







 本文介绍了Python中的四种主要容器:列表、集合、元组和字典,包括它们的创建、访问元素、赋值以及常用方法。详细讲述了列表的append、clear、copy等方法,集合的add、clear、difference等方法,元组的count、index方法,以及字典的clear、copy、fromkeys等方法。同时提到了切片操作和列表推导式,但指出列表推导式不推荐使用。
本文介绍了Python中的四种主要容器:列表、集合、元组和字典,包括它们的创建、访问元素、赋值以及常用方法。详细讲述了列表的append、clear、copy等方法,集合的add、clear、difference等方法,元组的count、index方法,以及字典的clear、copy、fromkeys等方法。同时提到了切片操作和列表推导式,但指出列表推导式不推荐使用。
Python学习之容器目录
一、容器
Python中的容器就是之前提到的复杂数据类型,用来存放大量数据的容器,是Python语言里面的比较重要数据类型,本质是对象,Python底层基于双向链表的实现。而且Python中有许多有关于容器的方法。个人觉得,Python设计者对容器有一种莫名的热爱。真的!方法超级多。
共有四种,分别是列表(list)、集合(set),元组(tuple),字典(dict)
可以输入通过使用dir()方法,展示关于序列所有的方法,还可以通过len()方法,判断一个序列有多少个元素,还可以通过del关键字,删除序列对象或者元素。
代码
list_1 = [True, "shuzi", 4.2, [1, 2], 5]
print(dir(list_1), end = "\n\n")
print("这个列表有%d个元素!"% len(list_1))
del list_1[1]
print(list_1)
del list_1
显示结果

二、序列
序列是基类类型,他的扩展类型分别是:字符串、元组和列表。就可以理解为序列是字符串、元组和列表的祖先一样。
序列在这里只是了解一下,不做过多的讲解!
三、列表(list)
列表是一种线性表,由大量的元素组成,每一个元素都可以存储数据,可以随意更改其中的数据,而且列表里面的元素可以是任意的数据类型,无长度限制。列表的索引值是从0开始的,也就是说排队时第一个人是从0开始读取的。
1、创建
列表的创建有两种方法元素间用逗号,分隔,分别是:方括号 [] 、list() 创建
列表名 = [元素1, 元素2, 元素3, …]
列表名 = list((元素1, 元素2, 元素3, …))
代码
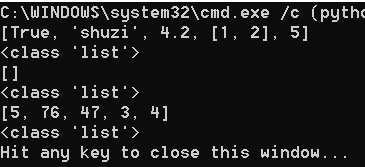
list_1 = [True, "shuzi", 4.2, [1, 2], 5] #利用弱数据类型语言的特点创建一个带元素列表
list_2 = list() #创建一个空列表
list_3 = list((5, 76, 47, 3, 4,)) #创建一个带元素的列表
print(list_1)
print(type(list_1))
print(list_2)
print(type(list_2))
print(list_3)
print(type(list_3))
显示结果
注意:尽量不要用list作为变量名,因为当list变成变量名的时候,list()方法将不能使用
2、访问列表中的元素
想要访问列表中的元素一般通过下标访问,在编程中,99%技术或者语言,下标都是从0开始的(不要问为什么,这就是规定)。
列表名[下标]
代码
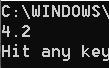
list_1 = [True, "shuzi", 4.2, [1, 2], 5]
print(list_1[2])
显示结果
3、赋值
列表名[下标] = 新值
代码
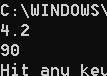
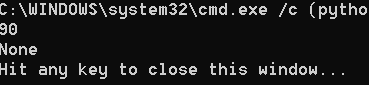
list_1 = [True, "shuzi", 4.2, [1, 2], 5]
print(list_1[2])
list_1[2] = 90
print(list_1[2])
显示结果
注意:下标不要越界,会报错
4、方法
由于列表的方法比较多,就不一一讲解了,主要讲解以下常用的几个方法: ['append', 'clear','copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
a、append方法
append方法是能够在列表末尾添加一个新的元素,所以括号里面必须有一个值。
代码
list_1 = [True, "shuzi", 4.2, [1, 2], 5]
list_1.append(4)
print(list_1)
显示结果

b、clear方法
clear方法是清除列表中的所有元素,这里说的是清除,不是删除列表这个对象。
代码
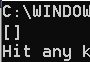
list_1 = [True, "shuzi", 4.2, [1, 2], 5]
list_1.clear()
print(list_1)
显示结果
c、copy方法
copy方法是复制整个列表给另一个列表里,而列表间的赋值不同,赋值是一个列表有两个名字,有点像Linux里面的软链接,copy方法是一个名字一个单独不相干的列表。
代码
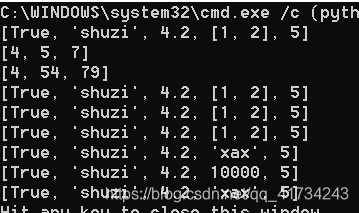
list_1 = [True, "shuzi", 4.2, [1, 2], 5]
list_2 = [4,5,7,]
list_3 = [4,54,79,]
print(list_1)
print(list_2)
print(list_3)
list_2 = list_1.copy()
list_3 = list_1
print(list_1)
print(list_2)
print(list_3)
list_2[3] = 10000
list_3[3] = "xax"
print(list_1)
print(list_2)
print(list_3)
显示结果
d、count方法
count方法是统计元素在列表中的个数。
代码
list_1 = [True, "shuzi", 4.2, [1, 2], 5]
print(list_1.count(5))
显示结果
e、index方法
index方法是查询元素在列表中第一次出现的下标位置,如果列表中不存在该元素,则抛出异常。
代码
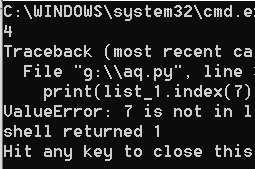
list_1 = [True, "shuzi", 4.2, [1, 2], 5, 50, 5]
print(list_1.index(5))
print(list_1.index(7))
显示结果
f、extend方法
extend方法是将两个列表合并,如果没有列表或者不是列表类型在括号中,则抛出异常。
代码
list_1 = [True, "shuzi", 4.2, [1, 2], 5, 50, 5]
list_1.extend([4,5])
print(list_1)
显示结果

g、insert方法
insert方法是制定要插入的元素的位置,所以括号需要两个值,否则抛出异常。
第一个是将要插入的位置,第二个是插入的元素,如果不在范围内就将在列表末尾插入
代码
list_1 = [True, "shuzi", 4.2, [1, 2], 5, 50, 5]
list_1.insert(4,45)
print(list_1)
list_1.insert(77,9)
print(list_1)
显示结果

h、pop方法
pop方法是通过下标移除元素,默认没有下标时删除最后一个
代码
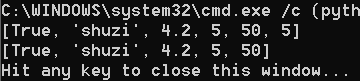
list_1 = [True, "shuzi", 4.2, [1, 2], 5, 50, 5]
list_1.pop(3)
print(list_1)
list_1.pop()
print(list_1)
显示结果
i、remove方法
remove方法是移除对应的元素,如果列表中不存在该元素,则抛出异常。
代码
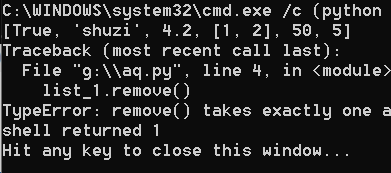
list_1 = [True, "shuzi", 4.2, [1, 2], 5, 50, 5]
list_1.remove(5)
print(list_1)
list_1.remove()
print(list_1)
显示结果
j、reverse方法
reverse方法是翻转元素的顺序,所以括号里是没有参数的。
代码
list_1 = [True, "shuzi", 4.2, [1, 2], 5, 50, 5]
list_1.reverse()
print(list_1)
显示结果

k、sort方法
sort方法是排序,主要针对数字和字符,如果是其他的类型会抛出异常。
代码
list_1 = [ 4.2, 5, 50, 5]
list_1.sort()
print(list_1)
显示结果

四、集合(Set)
集合是一个无序的不重复元素序列,Python中的集合与数学中的集合概念差不多,集合元素之间无序,集合用大括号 {} 表示,但是集合的元素类型是有限定的,不可以有列表,
集合的特点是元素唯一,不允许重复,无序的。
1、创建
列表的创建有两种方法元素间用逗号,分隔,分别是:大括号 { } 、set()创建
注意1:建立空集合类型,不要直接使用{}定义,因为 { } 是用来创建一个空字典。
注意2:尽量不要用set作为变量名,因为当set变成变量名的时候,set()方法将不能使用
集合名 = {元素1, 元素2, 元素3, …}
集合名 = set((元素1, 元素2, 元素3, …))
代码
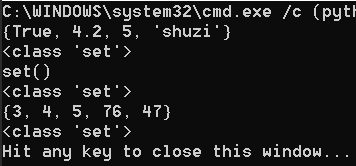
set_1 = {True, "shuzi", 4.2, 5}
set_2 = set() #创建一个空列表,不要用{}建立空集合
set_3 = set((5, 76, 47, 3, 4,)) #创建一个带元素的集合
print(set_1)
print(type(set_1))
print(set_2)
print(type(set_2))
print(set_3)
print(type(set_3))
显示结果
注意:尽量不要用set作为变量名,因为当set变成变量名的时候,set()方法将不能使用
2、访问集合中的元素
set的访问和列表不一样,因为set的位置是不固定的,没有下标的概念。可以通过in查询元素是不是在集合中,如果存在,返回True,否则返回False。
变量名 = ‘想访问的元素’ in 集合名
代码
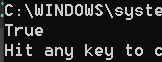
a = {1, 4, 5, 4}
b = 4 in a
print(b)
显示结果
3、赋值
因为set没有下标,所以就没有元素赋值这么一说,但是可以将整个集合赋值给另一个变量。
4、方法
讲解常用的几个方法:
[‘add’,‘clear’, ‘copy’, ‘difference’,‘discard’,‘intersection’,‘pop’,‘remove’, ‘union’]
a、add方法
add方法是能够在集合里面添加一个新的元素,而且位置是随机的,括号里面必须有一个值。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_1.add(4)
print(set_1)
显示结果

b、clear方法
clear方法是清除列表中的所有元素,这里说的是清除,不是删除列表这个对象。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_1.clear()
print(set_1)
显示结果
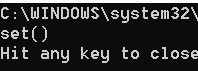
注意:会发现返回的是set(),而不是{}
c、copy方法
copy方法是复制整个集合给另一个集合里。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_2 = {4,5,7,}
print(set_1)
print(set_2)
set_2 = set_1.copy()
print(set_1)
print(set_2)
显示结果
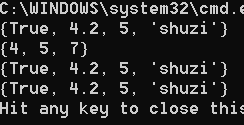
d、difference方法
difference方法是差集,就相对于数学集合里的差集一样,减去相交的元素。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_2 = {4,5,7,}
print(set_1.difference(set_2))
显示结果
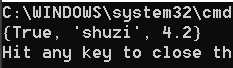
e、discard方法
discard方法是移除元素,如果不存在也不报错。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_1.discard(5)
print(set_1)
set_1.discard(7)
print(set_1)
显示结果
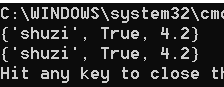
f、intersection方法
intersection方法是交集,就相对于数学集合里的交集一样。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_2 = {4,5,7,}
print(set_1.intersection(set_2))
显示结果
g、union方法
union方法是并集,就相对于数学集合里的并集一样。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_2 = {4,5,7,}
print(set_1.union(set_2))
显示结果

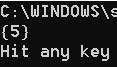
h、pop方法
pop方法是随机移除,一般不用。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_1.pop()
print(set_1)
显示结果
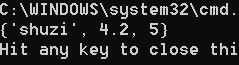
i、remove方法
remove方法是移除对应的元素,如果集合中不存在该元素,则抛出异常。
代码
set_1 = {True, "shuzi", 4.2, 5}
set_1.remove(5)
print(set_1)
set_1.remove(8)
print(set_1)
显示结果
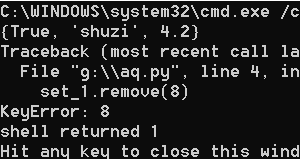
五、元组(tuple)
元组是一种列表类型,一旦创建就不能被修改,可以理解为不可变的列表。即元组由若干逗号分隔的值组成。
1、创建
元组的创建有两种方法元素间用逗号,分隔,分别是:小括号()或 tuple()创建
元组名 = (元素1, 元素2, 元素3, …)
元组名 = tuple((元素1, 元素2, 元素3, …))
代码
tuple_1 = [True, "shuzi", 4.2, [1, 2], 5] #利用弱数据类型语言的特点创建一个带元素元组
tuple_2 = tuple() #创建一个空元组,这样好像没多大用处。
tuple_3 = tuple((5, 76, 47, 3, 4,)) #创建一个带元素的元组
print(tuple_1)
print(type(tuple_1))
print(tuple_2)
print(type(tuple_2))
print(tuple_3)
print(type(tuple_3))
显示结果
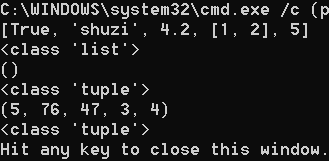
注意:尽量不要用tuple作为变量名,因为当tuple变成变量名的时候,tuple()方法将不能使用
2、访问元组中的元素
元组的访问和列表一样,一般通过下标访问。
元组名[下标]
代码
tuple_1 = (True, "shuzi", 4.2, [1, 2], 5)
print(tuple_1[2])
显示结果
3、赋值
由于元组一旦创建就不能被修改,所以是改变不了里面元素的。
4、方法
由于元组的方法比较多,就不一一讲解了,主要讲解以下常用的几个方法: [‘count’, 'index’]
a、count方法
count方法是统计元素在元组中的个数。
代码
tuple_1 = (True, "shuzi", 4.2, [1, 2], 5)
print(tuple_1.count(5))
显示结果
b、index方法
index方法是查询元素在元组中第一次出现的下标位置,如果元组中不存在该元素,则抛出异常。
代码
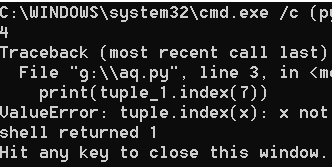
tuple_1 = (True, "shuzi", 4.2, [1, 2], 5, 5, 50, 5)
print(tuple_1.index(5))
print(tuple_1.index(7))
显示结果
六、字典(dict)
字典是用来存取多个值,按照key : value的格式存值,取的时候可以通过key而不是value去取值,key对value具有描述性的作用。存放数据的种类各种各样并且数据较多,存在对应关系的时候可以使用字典。
在{}内用逗号分隔开多个元素,每一个元素都是key: value的格式,其中value是任意格式的数据类型,key由于具有描述性的作用,所以key通常是字符串类型。
键必须是唯一的,值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
1、创建
字典的创建有两种方法元素间用逗号,分隔,分别是:中括号{}或 dict()创建
字典名 = {key1: 数据1, key2: 数据2, key3: 数据3,…}
字典名 = tuple({key1: 数据1, key2: 数据2, key3: 数据3,…})
代码
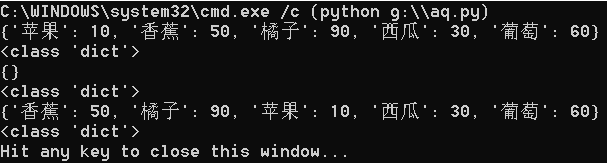
dict_1 = {"苹果": 10, "香蕉": 50, "橘子": 90, "西瓜": 30, "葡萄": 60} #利用弱数据类型语言的特点创建一个带元素字典
dict_2 = dict() #创建一个空字典
dict_3 = dict({"香蕉": 50, "橘子": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60}) #创建一个带元素的字典
print(dict_1)
print(type(dict_1))
print(dict_2)
print(type(dict_2))
print(dict_3)
print(type(dict_3))
显示结果
注意1:尽量不要用dict作为变量名,因为当dict变成变量名的时候,dict()方法将不能使用
注意2:Python中的字典类型,key必须是字符串!!!
2、访问字典中的元素
字典访问元素是通过key的对应关系访问的。
字典名[key]
代码
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
print(dict_1["香蕉"])
显示结果
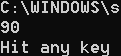
注意:如果key值相同,那么访问最后一个key值的数据
3、赋值
字典赋值是通过key来赋值的,如果key不存在,则新增这个键值对,如果赋值重复,则将相同key重合并赋值。
字典名[key] = 新值
代码
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
dict_1["香蕉"] = 100
print(dict_1)
显示结果

4、方法
由于字典的方法比较多,就不一一讲解了,主要讲解以下常用的几个方法: [‘clear’, 'copy’, ‘fromkeys’, ‘get’, ‘items’, ‘keys’, ‘pop’, ‘popitem’, ‘values’]
a、clear方法
clear方法是清除列表中的所有元素,这里说的是清除,不是删除列表这个对象。
代码
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
print(dict_1.clear())
显示结果

b、copy方法
copy方法是复制整个集合字典给另一个字典里。而字典间的赋值不同,赋值是一个字典有两个名字,有点像Linux里面的软链接,copy方法是一个名字一个单独不相干的字典。
代码
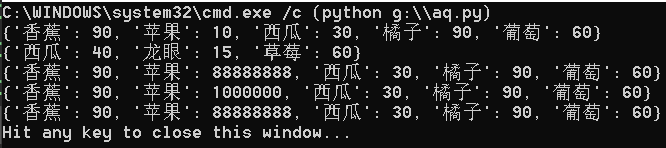
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
dict_2 = dict({"西瓜": 40, "龙眼": 100, "龙眼": 15, "草莓": 60})
dict_3 = dict({"西瓜": 40, "龙眼": 100, "龙眼": 15, "草莓": 60})
print(dict_1)
print(dict_2)
dict_2 = dict_1.copy()
dict_3 = dict_1
dict_2["苹果"] = 1000000
dict_3["苹果"] = 88888888
print(dict_1)
print(dict_2)
print(dict_3)
显示结果
c、fromkeys方法
fromkeys方法是创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值。
代码
dict_1 = dict.fromkeys(["香蕉", "苹果", "西瓜"], None)
print(dict_1)
显示结果

d、get方法
get方法是通过key返回该key对应的值,如果没有这个key,则返回None。
代码
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
print(dict_1.get("香蕉"))
print(dict_1.get(90))
显示结果
e、items方法
items方法是以列表返回可遍历的(键, 值) 元组数组。
代码
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
print(dict_1.items())
显示结果

f、keys方法
keys方法是以列表返回可遍历的键的数组。
代码
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
print(dict_1.keys())
显示结果

g、pop方法
pop方法是删除字典给定键 key 所对应的值,返回值为被删除的值,key值必须给出,否则抛出异常。
代码
dict_1 = dict({"香蕉": 50, "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
dict_1.pop("香蕉")
print(dict_1)
显示结果

h、popitem方法
popitem方法是随机返回并删除字典中的一对键和值。
代码
dict_1 = dict({ "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
dict_1.popitem()
print(dict_1)
显示结果

i、values方法
values方法是移除对应的元素,如果集合中不存在该元素,则抛出异常。
代码
dict_1 = dict({ "香蕉": 90, "苹果": 10, "西瓜": 30, "橘子": 90, "葡萄": 60})
dict_1.values()
print(dict_1)
显示结果

七、切片操作
切片操作是容器中一个非常重要的特征,我们会在下一篇博文讲解:链接在此
八、列表推导式(不推荐使用)
Python里面有个很棒的语法糖(syntactic sugar),它就是 list comprehension ,有人把它翻译成“列表推导式”,也有人翻译成“列表解析式”。名字听上去很难理解,但是看它的语法就很清晰了。虽然名字叫做 list comprehension,但是这个语法同样适用于dict、set等这一系列可迭代(iterable)数据结构。
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是 0 个或多个 for 或者 if 语句。你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以 if 和 for 语句为上下文的表达式运行完成之后产生。
列表推导式的执行顺序:各语句之间是嵌套关系,左边第二个语句是最外层,依次往右进一层,左边第一条语句是最后一层。
z = [x*y for x in range(1,5) if x > 2 for y in range(1,4) if y < 3]
他的执行顺序是:
z = []
for x in range(1,5):
if x > 2:
for y in range(1,4):
if y < 3:
z.append(x*y)
但是不推荐使用这个表达式,在编写时容易逻辑混乱,在阅读时不容易理解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









