







一. KNN 算法简介
K-近邻((k-Nearest Neighbors))算法可以说是最简单的机器算法。构建模型只需要保存训练数据集即可。想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”。该算法的思想是一个样本与数据集中的k个样本最相似,如果这k个样本中的大多数属于某一个类别,则该样本也属于这个类别。
二. 算法构造
(1) 计算测试数据与各训练数据之间的距离;
(2) 对距离进行升序排列;
(3) 选取距离最小的K个点;
(4) 计算前K个点各自类别的出现频率;
(5) 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
三. 算法细节实现
1.生成数据集(加载鸢尾花数据集)

以下是生成的数据及类别数据


2.获取训练集测试集

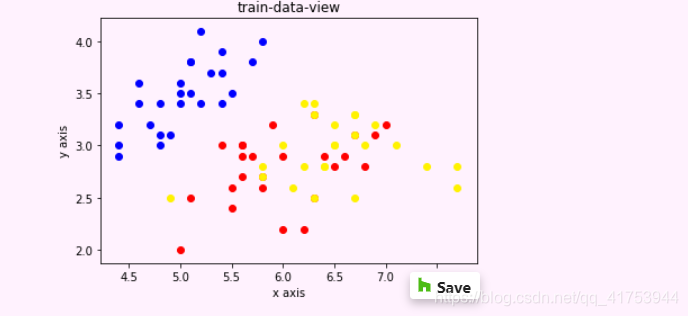
3 .构建模型(绘制训练集散点图)
4.KNN 算法处理过程
(1).新增一个点
绘制新增点后的散点图
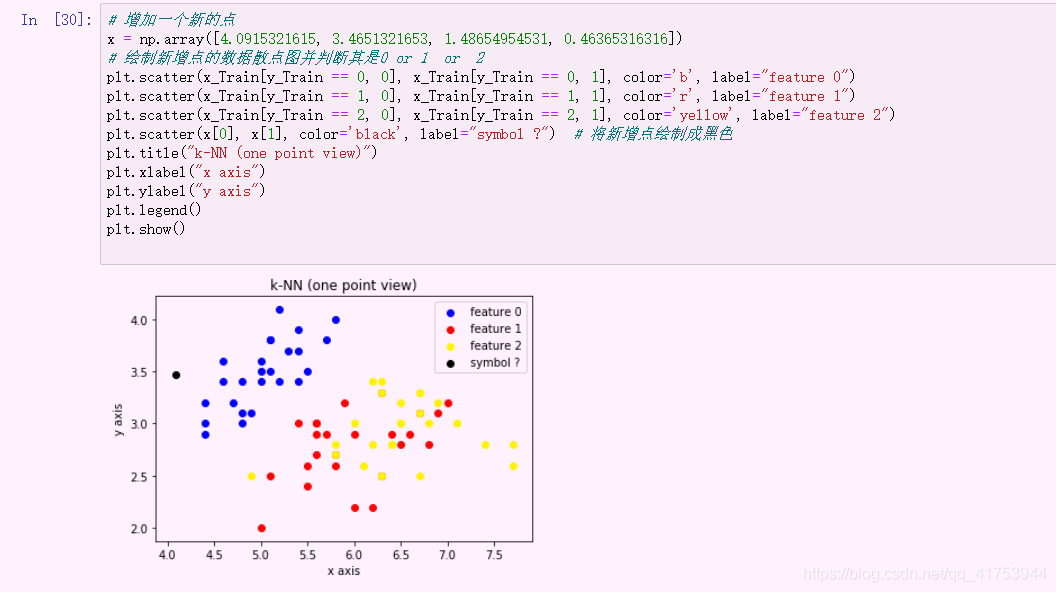
图中黑色的点是所需预测的数,利用距离得出离他最近的点的类别以此来进行分类
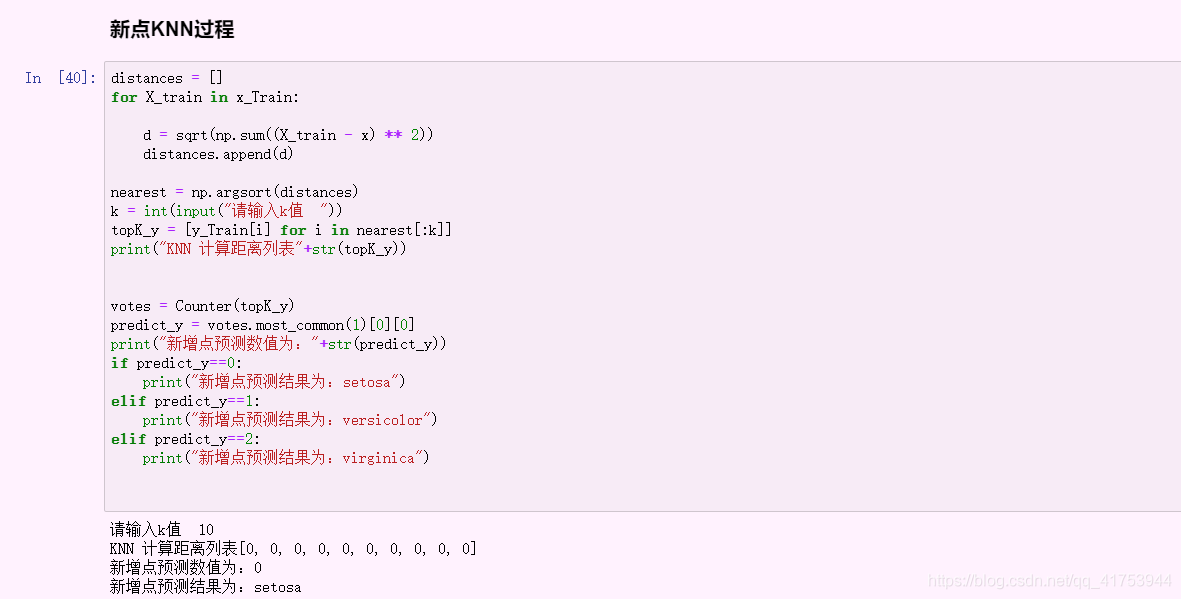
以下是算法及注释
5.使用测试集数据进行算法精度评估
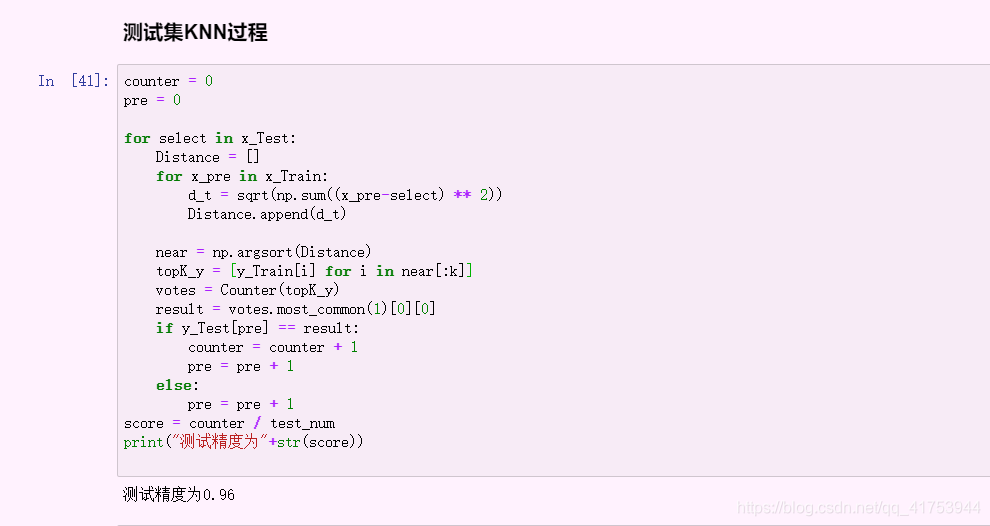
即将测试集的各个点代用算法距离公式,实现分类决策
四.算法优劣
优点:
(1) 精度高;
(2) 对异常值不敏感。
缺点:
(1) 计算复杂度高;
(2) 空间复杂度高。
适用数据范围:
数值型和标称型
五.经验总结
由于不熟悉numpy 和matplotlib的函数,在相关的功能实现上费了很大功夫,但也学会了相关的知识。在手写KNN 算法的基础上进一步理解了KNN算法的思想。
附源碼:
# coding:utf-8
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from math import sqrt
from collections import Counter
test_num = 75 # 测试数据个数
# 源数据的产生(加载sklearn鸢尾花数据集)
datas = load_iris()
# 使用切片获取150组鸢尾花数据(datas['data']为data key 值对应数据,即鸢尾花花瓣花萼数据)
raw_data_x = datas['data'][0:150]
# 表示鸢尾花的类别(K-NN算法处理基于监督学习的分类问题)
# 0表示setosa类 ,1 表示versicolor类 ,2表示virginica 类
raw_data_y = datas['target'][0:150]
# 产生训练集(源数据的百分之50)
x_Train = raw_data_x[0:150:2]
y_Train = raw_data_y[0:150:2]
# 产生测试集(源数据的百分之50)
x_Test = raw_data_x[1:150:2]
y_Test = raw_data_y[1:150:2]
print(raw_data_x)
print(raw_data_y)
plt.scatter(x_Train[y_Train == 0, 0], x_Train[y_Train == 0, 1], color='b', label="feature 0")
plt.scatter(x_Train[y_Train == 1, 0], x_Train[y_Train == 1, 1], color='r', label="feature 1")
plt.scatter(x_Train[y_Train == 2, 0], x_Train[y_Train == 2, 1], color='yellow', label="feature 2")
plt.title("train-data-view")
plt.xlabel("x axis")
plt.ylabel("y axis")
plt.show()
# 增加一个新的点
x = np.array([4.0915321615, 3.4651321653, 1.48654954531, 0.46365316316])
# 绘制新增点的数据散点图并判断其是0 or 1 or 2
plt.scatter(x_Train[y_Train == 0, 0], x_Train[y_Train == 0, 1], color='b', label="feature 0")
plt.scatter(x_Train[y_Train == 1, 0], x_Train[y_Train == 1, 1], color='r', label="feature 1")
plt.scatter(x_Train[y_Train == 2, 0], x_Train[y_Train == 2, 1], color='yellow', label="feature 2")
plt.scatter(x[0], x[1], color='black', label="symbol ?") # 将新增点绘制成黑色
plt.title("k-NN (one point view)")
plt.xlabel("x axis")
plt.ylabel("y axis")
plt.legend()
plt.show()
#新点knn
distances = []
for X_train in x_Train:
d = sqrt(np.sum((X_train - x) ** 2))
distances.append(d)
nearest = np.argsort(distances)
k = int(input("请输入k值 "))
topK_y = [y_Train[i] for i in nearest[:k]]
print("KNN 计算距离列表"+str(topK_y))
votes = Counter(topK_y)
predict_y = votes.most_common(1)[0][0]
print("新增点预测数值为:"+str(predict_y))
if predict_y==0:
print("新增点预测结果为:setosa")
elif predict_y==1:
print("新增点预测结果为:versicolor")
elif predict_y==2:
print("新增点预测结果为:virginica")
counter = 0
pre = 0
for select in x_Test:
Distance = []
for x_pre in x_Train:
d_t = sqrt(np.sum((x_pre-select) ** 2))
Distance.append(d_t)
near = np.argsort(Distance)
topK_y = [y_Train[i] for i in near[:k]]
votes = Counter(topK_y)
result = votes.most_common(1)[0][0]
if y_Test[pre] == result:
counter = counter + 1
pre = pre + 1
else:
pre = pre + 1
score = counter / test_num
print("测试精度为"+str(score)) #输出测试精度

















 3760
3760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









