







*root == NULL 跟 root == NULL的区别
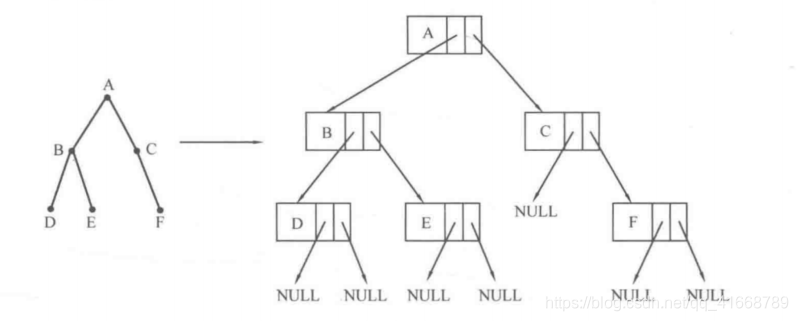
左边概念意义的二叉树在使用二叉链表存储之后形成了箭头右边的图。 对每个结点,第一部分是数据域,数据域后面紧跟两个指针域,用以存放左子树根结点的地址和右子树根结点的地址。如果某棵子树是空树,那么显然也就不存在根结点,其地址就会是NULL,表示不存在这个结点。因此图中C的左子树、DEF的左子树和右子树都为空树,故C的左指针域、DEF的左指针域和右指针域都为NULL。
在递归时,总是往左子树根结点和右子树根结点递归。此时如果子树是空树,那么root一定是NULL,表示这个结点不存在。而所谓的*root == NULL 的错误就很显然了,因为*root的含义是获取地址root指向的空间的内容,但这无法说明地址root是否为空,也即无法确定是否存在这个结点,因此*root == NULL 的写法是错误的。
通过上面的讲解,需要明白 root == NULL 与 *root == NULL 的区别,也即结点地址为NULL 与 结点内容为NULL的区别(也相当于结点不存在与结点存在但是没有内容的区别),这在写程序时是非常重要的,因为在二叉链表中一般都是判定结点是否存在,所以一般都是 root == NULL 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









