







 本文详细介绍了正则表达式在.NET环境中的使用,特别是C#中的应用。正则表达式是一种强大的文本处理工具,可用于字符串定位、格式转换等多种任务。.NET Framework提供了System.Text.RegularExpressions命名空间支持正则表达式。文章讲解了正则表达式的概念、模式构建、元字符、转义序列,以及如何使用.NET类进行匹配和搜索操作。文中还通过实例展示了如何提取URI的各个元素,强调了正则表达式在处理字符串时的高效性,并提到了Span<T>在处理大字符串时的内存优势。
本文详细介绍了正则表达式在.NET环境中的使用,特别是C#中的应用。正则表达式是一种强大的文本处理工具,可用于字符串定位、格式转换等多种任务。.NET Framework提供了System.Text.RegularExpressions命名空间支持正则表达式。文章讲解了正则表达式的概念、模式构建、元字符、转义序列,以及如何使用.NET类进行匹配和搜索操作。文中还通过实例展示了如何提取URI的各个元素,强调了正则表达式在处理字符串时的高效性,并提到了Span<T>在处理大字符串时的内存优势。
正则表达式作为小型技术领域的一部分,在各种程序中都有着难以置信的作用。正则表达式可以看成一种有特定功能的小型编程语言:在大的字符串表达式中定位子字符串。它不是一种新技术,最初是在UNIX环境中开发的,与Perl和JavaScript编程语言一起使用的比较多。System.Text.RegularExpressions名称空间中的许多.Net类都支持正则表达式。.Net Framework的各个部分也使用正则表达式。例如,在ASP.NET验证服务器的控件中就使用了正则表达式。
对不太熟悉正则表达式语言的开发者来说,下面将主要解释正则表达式和相关的.Net类。
注:.Net正则表达式引擎用于兼容Perl 5的正则表达式,但它有一些新功能。
概述
正则表达式语言是一种专门用于字符串处理的语言。它包含两个功能:
- 一组用于标识特殊字符类型的转义代码。你可能熟悉DOS命令中的使用*字符表示任意子字符串(例如,DOS命令 Dir Re*会列出名称以Re开头的所有文件)。正则表达式使用与*类似的许多序列来表示“任意一个字符”、“一个单词的中断”和“一个可选的字符”等。
- 一个系统,在搜索操作中把子字符串和中间结果的各个部分组合起来。
使用正则表达式,可以对字符串执行许多复杂而高级的操作,例如:
- 识别(可以是标记或删除)字符串中的所有重复单词,例如,把“The computer books books”转换为“The computer books”。
- 把所有单词都转换为标题格式,例如,把“this is a Title”转换为“This Is A Titlte”。
- 把长于3个字符的所有单词都转换为标题格式,例如,把"this is a Title"转换为"This is a Title"。
- 确保句子有正确的大写形式。
- 区分URI的各个元素(例如,给定http://www.wrox.com,提取出其中的协议、计算机名和文件名等)。
当然,这些都是可以在C#中用System.String和System.Text.StringBuilder的各种方法执行的任务。但是,在一些情况下,还需要编写相当多的C#代码。如果使用正则表达式,这些代码一般可以压缩为几行。实际上,这是实例化了一个对象System.Text.RegularExpressions.Regex(甚至更简单,调用Regex的静态方法),给它传递要处理的字符串和一个正则表达式(这是一个字符串,它包含用正则表达式语言编写的指令)。
正则表达式字符串初看起来像一般的字符串,但其中包含了转移序列和有特定含义的其他字符。例如,序列\b表示一个字的开头和结尾(字的边界),因此如果要表示正在查找以字符th开头的字,就可以编写正则表达式\bth(即字边界是序列-t-h)。如果要搜索所有以th结尾的单词,就可以编写th\b(字边界是序列t-h-)。但是,正则表达式要比这复杂的多,包括可以在搜索操作中找到存储部分文本的工具性程序。这里仅简要介绍正则表达式的功能。
假定应用程序需要把美国的电话号码转换为国际格式。在美国,电话号码的格式为314-123-1234,常常写作(314)123-1234。在把这个国家格式转换为国际格式时,必须在电话号码的前面加上+1(美国的国家代码),并给区号加上圆括号:+1(314) 123-1234。在查找和替换时,这并不复杂。但如果要使用String类完成这个转换,就需要编写一些代码。而正则表达式语言可以构造一个短的字符串来表达上述含义。
这里实例是一个非常简单的示例,只考虑如何查找字符串中的某些子字符串,不需要考虑如何修改他们。
public static void Find1(text)
{
const string pattern = "ion";
MatchCollection matches = Regex.Matches(text,pattern,RegexOptions.IgnoreCase|RegexOptions.ExplicitCapture);
WriteMatches(text,matches);//此为后面编写的一个输出匹配结果的方法
}
为了说明.Net类的正则表达式,我们先进行一次纯文本的基本搜索,这次搜索不带任何转义序列或正则表达式命令。假定要查找所有的字符串ion,把这个搜索字符串称为模式。
在这段代码中,使用了System.Text.RegularExpressions名称空间中的Regex类的静态方法Matches()。这个方法的参数是一些输入文本、一个模式和从RegexOptions枚举中提出的一组可选标志。在本例中,指定所有的搜索都不应区分大小写。另一个标记ExplicitCapture改变了收集匹配的方式,对于本例,这样可以使搜索的效率更高。Matches()方法返回MatchCollection对象的引用。匹配是一个技术术语,表示在表达式中查找模式实例的结果,用System.Text.RegularExpressions.Match类表示它。因此,我们返回一个包含所有匹配的MatchCollection,每个匹配都用一个Match对象来表示。在上面的代码中,只是迭代集合,并使用Match类的Index属性,Match类返回输入文本中匹配所在的索引。
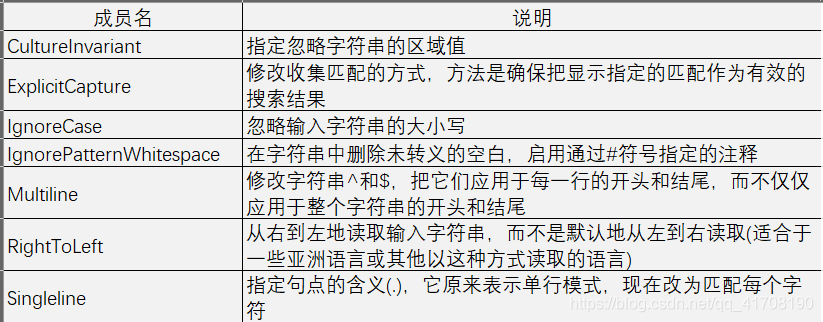
下面是RegexOptions枚举的一些成员
到目前为止,在前面的示例中,除了一些新的.NET基类外,其他都不是新的内容。但正则表达式的能力主要取决于模式字符串,原因是模式字符串不必仅包含纯文本。如前所述,它还可以包含元字符和转义序列,其中元字符是给出命令的特定字符,而转义序列的工作方式与C#的转移序列相同。它们都是以反斜杠(\)开头的字符且具有特殊的含义。
例如,假定要查找以n开头的字,那么可以使用转移序列\b,它表示一个字的边界(字的边界是以字母数字表中的某个字符开头,或者后面是一个空白字符或标点符号)。可以编写如下代码:
string str = "fwef fw fwtew w nfsfe weffn fdsf";
const string pattern = @"\bn";
MatchCollection myMatches = Regex.Matches(str,pattern,RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture);
注意字符串前面的符号@。要在运行时把\b传递给.NET正则表达式引擎,反斜杠(\)不应被C#编译器解释为转移序列。
如果要查找以序列ure结尾的字,就可以使用下面的代码:
const string pettern = @"ure\b";
如果要查找以字母a开头、以序列ure结尾的所有字(例如,字符串architecture),就必须在上面的代码中添加一些内容。显示,我们需要一个以\ba开头、以ure\b结尾的模式,但中间的内容怎么办?需要告诉应用程序,在a和ure中间的内容可以是任意长度的字符,只要这些字符不是空白即可。实际上,正确的模式如下所示:
const string pattern = @"\ba\S*ure\b";
使用正则表达式要习惯的一点是,对像这样怪异的字符序列应见怪不怪。但这个序列的工作是非常逻辑化的。转移序列\S表示任何不是空白字符的字符。*称为限定符,其含义是前面的字符可以重复任意次,包括0次。序列\S*表示任意数量不是空白字符的字符。因此,上面的模式匹配以a开头以ure结尾的任何单个单词。
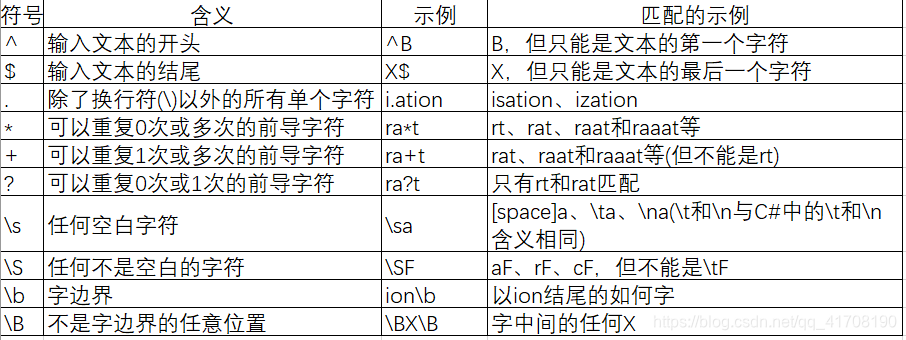
下表是可以使用的一些主要的特定字符或转义序列,但这个表并不完整,完整的列表请参考MSDN文档。
如果要搜索其中的一个元字符,就可以通过带有反斜杠的相应转义字符来表示。例如,“.”(一个句点)表示除了换行字符以外的所有单个字符,而"\."表示一个点。
可以把替换的字符放在方括号中,请求匹配包含这些字符。例如,[1|c]表示字符可以是1或c。如果要搜索map或man,就可以使用序列map[n|p]。在方括号中,也可以指定一个范围,例如,[a-z]表示所有的小写字母,[A-E]表示A~E之间所有的大写字母(包括字母A和E),[0-9]表示一个数字,其简写方式是\d。如果要搜索一个整数(该序列只包含0-9的字符),就可以编写[0-9]+或[\d]+。
^用在方括号中时有不同的含义。在方括号外部使用它,就标记输入文本的开头。在方括号内使用它,表示除了^之后的字符之外的任意字符。
显示结果
借用一个示例,看看正则表达式的工作方式。
该示例的核心是方法WriteMatches(),它把MatchCollection中的所有匹配以比较详细的格式显示出来。对于每个匹配结果,该方法都会显示匹配在输入字符串中的索引、匹配的字符串和一个略长的字符串,其中包含匹配结果和输入文本中至多10个外围字符,其中至多有5个字符放在匹配结果的前面,至多5个字符放在匹配结果的后面(如果匹配结果的位置在输入文本的开头或结尾5个字符内,则结果中匹配字符串前后的字符就会少于5个)。
完整代码:
using System;
using System.Text.RegularExpressions;
namespace 正则表达式
{
class Program
{
static void Main(string[] args)
{
string text = "fwflweflw flw wef wflfl jwelfjwf 3233f lweflw arwwrwerure fwef a ure aure af a ad assffwefwfwfure";
Find(text);
}
public static void Find(string text){
string pattern = @"\ba\S*ure\b";
MatchCollection matches= Regex.Matches(text,pattern,RegexOptions.IgnoreCase);
WriteMatches(text,matches);
}
public static void WriteMatches(string text,MatchCollection matches){
System.Console.WriteLine($"Original text was: \n{text}");
System.Console.WriteLine($"No. of matches: {matches.Count}");
foreach(Match nextMatch in matches){
int index = nextMatch.Index;
string result = nextMatch.ToString();
int charsBefore = (index < 5)?index:5;
int fromEnd = text.Length - index - result.Length;
int charsAfter = (fromEnd < 5)?fromEnd:5;
int charsToDisplay = charsBefore + charsAfter + result.Length;
System.Console.WriteLine($"Index: {index}, \tString: {result}, \t{text.Substring(index - charsBefore,charsToDisplay)}");
}
}
}
}
匹配、组和捕获
正则表达式的一个优秀特性是可以把字符组合起来,其工作方式与C#中的复合语句一样。在C#中,可以把任意数量的语句放在花括号中,把它们组合在一起,其结果视为复合语句。在正则表达式模式中,也可以把任何字符组合起来(包括元字符和转义序列),像处理单个字符那样处理它们。唯一的区别是要使用圆括号而不是花括号,得到的序列称为一组。
例如,模式(an)+定位任意重复出现的序列an。限定符"+"只应用于它前面的一个字符,但因为我们把字符组合起来了,所以它现在把重复的an作为一个单元来对待。这意味了,如果(an)+应用到输入文本"bananas came to Europe late in the annals of history"上,就会从bananas中识别出anan。另一方便,如果使用an+,则程序将从annals中选择ann,从bananas中选择出两个分开的an序列。表达式(an)+可以识别出an、anan、ananan等,而表达式an+可以识别出an、ann、annn等。
注:
在上面的示例中,为什么(an)+从banana中选择的示anan,而没有把其中一个an作为一个匹配结果?因为匹配结果是不能重叠的。如果有可能重叠,在默认情况下就选择最长的匹配序列。
但是,组的功能要比这强大的多。在默认情况下,把模式的一部分组合为一个组时,就要求正则表达式引擎按照该组来匹配,或按照整个模式来匹配。换言之,可以把组当成一个要匹配和返回的模式。如果要把字符串分解为各个部分,这种模式就非常有效。
例如,URI的格式是<protocol>://<address>:<port>,其中端口是可选的。它的一个示例是http://www.wrox.com:80。假定要从一个URI中提取协议、地址和端口,而且不考虑URI的后面是否紧跟这空白(但没有标点符号),那么可以使用下面的表达式:
\b(https?)(://)([.\w]+)([\s:]([\d]{2,5})?)\b
该表达式的工作方式如下:首先,前导\b序列和结尾\b序列确保只需要考虑完全是字的文本部分。在这个文本部分中,第一组(https?)会识别http或https协议。S字符后面的?指定这个字符可能出现0次或1次,因此找到http和https。括号表示把协议存储为一组。
第二组是一个简单的(://)。它仅指定字符://。
第三组([.\w]+)比较有趣。这个组包含一个放在括号里的表达式,该表达式要么是句点字符(.),要么是用\w指定的任意字母数字字符。这些字符可以重叠任意多次,因此匹配www.wrox.com。
第四组([\s:]([\d]{2,5})?)是一个较长的表达式,包含一个内部组。在该组中,第一个放在括号中的表达式允许通过\s指定空白字符或冒号。内部组用[\d]指定一个数字。表达式{2,5}指定前面的字符(数字)允许至少出现两次但不超过5次。数字的完整表达式用内部组后面的?指定允许出现0次或1次。使这个组变成可选非常重要,因为端口号并不总是在URI中指定;事实上,通常不指定它。
下面是示例代码:
using System;
using System.Text.RegularExpressions;
namespace 正则表达式_组_
{
class Program
{
static void Main(string[] args)
{
string line = "Hey, I've just found this amazing URI at"+
"http:// what was it -oh yes https://www.wrox.com or "+
"http://www.wrox.com:803";
string pattern = @"\b(https?)(://)([.\w]+)([\s:]([\d]{2,4})?)\b";
var regex = new Regex(pattern);
MatchCollection matches = regex.Matches(line);
foreach(Match match in matches){
System.Console.WriteLine($"Match : {match}");
foreach(Group group in match.Groups){
if(group.Success){
System.Console.WriteLine($"group index: {group.Index},value: {group.Value}");
}
}
//System.Console.WriteLine(match.ToString());
}
//Console.WriteLine("Hello World!");
}
}
}
输出如下:
Match : https://www.wrox.com
group index: 68,value: https://www.wrox.com
group index: 68,value: https
group index: 73,value: ://
group index: 76,value: www.wrox.com
group index: 88,value:
Match : http://www.wrox.com:803
group index: 92,value: http://www.wrox.com:803
group index: 92,value: http
group index: 96,value: ://
group index: 99,value: www.wrox.com
group index: 111,value: :803
group index: 112,value: 803
上面示例的匹配代码使用类似于之前的Matches方法。区别是在Match.Groups属性内迭代所有的Group对象,在控制台上输出每组得到的索引和值。
之后,就匹配文本中的URI,URI的不同部分得到了很好的分组。组还提供了更多的功能。一些组,如协议和地址之间的分隔,可以忽略,并且组也可以命名。
修改正则表达式,命名每个组,忽略一些名称。在组的开头指定?<name>,就可给组命名。例如下面示例,协议、地址和端口的正则表达式就采用相应的名称。在组的开头使用?:来忽略该组。不要迷惑于组内的?:://,它表示搜索://,组本身因为前面的?:而被忽略:
using System;
using System.Text.RegularExpressions;
namespace 正则表达式_组_
{
class Program
{
static void Main(string[] args)
{
string line = "Hey, I've just found this amazing URI at"+
"http:// what was it -oh yes https://www.wrox.com or "+
"http://www.wrox.com:803";
//string pattern = @"\b(https?)(://)([.\w]+)([\s:]([\d]{2,4})?)\b";
string pattern = @"\b(?<protocol>https?)(?:://)(?<adress>[.\w]+)([\s:](?<port>[\d]{2,4})?)\b";
var regex = new Regex(pattern,RegexOptions.ExplicitCapture);
MatchCollection matches = regex.Matches(line);
foreach(Match match in matches){
System.Console.WriteLine($"Match : {match} at {match.Index}");
foreach(var groupName in regex.GetGroupNames()){
System.Console.WriteLine($"match for {groupName}: {match.Groups[groupName].Value}");
}
}
}
}
}
输出如下:
Match : https://www.wrox.com at 68
match for 0: https://www.wrox.com
match for protocol: https
match for adress: www.wrox.com
match for port:
Match : http://www.wrox.com:803 at 92
match for 0: http://www.wrox.com:803
match for protocol: http
match for adress: www.wrox.com
match for port: 803
上面代码中,为了从正则表达式中获得组,Regex类定义了GetGroupNames方法。每个匹配都使用了所有的组名,使用Groups属性和索引输出组名和值。
字符串和Span
今天的编程代码通常处理需要操作的长字符串。例如,Web API以JSON或XML格式返回一个长字符串,将如此大的字符串分割成许多更小的字符串,意味着创建了许多对象,而垃圾收集器不再需要这些字符串时,需要做很多事情来释放这些字符串所占的内存。
.NET Core有个新的方法:Span<T>类型。该类型引用数组的一个切片,而不需要复制它的内容。同样,Span<T>可以用来引用一个字符串的片段,而不需要复制原始内容。
下面的代码片段从一个由变量文本引用的非常长的字符串中创建了span。它与以前使用正则表达式的字符串相同。ReadOnlySpan<char>从AsSpan扩展方法中返回。AsSpan扩展了字符串类型,并返回以一个ReadOnlySpan<char>,因为字符串由char元素组成。在内部,Span<T>使用了ref关键字来保存引用。在Slice方法中,可以从完整的字符串中获取一个切片。用第一个参数选择开头,在该索引中,在字符串中找到的第一个文本Visual的索引。从那里,第二个参数使用13个字符定义。结果还是一个ReadOnlySpan。只有使用span的ToArray方法才能分配内存。ToArray方法分配切片所需的内存。然后将char数组传递给string类型的构造函数,以创建一个新的字符串,从切片中分配的字符串包含Visual Studio。
using System;
namespace 字符串和Span
{
class Program
{
static void Main(string[] args)
{
string text = "Welcome to use Visual Studio 2019";//假定text是一个非常长的文本
int index = text.IndexOf("Visual");
ReadOnlySpan<char> spanToText = text.AsSpan();
ReadOnlySpan<char> slice = spanToText.Slice(index,13);
string newString = new string(slice.ToArray());
Console.WriteLine(newString);
}
}
}

















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









