







1.本文以pycharm为编辑器,爬取搜狐新闻的网页信息
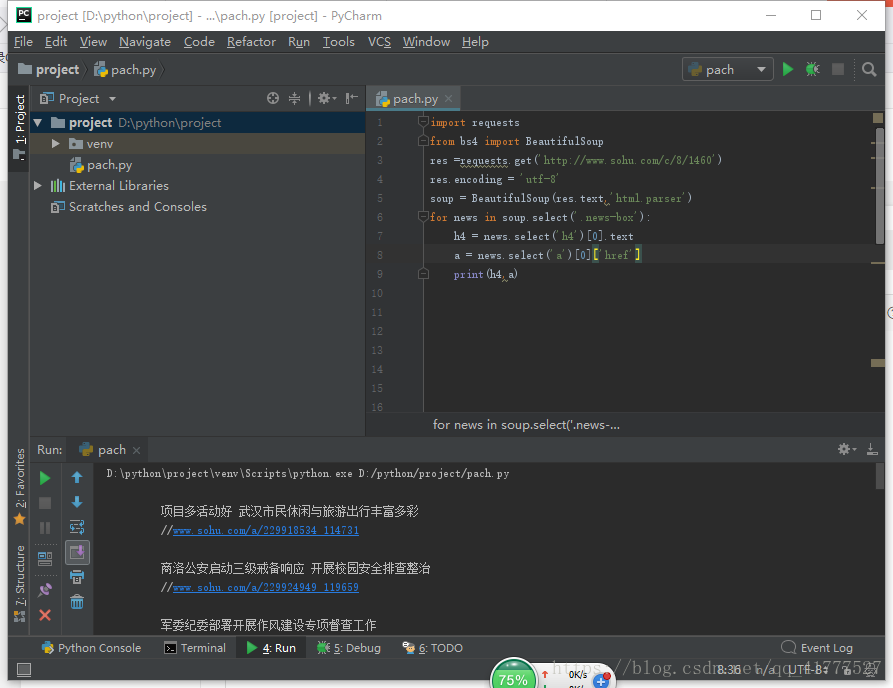
2.具体代码如下
import requests from bs4 import BeautifulSoup res =requests.get('http://www.sohu.com/c/8/1460') #防止中文内容乱码 res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #对网页内容进行爬取 #查看网页代码,看标题在哪个位置,本文以搜狐新闻为例,他的标题是在class=news-box里面 for news in soup.select('.news-box'): #获取文本标题 h4 = news.select('h4')[0].text #获取连接 a = news.select('a')[0]['href'] print(h4,a)3.注意要先搞清楚自己要的信息在哪里。

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









