




 本文探讨了Spark Streaming在处理Kafka数据流时的Direct消费模式,对比Receiver模式,Direct模式展现了更低的资源和内存需求,更强的鲁棒性和简化offset管理。通过checkpoint机制,实现了任务状态的持久化,确保了数据处理的连续性和一致性。
本文探讨了Spark Streaming在处理Kafka数据流时的Direct消费模式,对比Receiver模式,Direct模式展现了更低的资源和内存需求,更强的鲁棒性和简化offset管理。通过checkpoint机制,实现了任务状态的持久化,确保了数据处理的连续性和一致性。
我的博客都是在开发过程中遇到问题,和学习到的经验,写出来,跟大家分享,写博客这个事情还是非常感谢上一家公司的领导对我教诲,虽然很严厉但是对我的帮助和成长真的很大,虽然很可惜离开了,但是还是很感谢,我的年龄其实不大,开发和工作经验不多还是学习阶段。如果哪里有写不对的地方还请帮忙指认出来。
上一章节中我们提到了sparksteaming的检查点机制,我觉得只要是流式计算都会涉及数据安全性的问题,对于spark这样的计算引擎也会有相应的措施,这就是sparkstreaming的检查点机制checkpoint,这个其实简单来说就是定时对DSteam的一个持久化,也是将RDD进行序列化和反序列化的一个过程,如果有了checkpoint,每次sparkStreaming启动的时候都会到hdfs上面的checkpoint路径找到相应rdd偏移量然后恢复处理任务。接下来将详细讲解checkpoint的使用和简单介绍
我这里是sparkstreaming链接kafka进行流式数据处理,spark链接kafka有两种链接方式一种是Receiver消费模式,一种是Direct消费模式,我们这里用到的是Direct消费模式,这种方式就是不需要专门接受者来持续不断读取数据,当batch任务出发时,有Executor读取数据,并参与到其他Executor的计算中去,driver来决定读取多少offset,并将offset交由checkpoints来维护,在这里这样下次触发batch任务时,就由Executor来读取kafka数据并计算;所以这种方式消费内存的要求不高,只需要考虑批量计算所需要的内存即可,另外batch任务堆积时也不会影响数据堆积。与receivers方式相比,direct方式我觉得更可取一点,
第一:降低资源,direct不需要receiver,因为申请的executors全部都参与到计算任务中了,而receiver则需要专门的receivers来读取kafa数据病区不参与计算,因此相同的资源申请,direct能够支持更大的业务。
第二:降低内存,receiver与其他exectuor是异步的,并持续不断接受数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高receiver,而是在计算时读取数据,然后直接计算,所以对内存的要求很低。
第三:鲁棒性更好。receiver方法需要receiver来异步持续不断的读取数据,因此遇到网络,存储负载等因素,导致实时任务出现堆积,但receivers却还在持续读取数据,很容易导致计算崩溃,direct没有这个顾虑,只有diver触发batch计算任务时,才会读取数据并计算,就算队列出现堆积也不会引起程序失败。
而却direct采用的是checkpoint第三方维护offsets,节省了很多的开发成本
如下图所示这里是我创建DStream的方式:
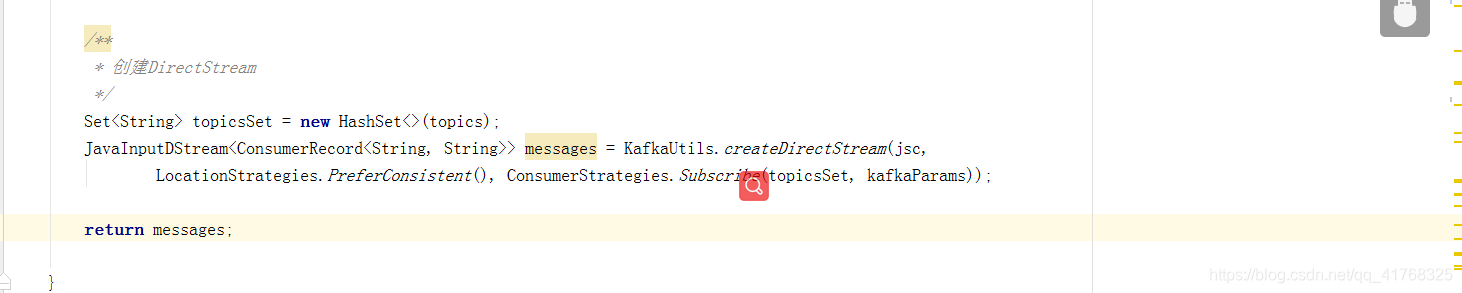
LocationStrategies.PreferConsistent()这个意思是将分区分布到所有可获得的exectuor上,新的kafka的消费者API可以预获取消费缓存到缓冲区,因此spark整合kafka让消费者在executor上进行缓存,并且从获取的offset初始化Kafka Direct DStream,对性能是非常有帮助的。
接着就是spark来存储偏移量了,我们这里用checkpoint来存储,网上面有很多资料可以参考,但是按照上面来做的话也是本地运行可以成功,但是一到集群上面就就不行,有的说是因为集群没有安装scala,还有的错误是说项目的spark版本和集群的不一致导致的,为了保险起见我又在集群上面安装了一个scala,然后查看官网,结果官网上面说的跟别的博客上面说的都差不多,
有点郁闷了,然后看到了一个连接,上面说这是个java的示例,然后我就点了进去:
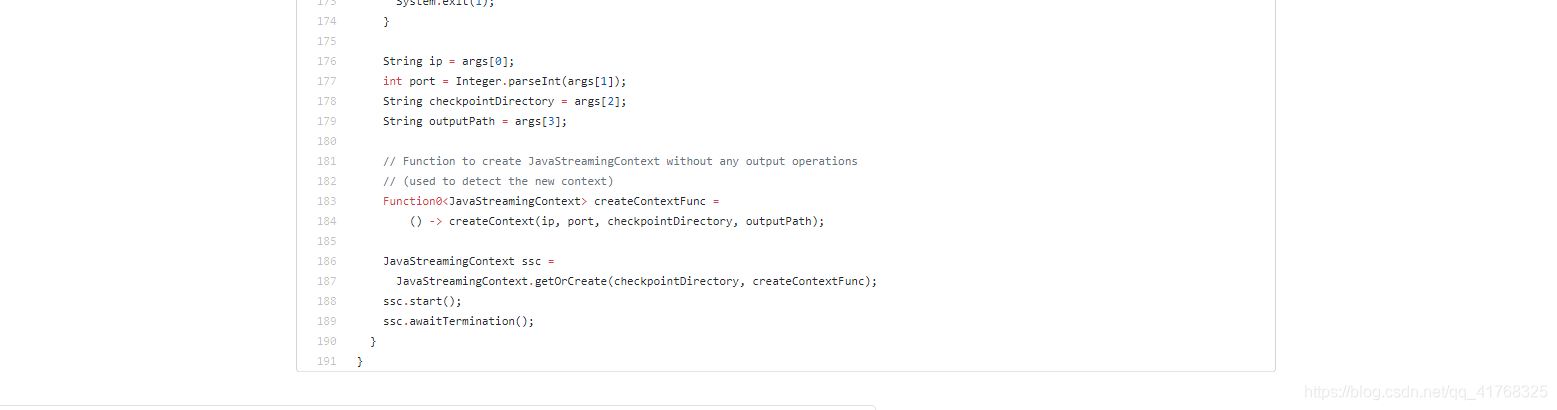
前面一堆代码没怎么看,因为我的目的是checkpoint,所以目光定位到这里,
Function0<JavaStreamingContext> createContextFunc =() -> createContext(ip, port, checkpointDirectory, outputPath);
这行代码解决了集群运行报错问题,当然createContext这个方法需要符合自己的业务需求去修改,因为我之前是按官网搞得
JavaStreamingContextFactory contextFactory = new JavaStreamingContextFactory() {
@Override public JavaStreamingContext create() {
JavaStreamingContext jssc = new JavaStreamingContext(...); // new context
JavaDStream<String> lines = jssc.socketTextStream(...); // create DStreams
...
jssc.checkpoint(checkpointDirectory); // set checkpoint directory
return jssc;
}
};
sparkstreaming2.1.1的jar包里面没有JavaStreamingContextFactory()这个类,在sparkstreaming2.1.0里面有,所以就容易报类不存在,并且构建JavaStreamingContext需要使用JavaStreamingContext.getOrCreat这个方法因为这样的话当程序初始化运行的时候回到hdfs的目录下面找相应的rdd偏移量,如果没有的话会新创建一个,下次运行的时候就会从相应的最新偏移量中恢复数据进行计算,对于DStream的存储时间间隔官网推荐的是窗口时间的5-10倍,因为这个操作需要消耗计算内存的,所以我设置的是100秒。
改完代码之后在集群上用了spark官网里面的java代码示例之后运行程序没有报错,而且强制把程序停下之后又重新启动时,rdd的数据是从checkpoint的hdfs地址里面找到最新的偏移量进行的数据恢复。
checkpoint也是优点缺点并存的
1.若流式程序代码或配置改变,则先停掉之前的sparkstreaming程序,然后把新打包编译后重新执行会照成两种情况:
1,启动报错,反序列化异常。
2.启动正常,但是可能运行的代码是上一次的旧程序代码。
这是因为checkpoint第一次持久化时会把整个相关程序的jar包给序列化成一个二进制文件,每次启动都会从checkpoint目录中恢复,即时把新的程序打包序列化加载的仍然是旧的序列化二进制文件,
会导致报错或者依旧执行旧代码程序。
若直接把上次的checkpoint删除,当启动新的程序时,只能从kafka的smallest或largest的偏移量消费。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











