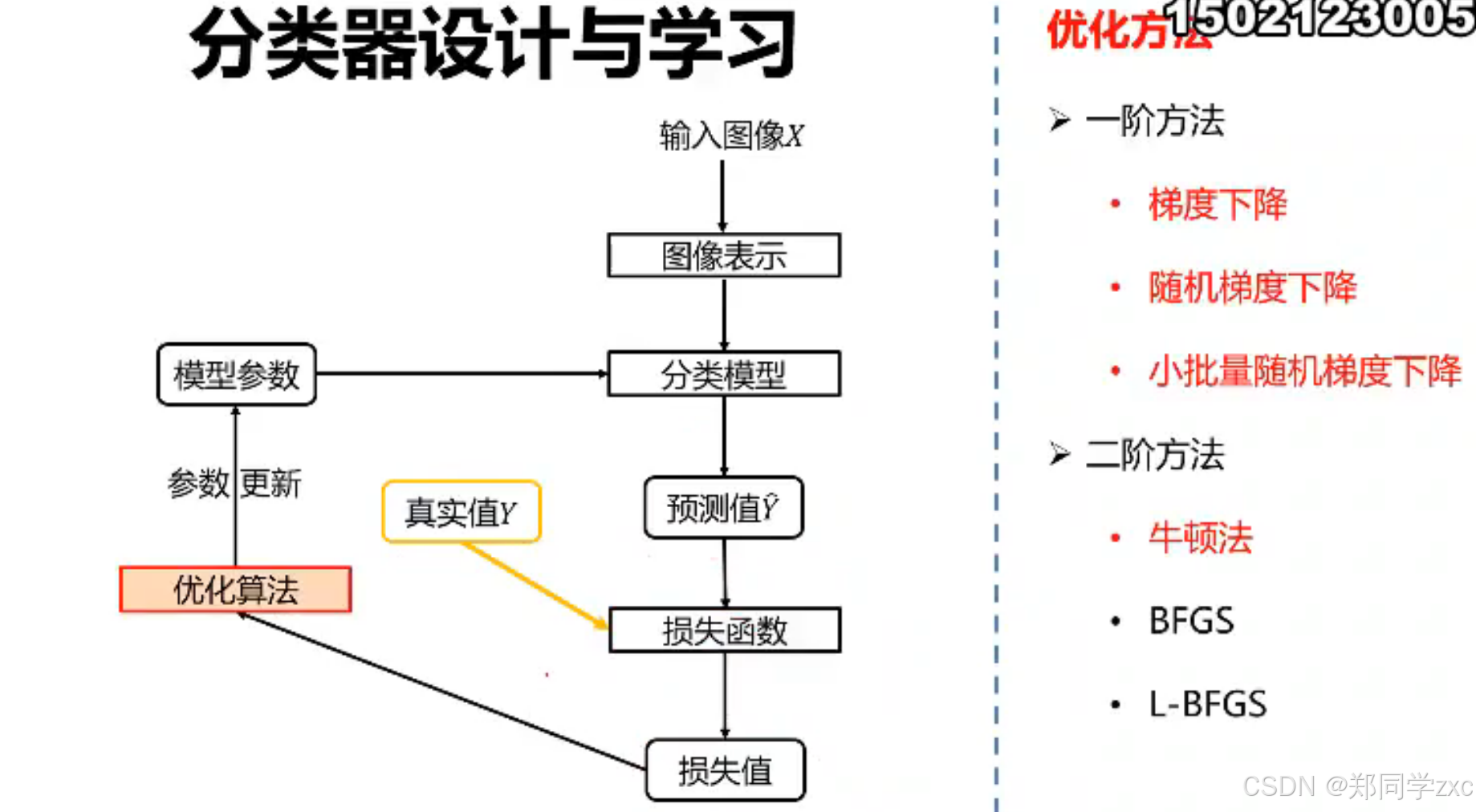
- 深度学习模型训练:以卷积神经网络(CNN)为例,在ImageNet数据集上进行图像分类任务的训练。ImageNet包含数百万张标注了上千个类别的图像。首先,将图像输入到CNN中,通过卷积层、池化层等层次结构自动提取图像的特征,如边缘、纹理、形状等。然后,通过全连接层将这些特征映射到各个类别上,最后使用反向传播算法和优化器(如随机梯度下降)根据标注数据对模型的参数进行优化,使模型能够准确地对图像进行分类。经过大量数据的训练后,该CNN模型可以对新的输入图像进行分类,例如,输入一张从未见过的动物照片,模型能够根据在ImageNet上学习到的特征和分类规律,将其准确地分类到相应的动物类别中。
- 迁移学习:也是数据驱动范式的一种应用。例如,已经在大规模通用图像数据集上训练好的图像分类模型(如在ImageNet上训练的ResNet模型),可以将其迁移到特定领域的图像分类任务中。对于一个医学图像分类任务(如肺部疾病分类),由于医学图像数据相对较少且标注成本高,可以利用在大规模通用数据上学习到的特征表示,然后在少量的医学图像数据上进行微调(fine-tuning),使模型能够适应医学图像的分类任务。这种方法利用了大量通用数据的信息,同时通过少量特定领域数据的微调,实现了高效的数据驱动的图像分类。

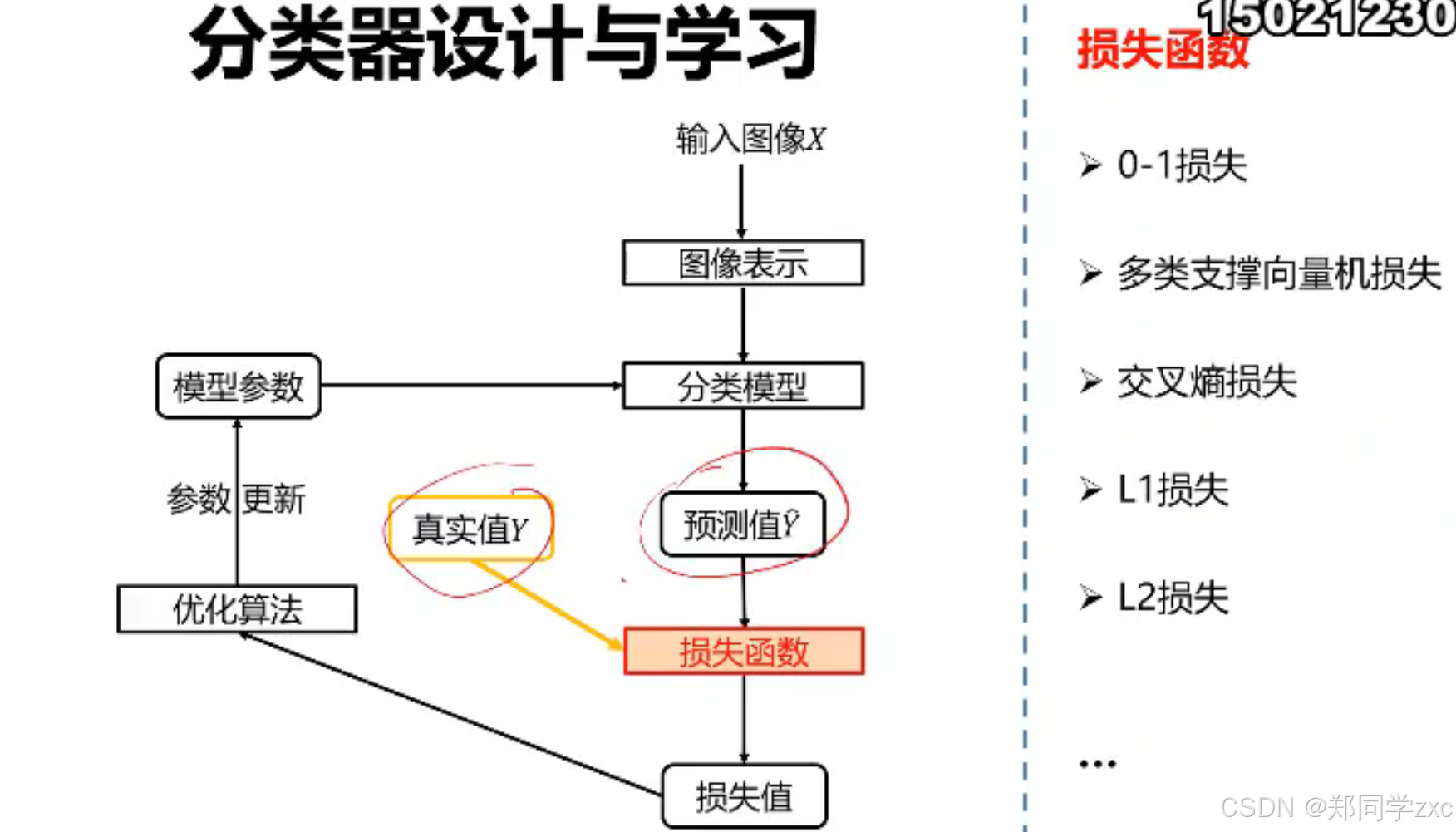
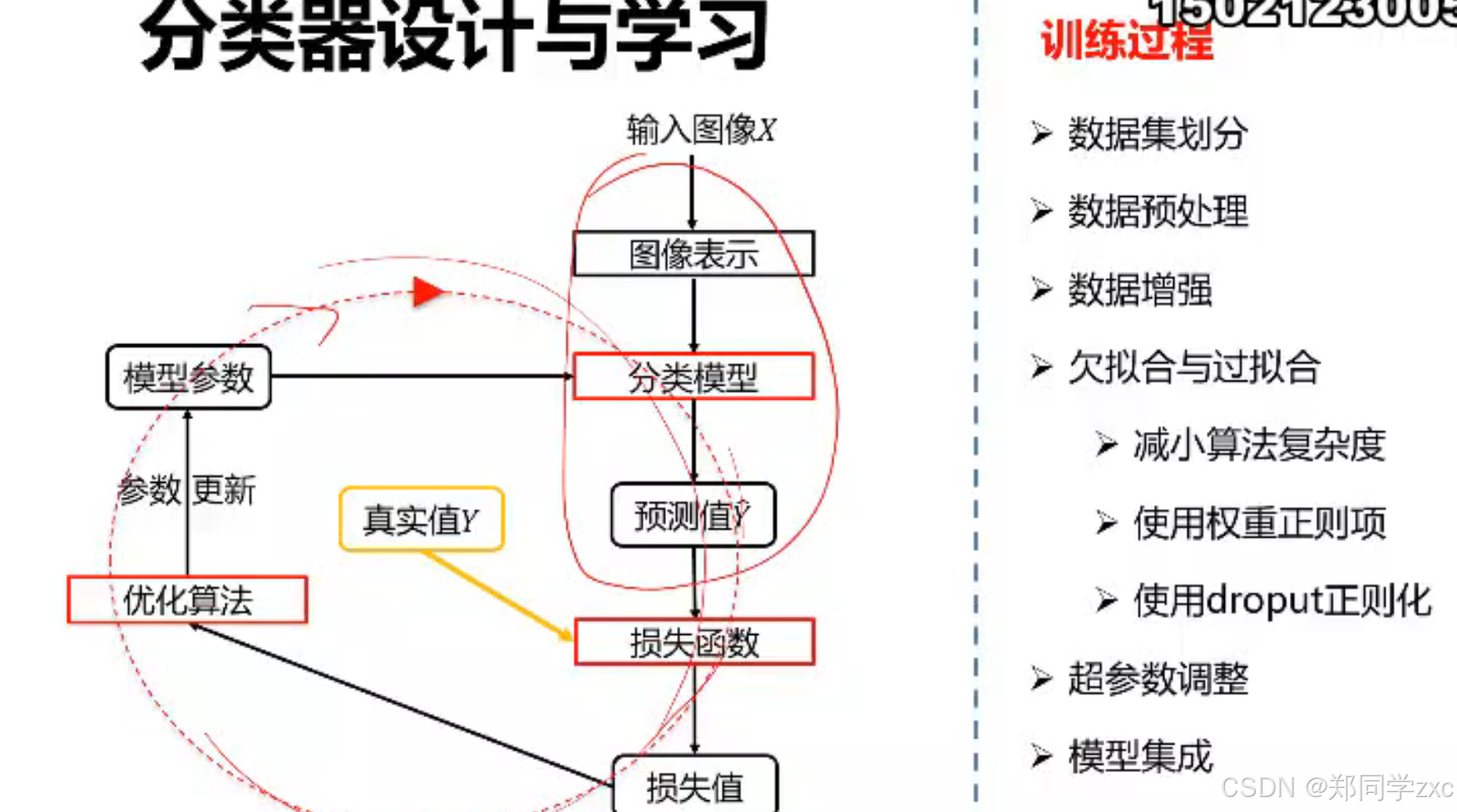
5. 常用分类任务评价标准指标
- 准确率(Accuracy):是最直观的评价指标,定义为正确分类的样本数占总样本数的比例。例如,在一个包含100张图像的测试集中,模型正确分类了80张图像,则准确率为80%。准确率适用于各类别样本数量相对均衡的情况,但在数据不平衡时可能会产生误导,因为模型可能只是对多数类的分类效果好,而对少数类的分类效果不佳,但整体准确率仍然较高。
- 精确率(Precision):对于每个类别,精确率是指被预测为该类别的样本中真正属于该类别的比例。例如,在一个二分类问题(正类和负类)中,模型预测为正类的样本有50个,其中真正为正类的有40个,则正类的精确率为40 / 50 = 80%。精确率关注的是模型预测为正类的准确性,常用于对误报(False Positive)比较敏感的场景,如医疗诊断中,误将健康人诊断为患者(假阳性)可能会带来不必要的后续检查和患者的心理负担。
- 召回率(Recall):也称为查全率,是指实际为该类别的样本中被正确预测为该类别的比例。继续以上述二分类为例,实际为正类的样本有60个,模型正确预测为正类的有40个,则正类的召回率为40 / 60 ≈ 66.7%。召回率关注的是模型对该类别样本的覆盖程度,常用于对漏报(False Negative)比较敏感的场景,如在欺诈检测中,漏报欺诈行为(假阴性)可能会导致严重的经济损失。
- F1值(F1 - Score):是精确率和召回率的调和平均值,综合考虑了精确率和召回率。计算公式为F1 = 2 * (Precision * Recall) / (Precision + Recall)。F1值在精确率和召回率都重要的情况下是一个比较好的综合评价指标,例如在信息检索中,既希望检索结果准确(高精确率),又希望尽可能多地召回相关文档(高召回率),此时F1值可以更全面地评价检索系统的性能。
- 混淆矩阵(Confusion Matrix):是一个矩阵,用于展示分类模型在每个类别上的预测结果。矩阵的行表示实际类别,列表示预测类别。通过混淆矩阵可以直观地看出模型在不同类别上的分类情况,例如哪些类别容易被误分类,以及误分类的具体情况。例如,在一个三分类问题(类别A、B、C)的混淆矩阵中,可以看到实际为A类但被预测为B类、C类的样本数量,以及其他类别之间的混淆情况,从而帮助分析模型的优缺点,以便进行针对性的改进。

















 3155
3155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









