







 本文详细介绍了如何启动、重载配置和优雅关闭Prometheus进程,包括启动参数的解析,如使用web.enable-lifecycle功能通过HTTP操作,以及如何调整时区。还展示了如何通过API进行健康检查和数据查询示例。
本文详细介绍了如何启动、重载配置和优雅关闭Prometheus进程,包括启动参数的解析,如使用web.enable-lifecycle功能通过HTTP操作,以及如何调整时区。还展示了如何通过API进行健康检查和数据查询示例。
一、start、reload 与 shutdown
1、启动prometheus 进程
nohup ./prometheus --config.file=prometheus.yml > prometheus.log 2>&1 &
2、重载prometheus配置文件(reload)
kill -s SIGHUP <PID>
3、优雅的shutdown一个prometheus 进程实例
kill -s SIGTERM <PID>
二、 prometheus 启动参数详解
| 选项 | 默认值 | 描述 |
|---|---|---|
| -h --help | 帮助 | |
| –version | 打印版本 | |
| –config.file | prometheus.yaml | 配置文件路径,主要是配置抓取的endpoint的配置,即prometheus.yaml配置文件 |
| –web.listen-address | 0.0.0.0:9090 | 监听端口即web UI 端监听端口和 API端监听端口 |
| –web.enable-lifecycle | false | 启用通过http来reload配置文件和shutdown服务的功能 |
| –web.enable-admin-api | false | 启用HTTP API管理控制 |
| –web.page-title | Prometheus Time Series Collection and Processing Server | prometheus 服务实例的title |
| –web.console.templates | consoles | console template(管理端静态页面路径) |
| –query-timout | 2m | 一次查询的最大超时时间,默认2分钟(2m),只适用于server mode下 |
| –query.max-concurrency | 20 | 最大并发查询数量,默认20,只适用于server mode下 超出的并发数量会怎么样? |
| –log.level | info | 日志等级,默认info,可选值为[debug,info,warn,error] |
| –log.format | logfmt | 日志格式,默认logfmt 可选值[logfmt,json] |
三、实践
1、–web.enable-lifecycle
启用通过http来reload配置文件和shutdown服务的功能
# reload配置文件,并不会重启服务
curl -X PUT http://10.240.184.81:9090/-/reload
# shutdown服务
curl -X PUT http://10.240.184.81:9090/-/quit
2、–web.page-title
默认值 Prometheus Time Series Collection and Processing Server
可以通过设置 –web.page-title=hello改成 hello

3、–web.enable-admin-api 启用HTTP API管理控制
[kyzjj@yyzc-zjjcs04 ~]$ curl -X GET http://10.240.184.81:9090/-/healthy
Prometheus Server is Healthy.
[kyzjj@yyzc-zjjcs04 ~]$
[kyzjj@yyzc-zjjcs04 ~]$ curl -X GET http://10.240.184.81:9090/-/ready
Prometheus Server is Ready.
[kyzjj@yyzc-zjjcs04 ~]$ curl -X GET http://10.240.184.81:9090/api/v1/query?query=node_filesystem_files_free
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"node_filesystem_files_free","device":"/dev/mapper/vg_app-lv_kyzjj","fstype":"xfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/kyzjj"},"value":[1709356667.786,"20940287"]},{"metric":{"__name__":"node_filesystem_files_free","device":"/dev/mapper/vg_root-lv_root","fstype":"xfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/"},"value":[1709356667.786,"15433370"]},{"metric":{"__name__":"node_filesystem_files_free","device":"/dev/mapper/vg_root-lv_tmp","fstype":"xfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/tmp"},"value":[1709356667.786,"10485744"]},{"metric":{"__name__":"node_filesystem_files_free","device":"/dev/vda1","fstype":"xfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/boot"},"value":[1709356667.786,"1048246"]},{"metric":{"__name__":"node_filesystem_files_free","device":"rootfs","fstype":"rootfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/"},"value":[1709356667.786,"15433370"]},{"metric":{"__name__":"node_filesystem_files_free","device":"tmpfs","fstype":"tmpfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/run"},"value":[1709356667.786,"483795"]},{"metric":{"__name__":"node_filesystem_files_free","device":"tmpfs","fstype":"tmpfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/run/user/0"},"value":[1709356667.786,"485287"]},{"metric":{"__name__":"node_filesystem_files_free","device":"tmpfs","fstype":"tmpfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/run/user/2411"},"value":[1709356667.786,"485285"]},{"metric":{"__name__":"node_filesystem_files_free","device":"tmpfs","fstype":"tmpfs","instance":"localhost:9100","job":"prometheus---node","mountpoint":"/run/user/370"},"value":[1709356667.786,"485287"]}]}}[kyzjj@yyzc-zjjcs04 ~]
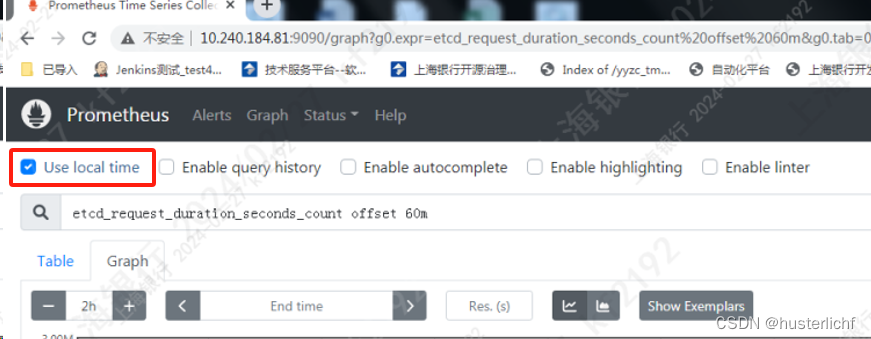
4、使用本地时区
prometheus默认使用UTC+0时区,但是中国使用东八区时区即UTC+8,可以设置使用本地时区,设置方式如下:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









