




LangChain
- LangChain是一个帮助在应用程序中使用大型语言模型的编程框架。同时也是企业名称,由创始人哈里森·蔡斯和安库什·戈拉于2023在美国加利福尼亚州创建的AI公司。Harrison Chase担任首席执行官。
- LangChain简化了LLM应用生命周期的每个阶段:
开发:利用LangChain的模块和组件来构建应用程序。通过与第三方集成和模板可迅速搭建一个项目。
生产化:使用LangSmith来检查、监控和评估你的chains,这样你就可以持续优化,并充满信心地部署。
部署:通过LangServe将任何chains转换成 API。
简单来说就比如
聊天用的:聊天组件
提示词模板
记忆
文档的加载+文档的分隔
向量的存储
更直白点:LangChain 提供了一套工具、组件和接口,简化了与语言模型交互的过程,并允许将语言模型与其他数据源和工具连接起来。
那我们为什么要使用LangChain呢?
- 数据连接:Langchain允许你将大型语言模型连接到你自己的数据源,比如数据库、PDF文件或其他文档。这意味着你可以使模型从你的私有数据中提取信息。
- 行动执行:不仅可以提取信息,Langchain还可以帮助你根据这些信息执行特定操作,如发送邮件。无需硬编码:它提供了灵活的方式来动态生成查询,避免了硬编码的需求
LangChain生态
- LangSmith:调试、测试、评估和监控应用程序,并与LangChain无缝集成。
- langGraph:用于编排复杂任务流程或工作流。构建健壮且有状态的多⻆色应用程序。
- langserve:部署LangChain链作为REST APIs。
LangChain主要组件
- Models:模型,各种类型的模型和模型集成,比如GPT-4
- Prompts:提示,包括提示管理、提示优化和提示序列化
- Memory:记忆,用来保存和模型交互时的上下文状态
- Indexes:索引,用来结构化文档,以便和模型交互
- Chains:链,一系列对各种组件的调用
- Agents:代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止
演示
我们先在这个项目中创建如下几个文件夹和文件
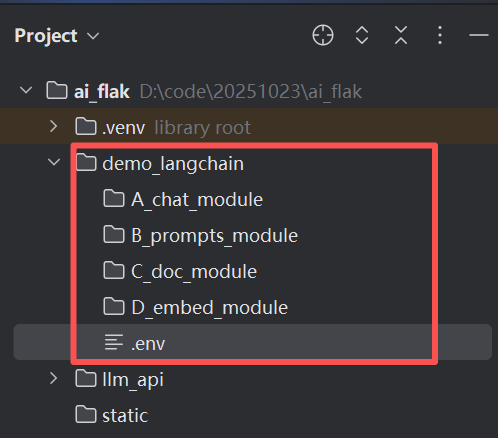
然后安装对应的依赖:
ip install langchain
pip install langchain-core
pip install langgraph>0.2.27
pip install -qU"langchain[openai]"
pip install -U langchain-deepseek
pip install langchain-community pypdf
pip install docx2txt
pip install -qU langchain-chroma # 向量库chroma
pip install -qU faiss-cpu # 向量库faiss

如上,我们逐步安装完成即可
我们可以使用pip list查看是否都安装成功
LangSmith
是LangChain的一个监控、日志平台
我们首先要去官网进行注册
官网地址:https://smith.langchain.com/
我们使用QQ邮箱注册
登录邮箱去确认邮箱即可
然后中间确认角色等过程一律skip
然后点击设置
点击+API Key
然后我们创建我们自己的密钥就可以了
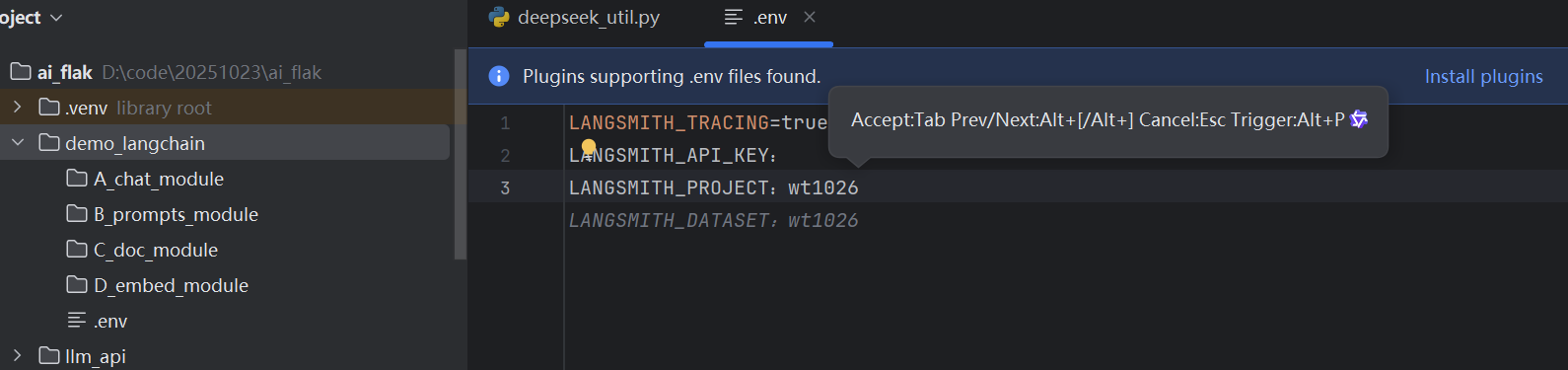
然后我们去代码里面配置我们的密钥相关信息
LANGSMITH_TRACING=true:表示启用跟踪(即启用LangSmith日志)
LANGSMITH_API_KEY:上面申请的秘钥LANGSMITH_PROJECT:项目的名称,随意填写
正常来讲,当我们运行之后,这里会显示我们运行的过程
那我们同时也配置上OpenAI和DeepSeek的秘钥,如下:
OPENAI_API_KEY=sk-UTMrYlOnkmtwiclzpQYiYaS
OPENAI_API_BASE=https://api.chat
DEEPSEEK_API_KEY=sk-ee2df75adfcc462
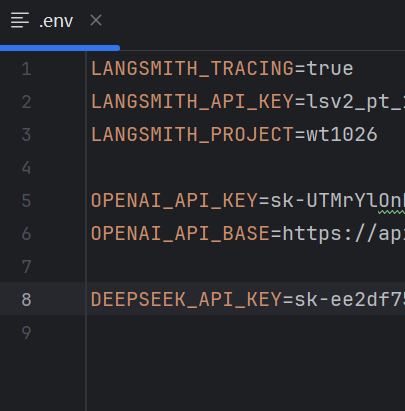
环境变量如上,我们配置完毕
LangChain主要组件介绍
聊天组件
我们创建demo1.py文件
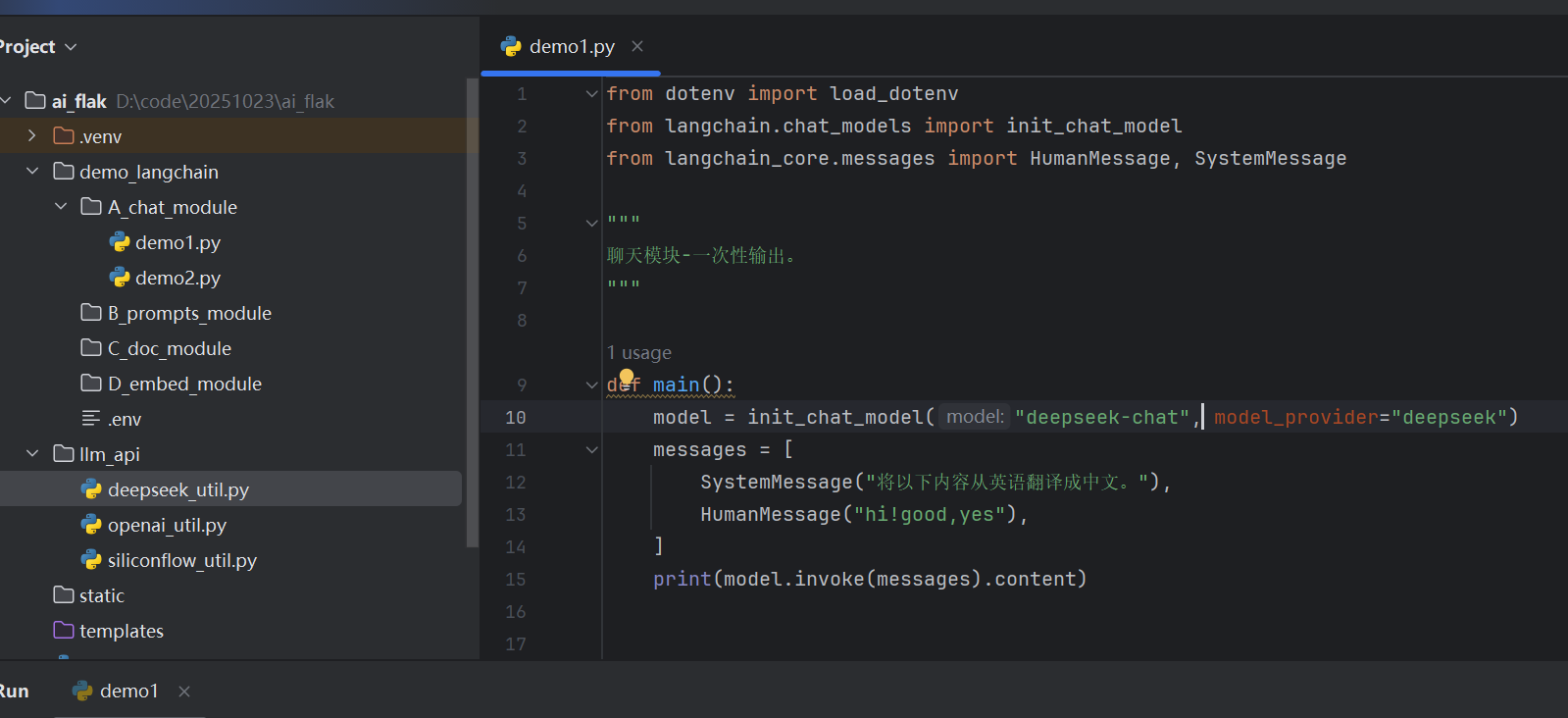
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, SystemMessage
"""
聊天模块-一次性输出。
"""
def main():
model = init_chat_model("deepseek-chat", model_provider="deepseek")
messages = [
SystemMessage("将以下内容从英语翻译成中文。"),
HumanMessage("hi!good,yes"),
]
print(model.invoke(messages).content)
if __name__ == '__main__':
load_dotenv()
main()
运行之后,我们发现,它是可以翻译成功的

在运行过程中,它自己会去加载环境变量,然后去运行
上面这个demo1是一次性输出,当然,我们也可以做到流式输出,说直白点就是一个字一个字的往外输出,我们创建demo2.py文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2025/10/26 13:33
@Author : nian_nian
@File : demo2.py
@Desc :
"""
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, SystemMessage
"""
聊天模块-流式输出。
"""
def main():
model = init_chat_model("deepseek-chat", model_provider="deepseek")
messages = [
SystemMessage("你是一个高级中学的语文老师,你的作文写的很牛逼。"),
HumanMessage("请以《奉献》为题,写一篇400的作文"),
]
# print(model.invoke(messages).content)
for token in model.stream(messages):
print(token.content)
if __name__ == '__main__':
load_dotenv()
main()
运行过程如下:
照片看不出来效果,自己可以尝试下
提示词模板
我们在模板单元文件里面创建demo1.py文件,内容如下:
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate
"""
提示词模版模块。
"""
def main(text):
model = init_chat_model("deepseek-chat", model_provider="deepseek")
system_template="将以下内容从英语翻译成{language}"
prompt_template = ChatPromptTemplate.from_messages(
[
("system", system_template), ("user", "{text}")
]
)
prompt = prompt_template.invoke({
'language': '日语', 'text': text})
print(model.invoke(prompt).content)
if __name__ == '__main__':
load_dotenv()
main('你好')
将我们输入的内容,翻译成日语的一个模板
运行结果我们看下:

文档加载
加载PDF文件
from langchain_community.document_loaders import PyPDFLoader
def load_pdf():
loader = PyPDFLoader('sq_pdf.pdf')
docs = loader.load()
print('文档的长度', len(docs))
print('第一部分内容', docs[0].page_content)
if __name__ == '__main__':
load_pdf()
运行之后的结果如下:
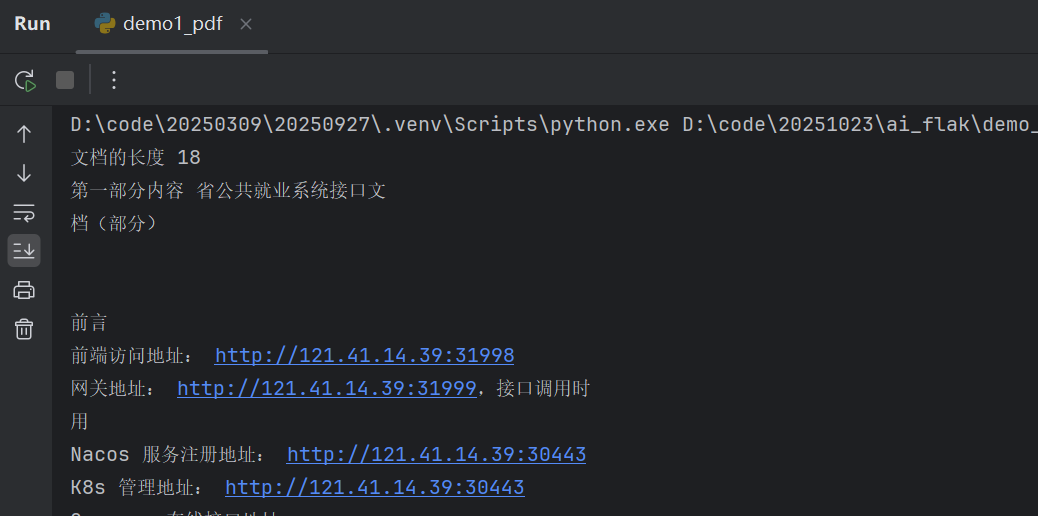
我们可以看到,它正常读出来了PDF文件的内容,同时,它也可以实现,对文章内容进行分段处理
加载word文件
from langchain_community.document_loaders import Docx2txtLoader
def load_word():
loader = Docx2txtLoader('sq_word.docx')
docs = loader.load()
print('文档的长度', len(docs))
print('第一部分内容', docs[0].page_content)
if __name__ == '__main__':
load_word()
运行之后的结果:
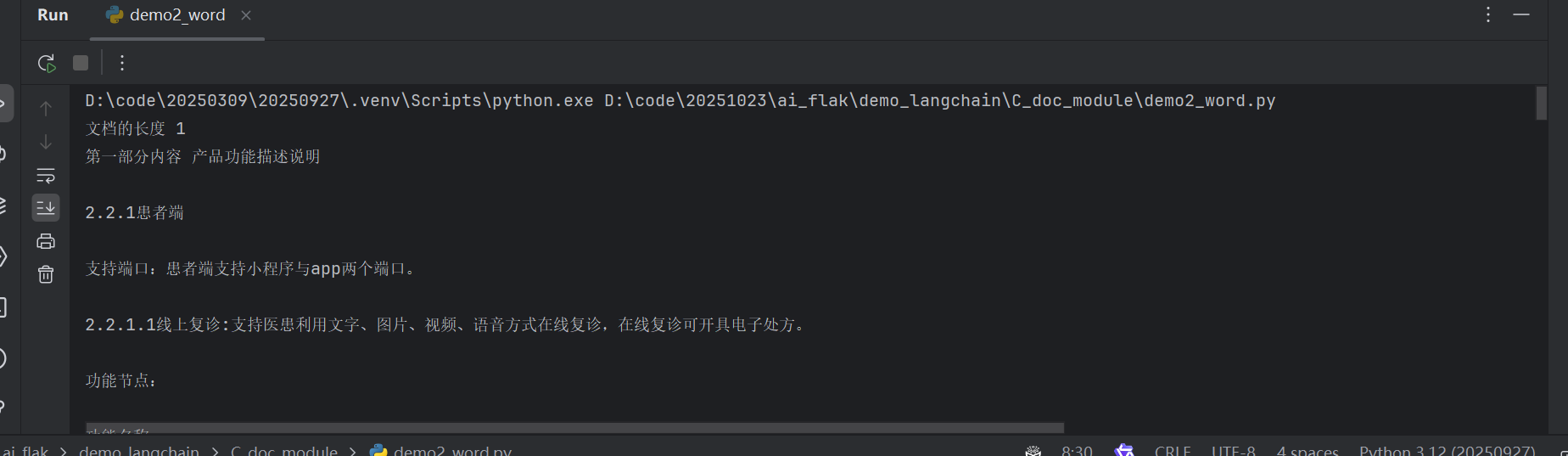
我们可以看到,word文档里面的内容也被读取了出来
接下来我们专门看下文件的分隔:
我们先写一段代码:
from langchain_text_splitters import CharacterTextSplitter
text_spliter = CharacterTextSplitter(
separator=' ', # 使用空格作为分割符
chunk_size=10, # 指明每个分割文本块的大小
chunk_overlap=3, # 指明每个分割后的文档之间的重复字符个数
)
result=text_spliter.split_text('AB CD EF GH IJKLMNOPQRST UVWXYZ1234567890')
print(result)
我们先看下运行的结果:

我们可以看到,并不是所有的元素,都是正好等于10
第一个元素,加上空格,正好等于10
第二个元素,很明显不等于10,因为,如果要等于10,那么就需要对下一个元素进行分割,很明显,下一个元素不能被分隔。举个例子,我们在日常生活中的很多单词,如果我们进行了分隔,那么,他的含义很显然就会发生变化,所以这种结果正常来讲,是我们想要的。
存储到向量库与检索查询
关于文本转换向量,我们只提供几个代码文件,大家可以看下
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
"""
将文本转换成向量
"""
def embed_txt():
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vector1=embeddings.embed_query('小米')
vector2=embeddings.embed_query('小米')
print(vector1)
print(vector2)
print(vector1 == vector2) # 同样的内容,向量化后,结果可能一样,也可能不一样,如果不一样,也会很相近。
print(len(vector1)==len(vector2))
print(len(vector2))
if __name__ == '__main__':
load_dotenv()
embed_txt()
import os
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
"" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











