









 该博客探讨了传统词汇替换方法的局限性,如依赖同义词且忽视对整个文本的影响。提出了一种新的方法,通过BERT模型的embedding dropout技术平衡目标词的语义和上下文信息。在完全遮盖目标词的情况下,候选词可能在保持上下文连贯性的前提下与原词意义不同。计算相似度时,使用了BERT前四层表示的拼接。推荐系统结合了词的似然和句子的余弦相似度。
该博客探讨了传统词汇替换方法的局限性,如依赖同义词且忽视对整个文本的影响。提出了一种新的方法,通过BERT模型的embedding dropout技术平衡目标词的语义和上下文信息。在完全遮盖目标词的情况下,候选词可能在保持上下文连贯性的前提下与原词意义不同。计算相似度时,使用了BERT前四层表示的拼接。推荐系统结合了词的似然和句子的余弦相似度。
摘要:
之前的词汇替换是通过查询目标词汇的同义词来实现的(e.g. WordNet), 然后基于文本对候选词打分。这种方法有两个限制:
-
忽略了不是同义词的但是效果很好的候选词汇
-
没有考虑同意替换对整个文本的影响
主体:
对目标词进行embedding dropout,使得可以平衡目标词的语义信息和上下文信息。
如果完全遮盖,返回的候选词可能与原词意思不同,却能满足上下文信息;
如果不遮盖,返回的候选词大约99.99%会预测到原词。
计算相似度时,将BERT前四层的表示做拼接来计算相似度。
推荐时使用了词的似然和句子的余弦相似度求和:
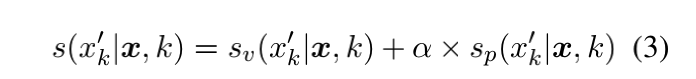
Reference:
Zhou, W., Ge, T., Xu, K., Wei, F., & Zhou, M. (2019, July). BERT-based lexical substitution. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 3368-3373).


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









