







GDB调试之精髓
1 gdb基本调试命令
这里再补充一个g++/gcc命令的知识,如:
g++ -o log_test_debug log_test.cc -g
-o是指定生成的输出文件名,默认情况下,g++ 会生成一个名为 a.out 的可执行文件。如果你想自定义输出文件的名称,可以使用-o选项-
log_test_debug 是你希望生成的可执行文件的名称 -
log_test.cc 是你要编译的源代码文件 -g选项告诉编译器生成调试信息,通常用于调试程序
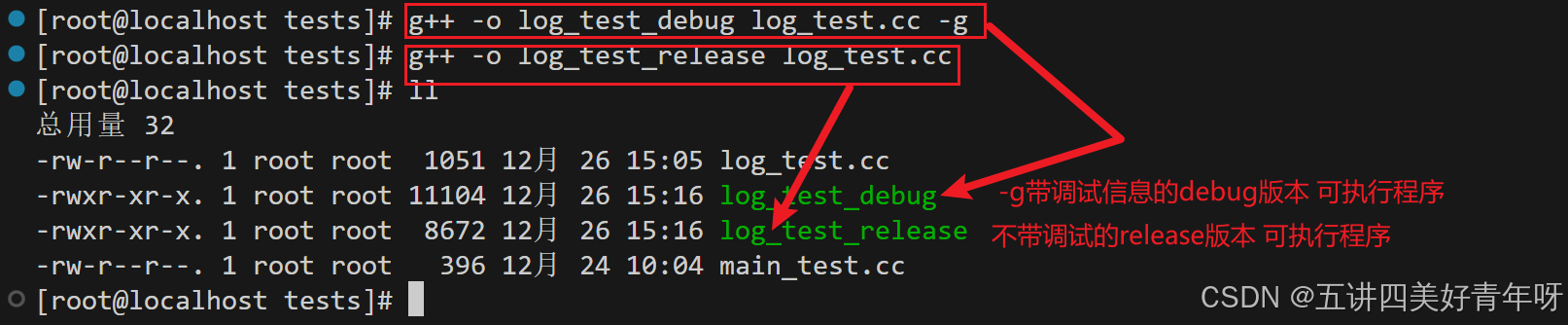
运行可执行程序命令,如
./log_test_debug
以下是本博文的正式内容
具体关于gdb基本命令和使用,详见另一篇博客
这里补充一个代码
#include <stdio.h>
#include <string.h>
int main(int argc, char* argv[]){
if(argc != 3){
printf("\n这是一个文件复制程序,类似Linux系统的cp命令。\n");
printf("用法: ./test srcfilename dstfilename\n");
return -1;
}
FILE *srcfp, *dstfp;
srcfp = dstfp = 0;
//以只读的方式打开源文件,模式是rb
if((srcfp = fopen(argv[1], "rb")) == 0){
printf("fopen(%s) failed.\n", argv[1]);
return -1;
}
//以只写的方式打开目标文件,模式是wb
if((dstfp = fopen(argv[2], "wb")) == 0){
printf("fopen(%s) failed.\n", argv[2]);
fclose(srcfp);
return -1;
}
int nread = 0; //每次读取到的内容的字节数
char strbuf[500]; //存放每次从文件读取到的内容的缓冲区,注意,这不是个字符串
while(1){
//从源文件中读取数据,并写入目标文件
memset(strbuf, 0, sizeof(strbuf));
if((nread = fread(strbuf, 1, 500, srcfp)) == 0) break;
fwrite(strbuf, 1, nread, dstfp);
}
fclose(srcfp);
fclose(dstfp);
printf("文件复制成功。\n");
return 0;
}
这个代码的作用就是将一个文件里的内容,复制到另一个文件中,如:
./log_test_debug a.txt b.txt
- 就是把
a.txt的内容复制到b.txt中
补充命令:
| 命令 | 作用 |
|---|---|
| set args | 设置主程序的参数 例如,设置参数方式为:(gdb)set args a.txt b.txt |
| q | 退出gdb环境 |
| p | 打印变量,但可以接表达式,如:(gdb) p printf(“hello world”) |
这里用上面的程序演示下set args:

注1:set args命令,对于设置程序参数命令,如果程序里有特殊字符,那么参数该怎么处理?
- 比如有个特殊的问题,“aaa bbb.cc”,那么在gdb中:
(gdb) set args aaa bbb.cc /tmp/rrr.cc
那么,这个时候,main就有4个参数,而不是3个了
argv[0]: test
argv[1]: aaa
argv[2]: bbb
argv[3]: /tmp/rrr.cc - 所以,碰到这种情况怎么解决?
特殊字符,就用双引号包括起来:
(gdb)set args "aaa bbb.cc" /tmp/rrr.cc
这个时候argc就是3了,就是我们想要的参数数量。 - 如果你是
资深程序员的话,碰到这种特殊的参数情况,特别的多!!!
注2:对于s命令,如果s想进入printf()函数中,如果编译的这个程序有printf()函数的源代码,那么s就可以进去;如果没有源代码,只是库的话,是进不去的。
- 即,如果函数是库函数或者第三方提供的函数,用s是进不去的,因为没有源代码,如果是自定义的函数,只要有源代码就可以进去。
2 调试core文件
程序挂掉时,系统缺省不会生成core文件
1)ulimit -a:查看系统参数
2)ulimit -c unlimited:把core文件的大小设为无限制
3)运行程序,生成core文件
4)gbd 程序名 core文件名
这里演示一个会挂掉的程序:
#include <stdio.h>
#include <string.h>
int bb(int bbb)
{
int* p = 0;
*p = bbb;
}
int aa(int nuaaam)
{
bb(aaa);
}
int main()
{
aa(13);
int i = 1;
printf("=&d=\n", (++i)+(++i));
}
上面这段代码就会出现coredump(一种常见的段错误),如果没有出现coredump文件,说明是系统参数的限制,用ulimit -a查看系统参数全部的限制情况
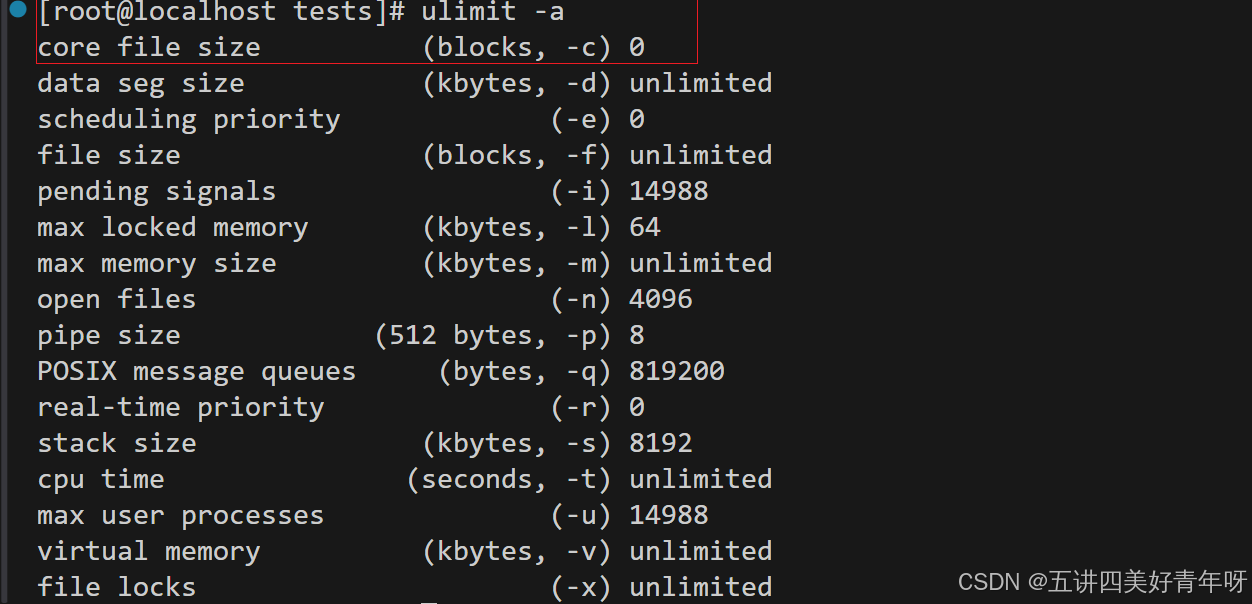
如上图中,core file size (blocks, -c) 0,说明core文件的大小是0,也就是说不生成core文件,就需要把他改下:
ulimit -c unlimited:就是把core文件大小改为无限制
这个时候运行上面的程序,就会出现一个core文件,如core.27761
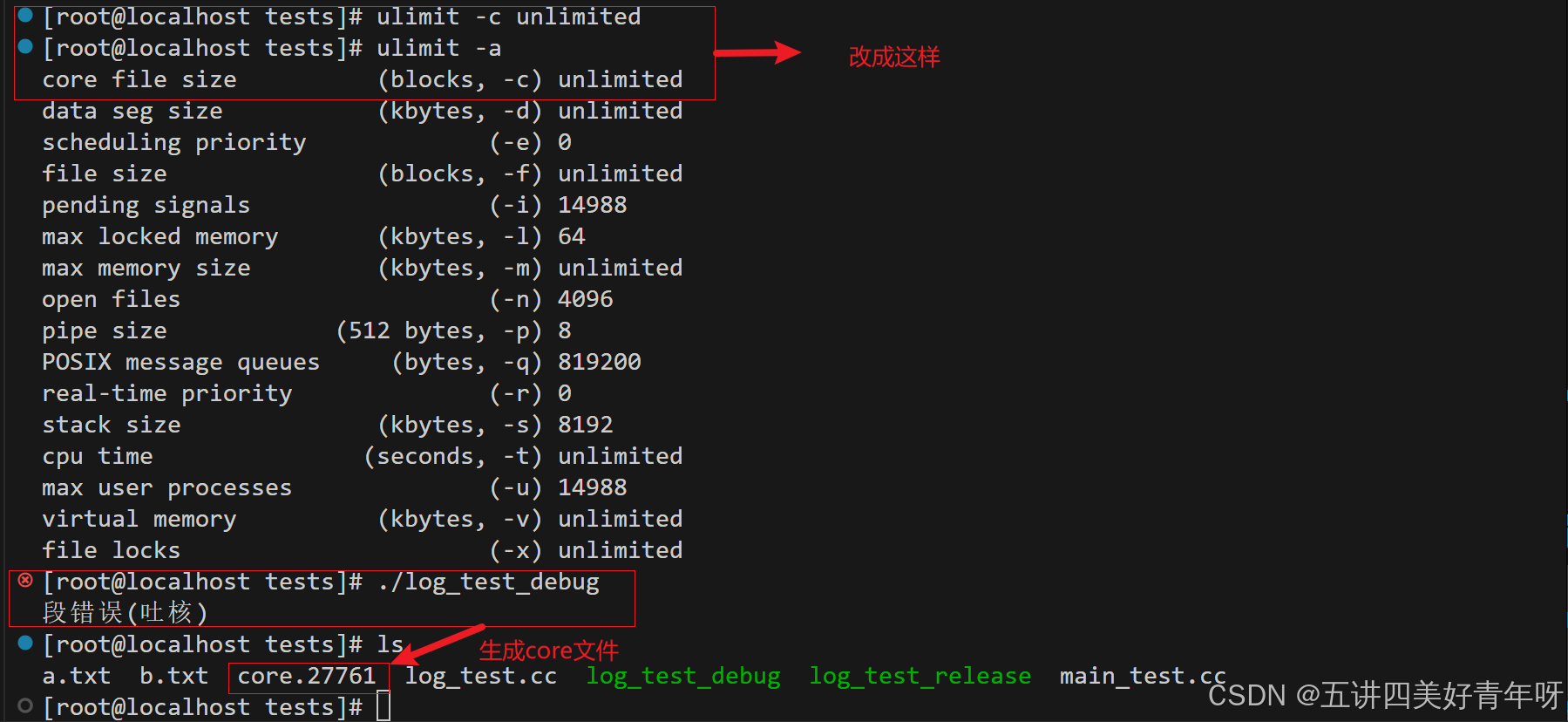
接下来就是用gdb调试core文件:
- gdb 程序名 core文件名
如:gdb test core.27761
就是保哪里出现了问题,如:7 *p = num;表示程序的第7行这里的代码出了问题
此时可以用bt来查看函数的调用栈

也可以用valgrind来查看错误原因
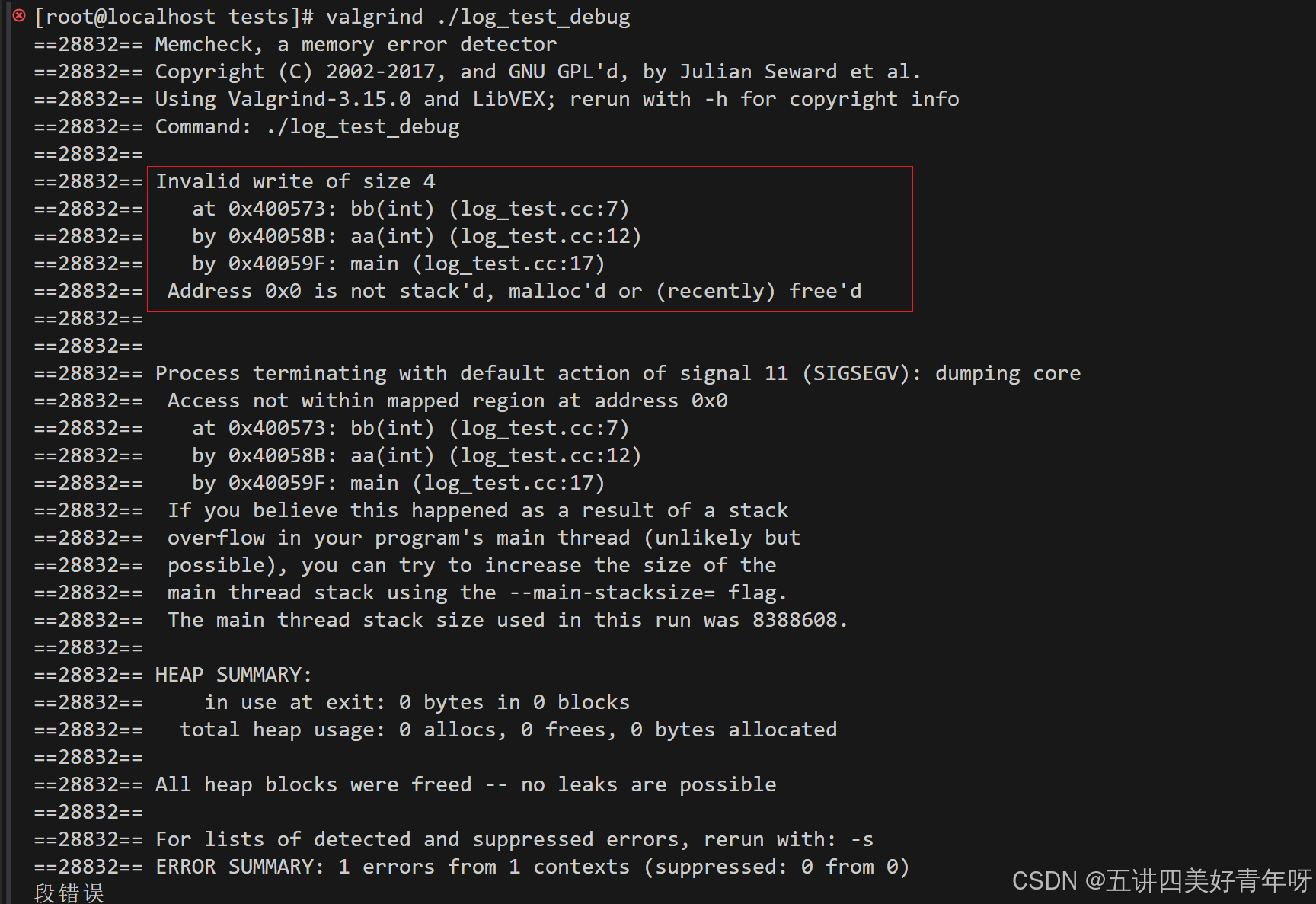
上图说明:
- 错误信息:
-
Invalid write of size 4:这是一个 4 字节大小的非法写入操作。 Address 0x0 is not stack'd, malloc'd or (recently) free'd:你正在访问 0x0 这个地址,它通常表示一个空指针,未分配内存或已经释放的内存 - 崩溃位置:
-
错误发生在 bb(int) 函数的第 7 行: 0x400573: bb(int) (log_test.cc:7) bb(int) 被 aa(int) 调用,在第 12 行: 0x40058B: aa(int) (log_test.cc:12) aa(int) 被 main 函数调用,在第 17 行: 0x40059F: main (log_test.cc:17)
总结:关于调试core文件,很简单,就是做下参数设置,让出现coredump时,可以生成core文件,然后gdb调试core文件,就可以知道在哪一行挂掉了,最后bt查看函数的调用栈。
3 调试正在运行中的程序
以下面的程序为例:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
void func1(int num){
int i = 0;
for (; i < 10000; ++i){
sleep(1);
printf("i = %d\n", i);
}
}
void func2(int num){
func1(num);
}
int main(){
func2(1);
return 0;
}
编译:
g++ -o log_test_debug log_test.cc -g
运行:
./log_test_debug
这个程序会每隔 1s 打印一次
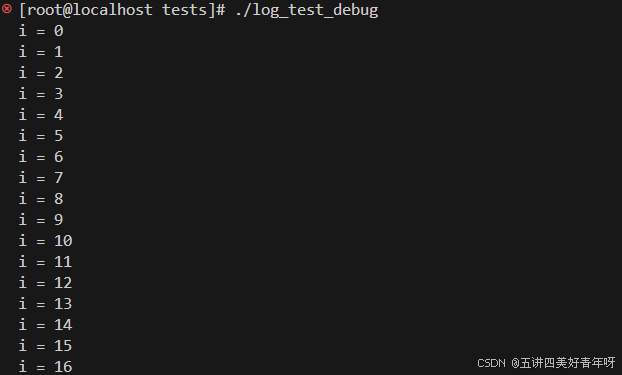
查看下进程的编号,为30002

然后使用gdb调试
ps -ef | grep log_test_debug
这个时候,上面的那个程序就停下来,不在跑了
如果在gdb中退出去
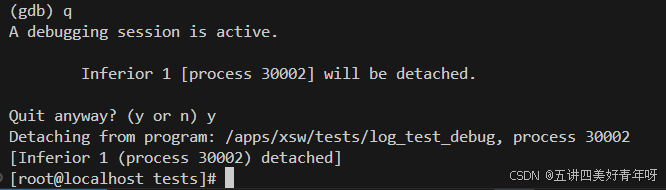
那么此时,上面的那个程序就会接着跑
然后再gdb进去,这个时候使用bt查看下函数的调用栈
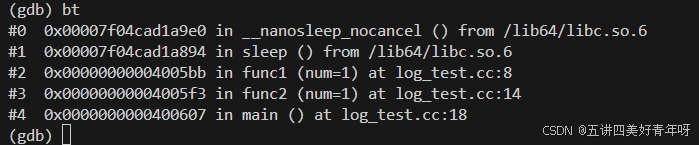
可以看到,栈底的是main,然后main调用func2,func2调用func1,func1调用sleep,然后在sleep里面又调用了__nanosleep_nocancel,当时进入gdb后,程序是停止的,不在跑的,所以此时程序停留在__nanosleep_nocancel里
然后用next,再用bt看下
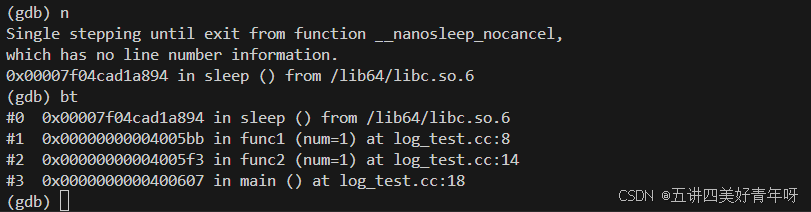
这个时候可以看到,程序停留在了sleep函数里面
然后再next,再用bt看下
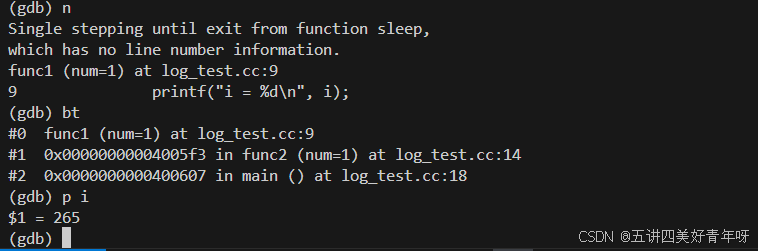
此时,程序就停留在了func1函数中
然后再next,会打印出一个i来

此时从gdb中退出去,可以看到,上面的程序又会继续执行
所以可以看到,如果我们只是想要调试正在运行的程序,还是比较简单的,但想要把函数调试好的话,对于函数的调用栈,也就是用bt去查看函数的调用栈,这也是必须的。
4 调试多进程服务程序
调试父进程:set follow-fork-mode parent(缺省是调试父进程)
调试子进程:set follow-fork-mode child
设置调试模式:set detach-on-fork [on|off],缺省是on
on表示调试当前进程的时候,其它的进程继续运行- 如果用
off,调试当前进程的时候,其它的进程被gdb挂起
查看调试的进程:info inferiors
切换当前调试的进程:inferior 进程id
1 缺省调试,默认调试父进程,子进程继续跑
以下面的代码为例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> // 用于fork()、getpid()、sleep() 和 getppid() 函数
int main(){
printf("begin\n");
if(fork() != 0){
printf("我是父进程:pid = %d, ppid = %d\n", getpid(), getppid());
int i;
for(i = 0; i < 10; ++i){
printf("i = %d\n", i);
sleep(1);
}
exit(0);
} else {
printf("我是子进程:pid = %d, ppid = %d\n", getpid(), getppid());
int j;
for(j = 0; j < 10; ++j){
printf("j = %d\n", j);
sleep(1);
}
exit(0);
}
return 0;
}
调试父进程:set follow-fork-mode parent(缺省是调试父进程)
调试子进程:set follow-fork-mode child
进入gdb调试,缺省调试可以看到
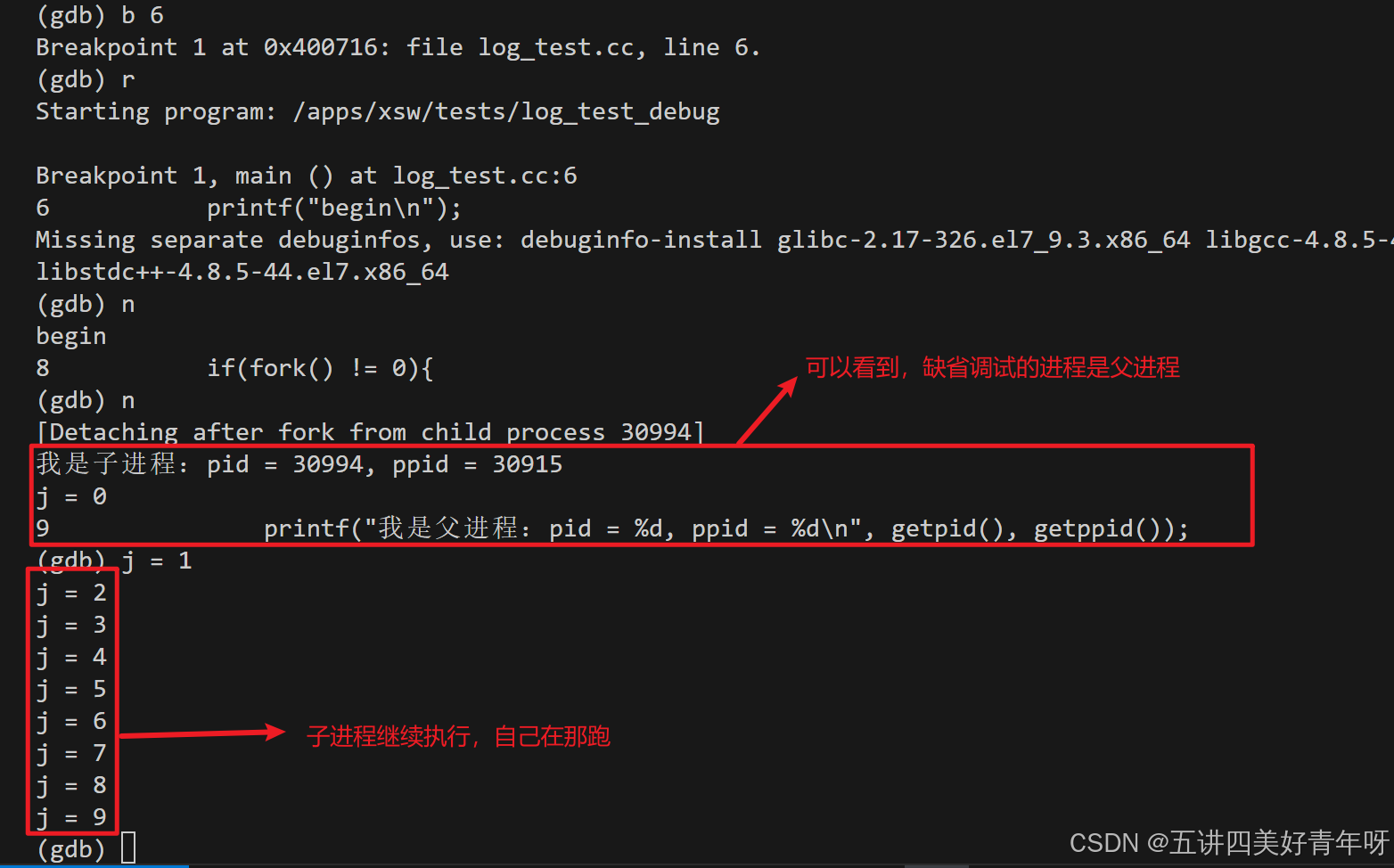
可以看到,缺省调试的进程是父进程,所以父进程停止,子进程继续在跑
接下来用next一步步调试父进程
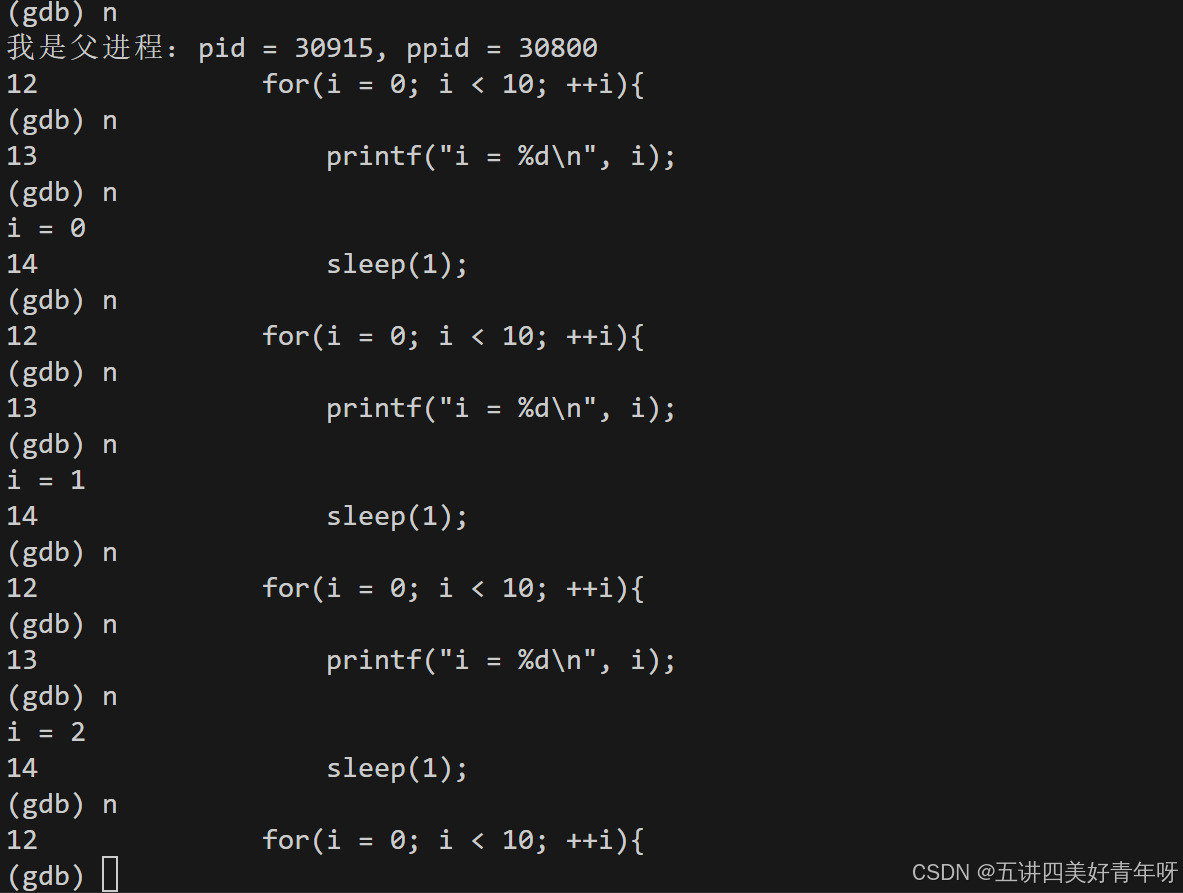
也可以用continue调试
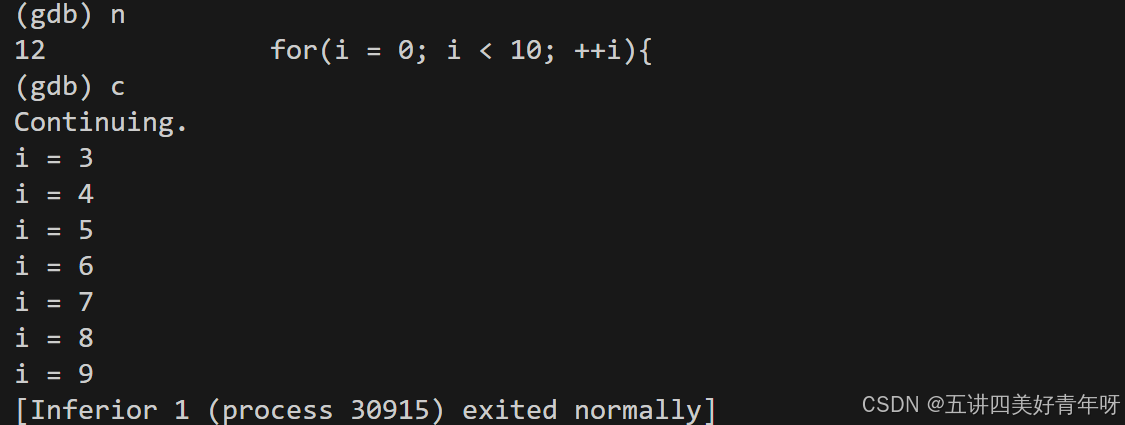
2 调试子进程
使用set follow-fork-mode child调试子进程
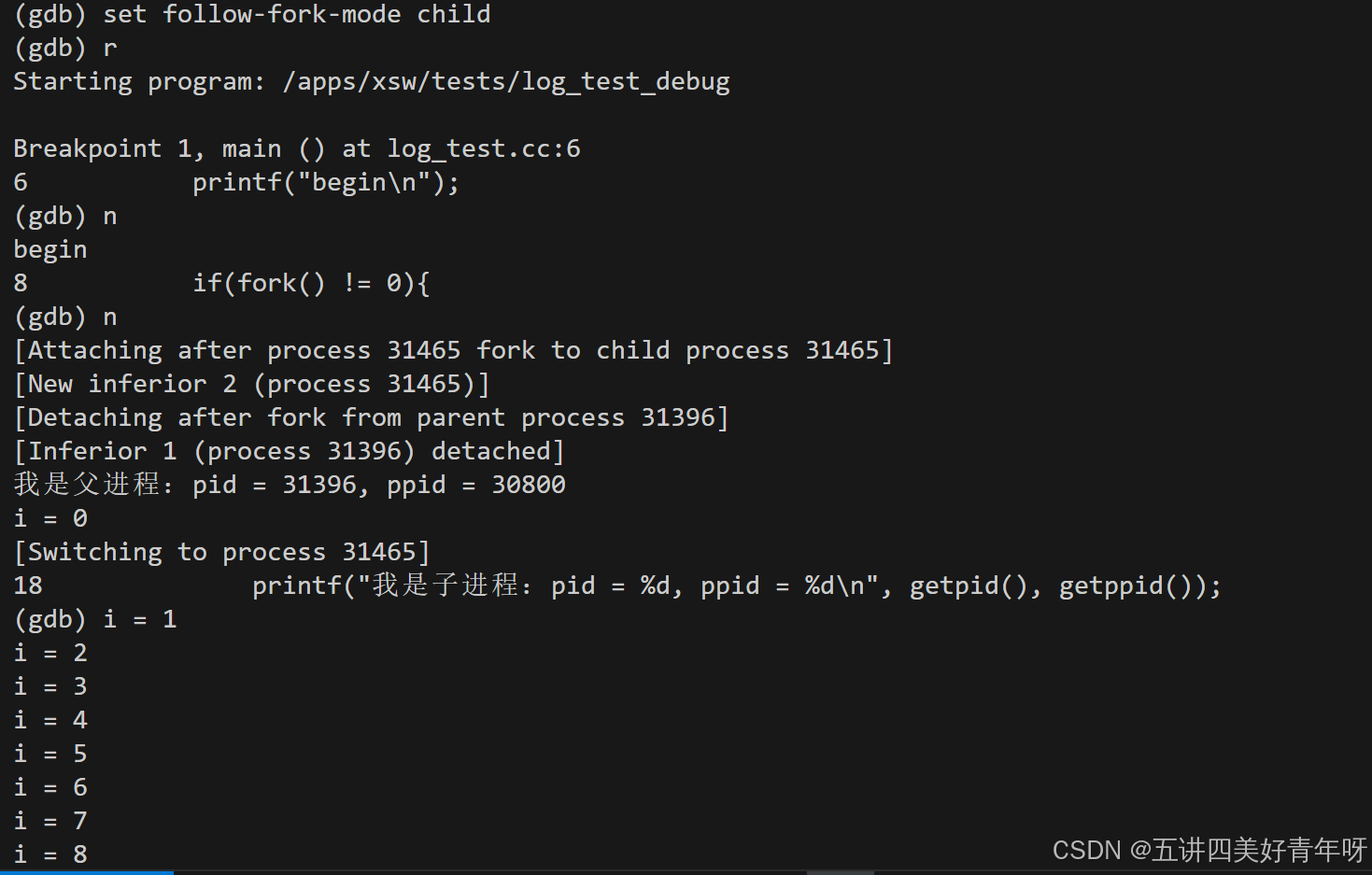
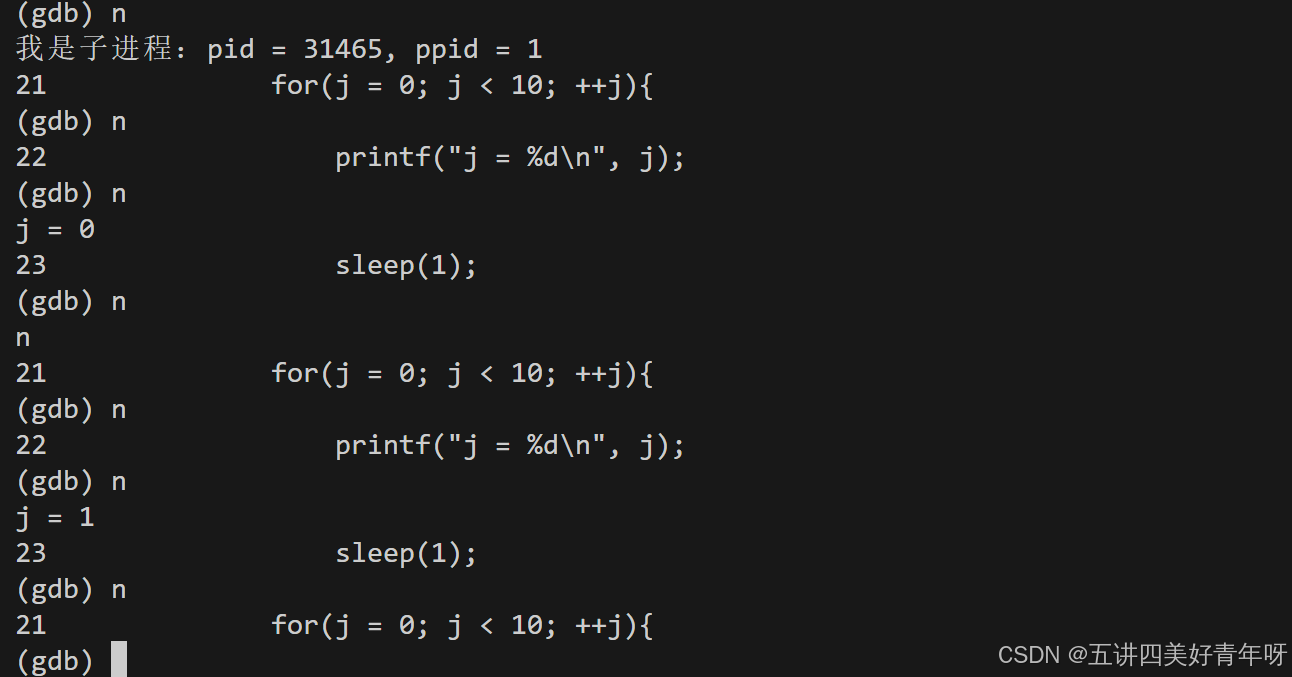
这个时候,父进程在跑,子进程停止了,等着我们来调试它,用next调试子进程
3 设置调试模式
设置调试模式:set detach-on-fork [on|off],缺省是on
on表示调试当前进程的时候,其它的进程继续运行- 如果用
off,调试当前进程的时候,其它的进程被gdb挂起
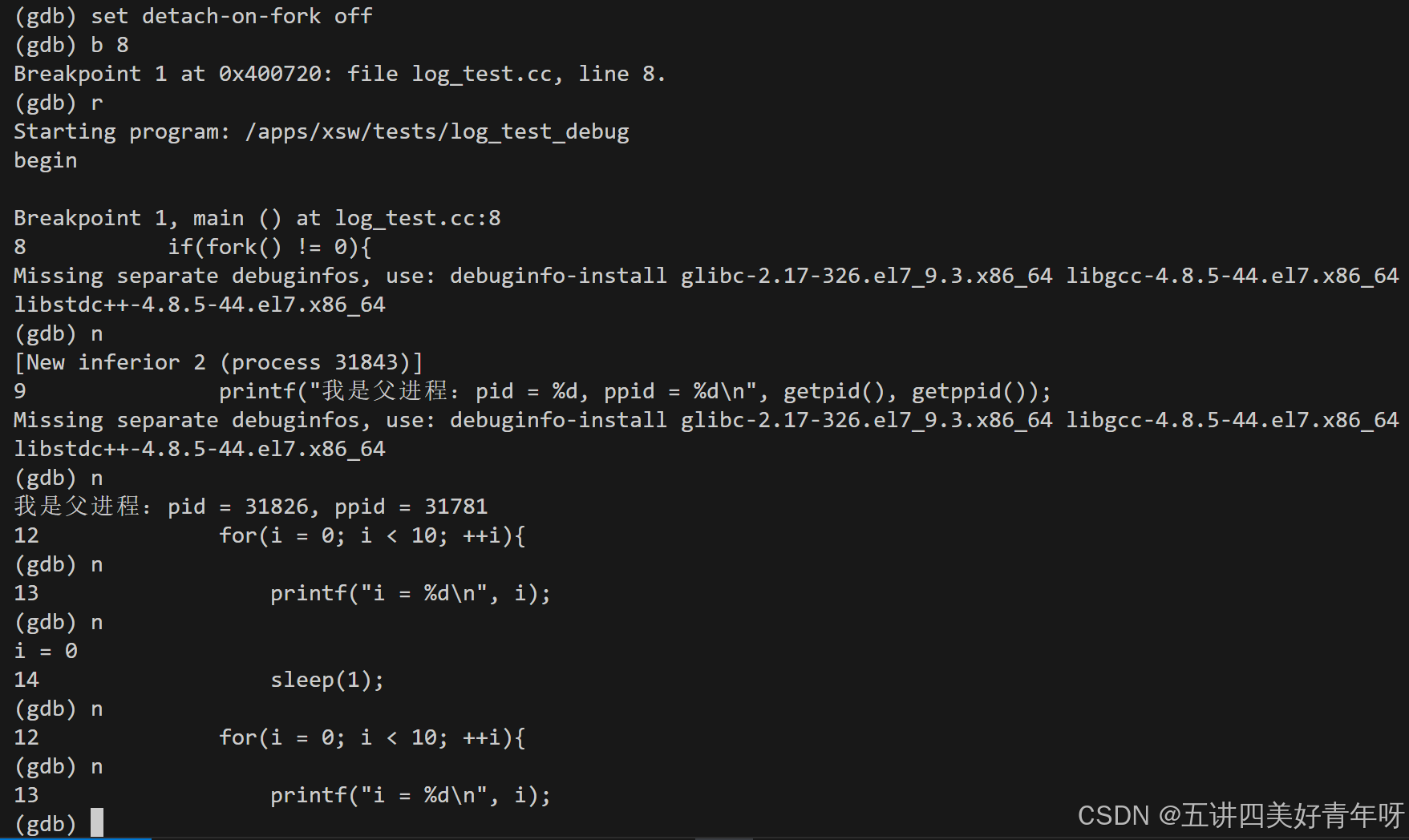
可以看到,此时调试的是父进程,而子进程也没有在跑,停下来了
然后用continue运行父进程
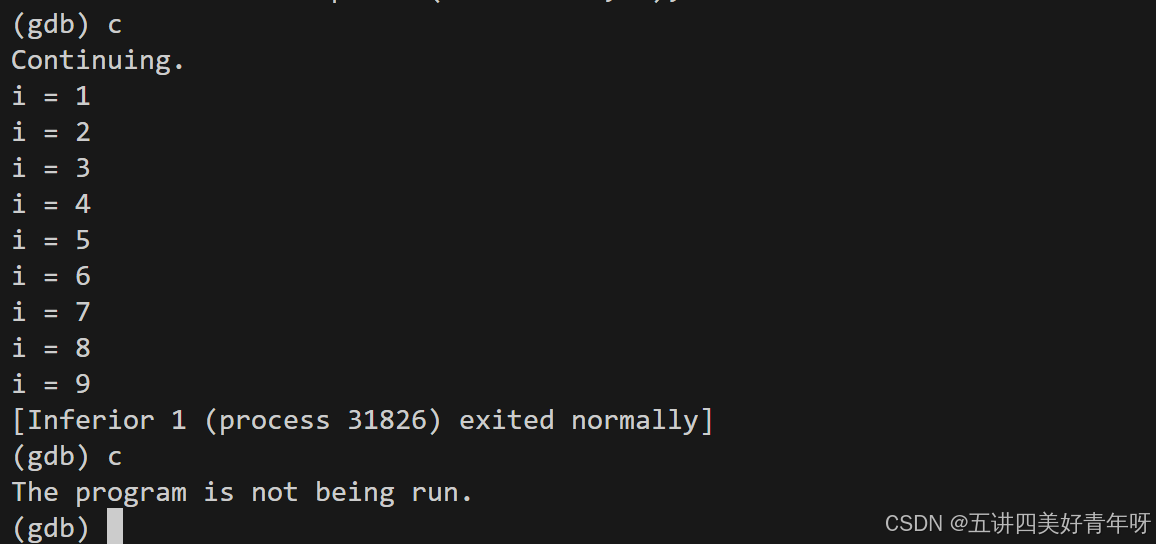
可以看到,最后父进程跑完了,子进程也没有跑
4 查看调试的进程
查看调试的进程:info inferiors
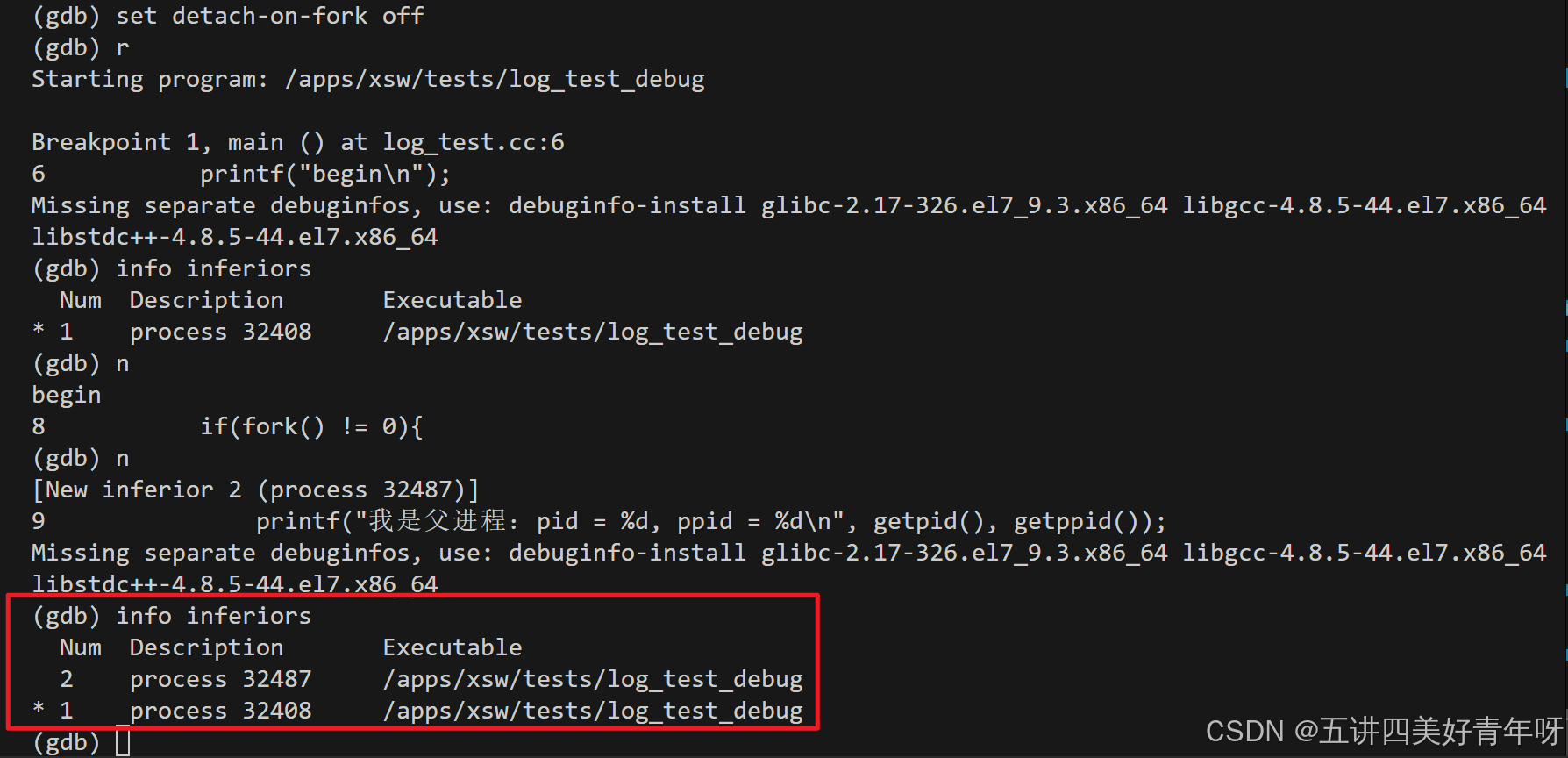
可以看到,当前有两个进程,正在调试的进程是父进程
然后可以切换当前调试的进程
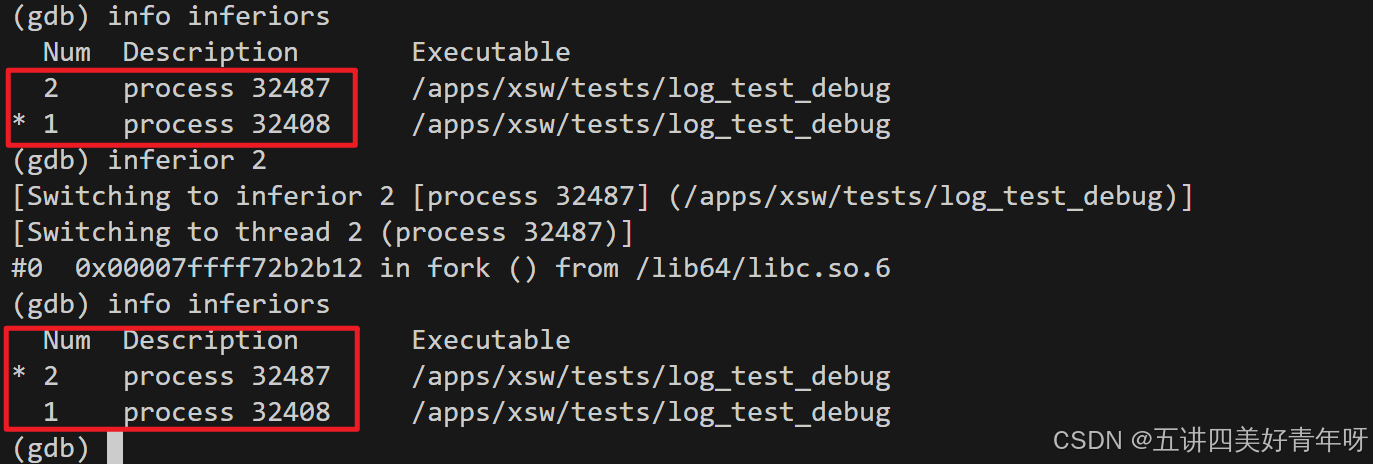
5 切换当前调试的进程
切换当前调试的进程:inferior 进程id
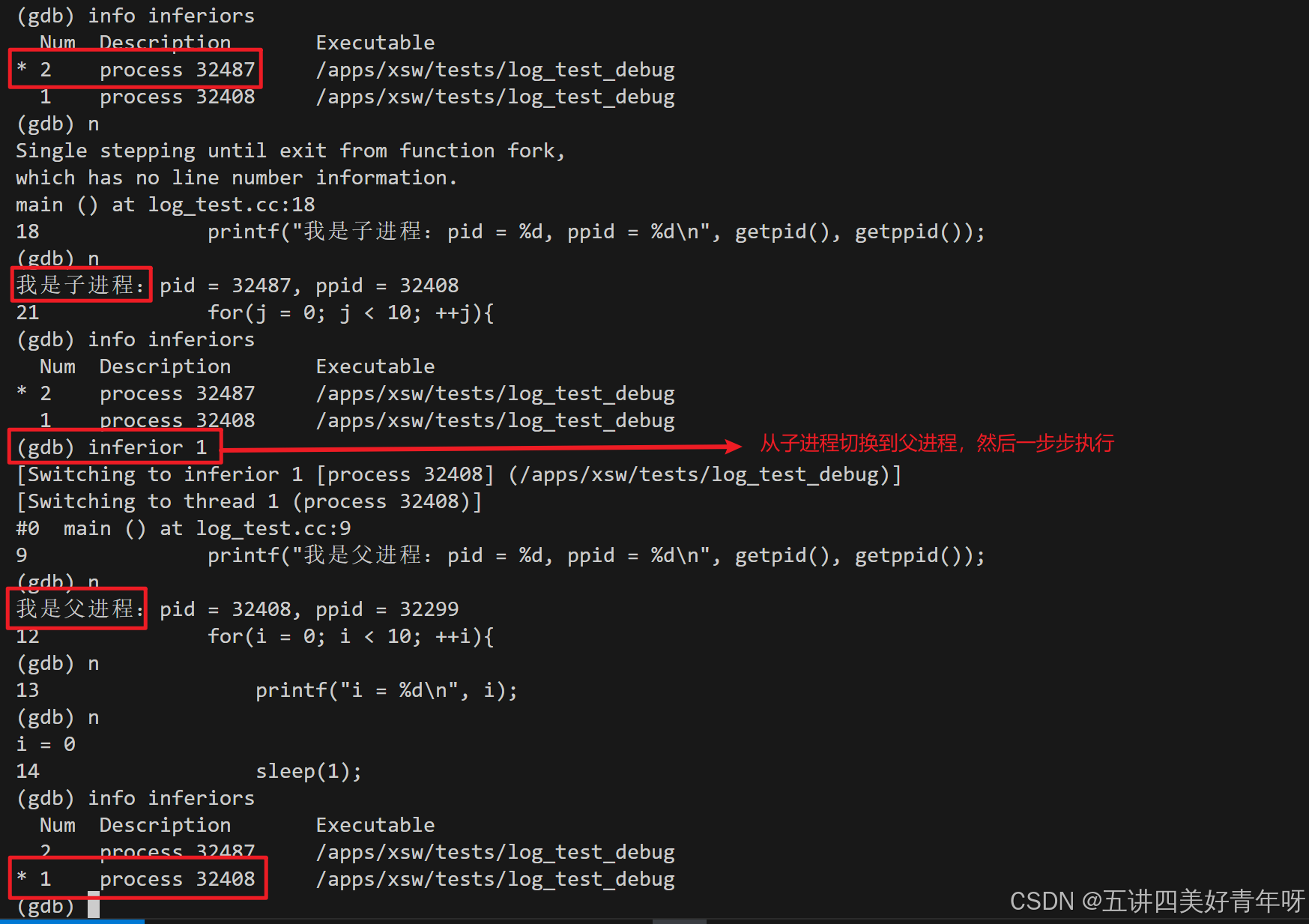
从父进程切换到子进程:
再从子进程切换到父进程,这样就可以想调试哪个进程,就调试哪个进程了
5 调试多线程服务程序
1 一些基本命令
以下面代码为例
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
int x = 0, y = 0; // x用于线程1,y用于线程2
pthread_t pthid1, pthid2;
// 第一个线程的主函数
void *pth1_main(void *arg);
// 第二个线程的主函数
void *pth2_main(void *arg);
int main(){
// 创建线程1
if(pthread_create(&pthid1, NULL, pth1_main, (void*)0) != 0){
printf("pthread_create pthid1 failed.\n");
return -1;
}
// 创建线程2
if(pthread_create(&pthid2, NULL, pth2_main, (void*)0) != 0){
printf("pthread_create pthid2 failed.\n");
return -1;
}
printf("111\n");
pthread_join(pthid1, NULL);
printf("222\n");
pthread_join(pthid2, NULL);
printf("333\n");
return 0;
}
// 第一个线程的主函数
void *pth1_main(void *arg){
for(x = 0; x < 100; ++x){
printf("x = %d\n", x);
sleep(1);
}
pthread_exit(NULL);
}
// 第二个线程的主函数
void *pth2_main(void *arg){
for(y = 0; y < 100; ++y){
printf("y = %d\n", y);
sleep(1);
}
pthread_exit(NULL);
}
然后编译,这里要线程的库链接进来-lpthtead,不然会报错,对‘pthread_create’未定义的引用
g++ -o log_test_debug log_test.cc -g -lpthread
补充几个命令,在shell中执行:
- 查看当前运行的进程:
ps aux | grep log_test_debug - 查看当前运行的轻量级进程:
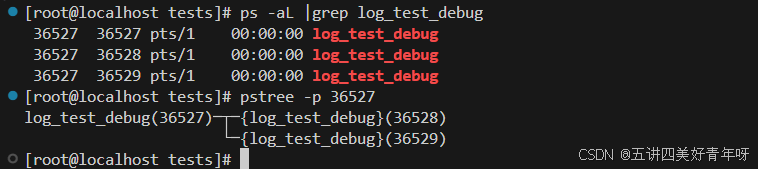
ps -aL | grep log_test_debug - 查看主线程和子线程的关系:
pstree -p 主线程id
这是一个多线程的程序,当它运行时,通过ps aux | grep log_test_debug命令,我们只能看到一个进程

通过ps -aL | grep log_test_debug,可以看到线程,一个主线程,两个子线程,其中36527是主线程,36528和36529是子线程
通过pstree -p 主线程id命令,可以看到线程的关系
2 gdb调试多线程
命令:
查看线程:info threads
切换线程:thread 线程id
只运行当前线程:set scheduler-locking on
运行全部的线程:set scheduler-locking off
指定某线程执行某gdb命令:thread apply 线程id cmd
全部的线程执行某gdb命令:thrread apply all cmd
接下来具体来看
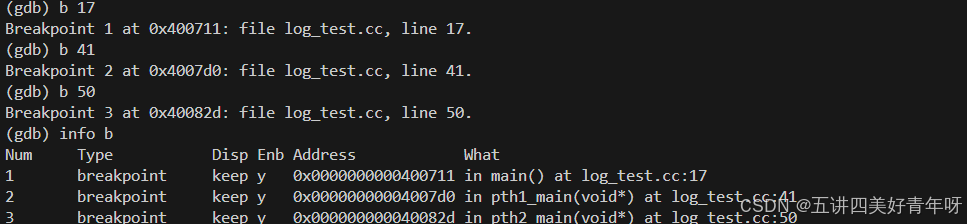
进入gdb后,先打三个断点
1 查看线程
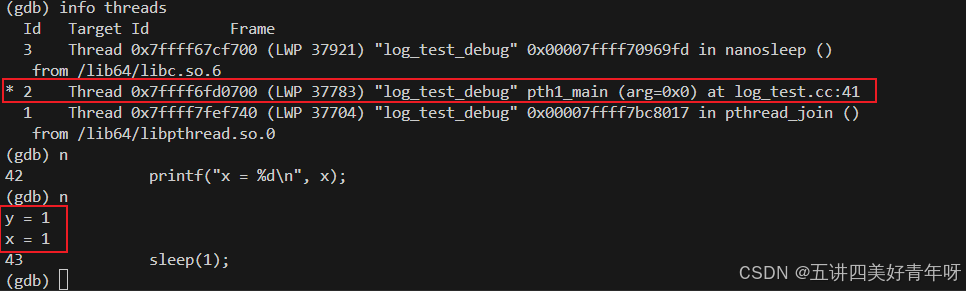
通过info threads命令查看线程信息,从下图可以看出,有三个线程,一个主线程,两个子线程

info threads 输出中的 LWP 代表 Lightweight Process,即轻量级进程;LWP 是在多线程编程中的一个概念,用来表示系统内核为每个线程分配的调度单元。
而这个使用通过info inferiors命令可以看出,而且有三个线程,但只有一个进程

2 切换线程
通过thread 线程id来切换下面,下面切换到线程1去(这里说的线程1和线程2指的是代码中的,而不是info threads显示的线程编号)

切换线程后,next下一步,可以看到线程2和主线程的内容打印出来了
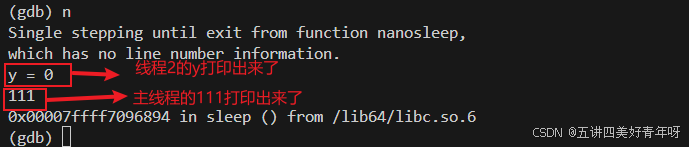
然后继续next下去,你会觉得奇怪,我在线程1上跑,为什么,线程1和线程2,甚至主线程都打印了?
这里其实线程2也在跑,虽然调试的是线程1
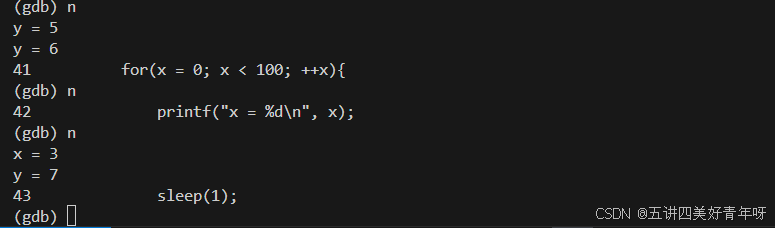
这个时候,可以看到,线程2跑得快一点,y都到7了,x才到3,因为你调试的是当前线程,另外一个线程有时间它就跑
这个时候切换到线程2(也就是编号为3的线程):
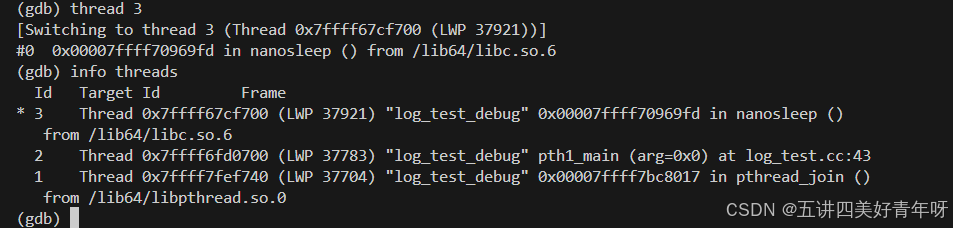
3 只运行当前线程
通过set scheduler-locking on命令,设置只运行当前线程,其他的线程,把它全部挂起来,这里也包括主线程,也都会挂起来(若当前线程不是主线程)
可以看到,当设置了只运行当前线程,由于当前线程是线程2(编号为3的线程),所以只运行线程2,只有y在打印,x没有被打印,因为线程1已经被挂起了
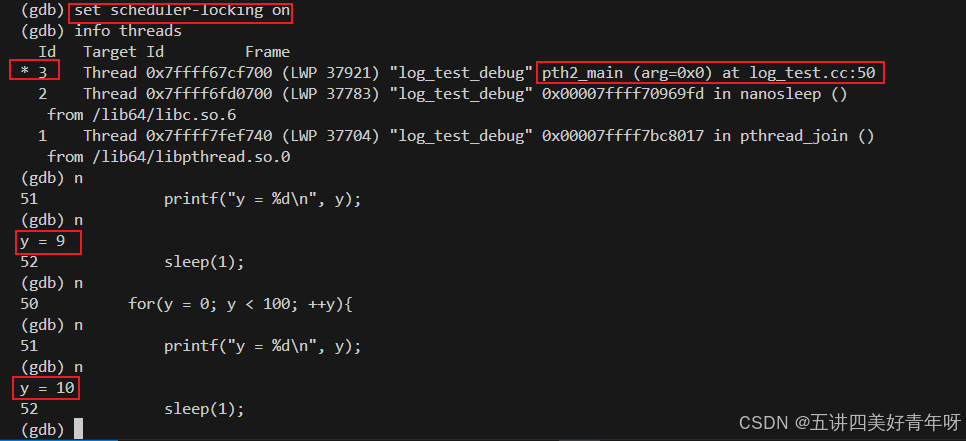
4 运行全部的线程
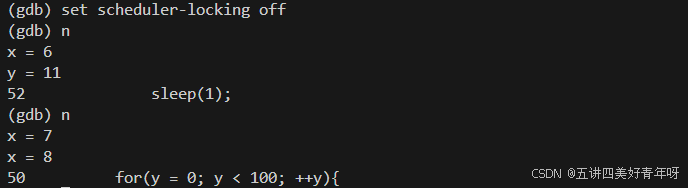
通过set scheduler-locking off命令,设置运行全部的线程,都不要挂起
可以看到,x和y都打印出来了

5 指定某线程执行某gdb命令
打上三个断点:

通过thread apply 线程id cmd命令,可以指定让线程id为2的执行next命令,也可以让线程id为3的执行next命令,如thread apply 2 n 和 thread apply 3 n
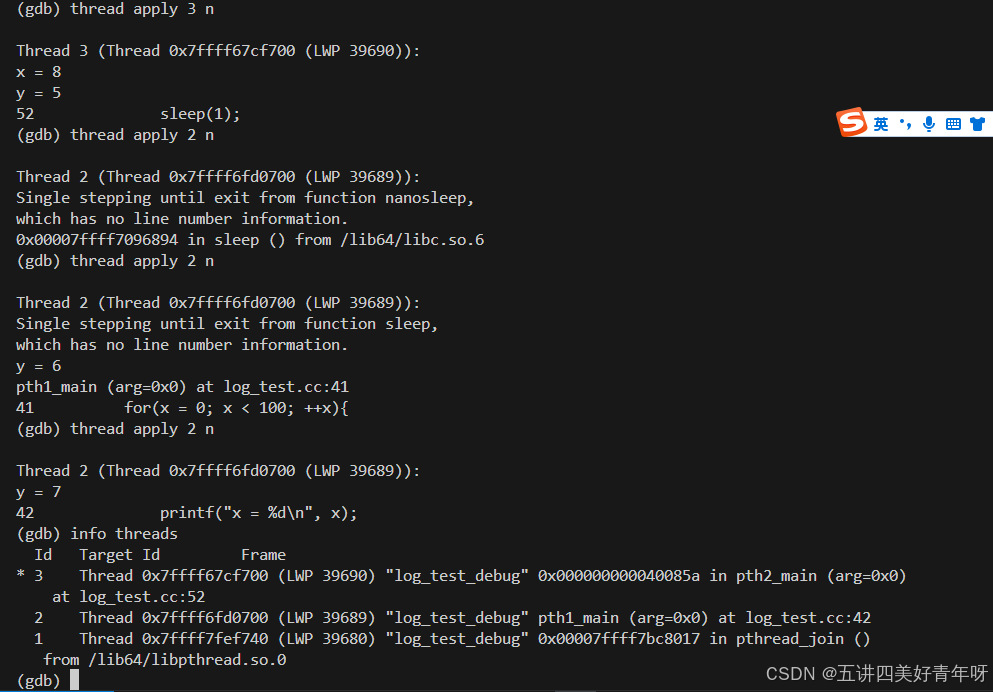
上图中可以看到:
(gdb) thread apply 2 n
Thread 2 (Thread 0x7ffff6fd0700 (LWP 39689)):
Single stepping until exit from function nanosleep,
which has no line number information.
0x00007ffff7096894 in sleep () from /lib64/libc.so.6
意思是:程序的第二个线程(Thread 2)正在执行 nanosleep 或 sleep 函数,gdb 正在单步执行,直到退出 nanosleep 函数。此时程序调用的 sleep 函数没有源代码行号信息,表明它是来自 libc 库的一个系统调用。
6 全部的线程执行某gdb命令
通过thrread apply all cmd命令,让全部的线程执行某gdb命令,例如thrread apply all n
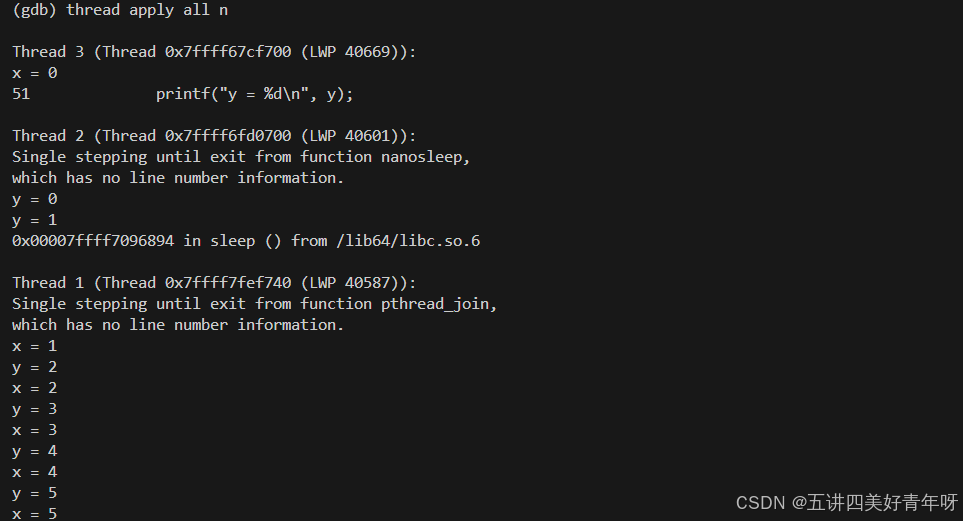
3 总结
以上就是多线程gdb调试的命令和一些演示,自己要多试试,熟能生巧!!!!!
6 绝招:采用输出日志的方法来调试多进程和多线程的服务程序
1 采用设置断点和单步的方式调试多线(进)程的问题
做过后台服务开发的,就会非常清楚,设置断点或单步跟踪可能会严重干扰多进(线)程之间的竞争关系,导致我们看到的是一个假象。
一旦我们在某一个线程设置了断点,该线程在断点处停住了,只剩下另一个线程在跑。这个时候,并发的场景已经完全被破坏了,通过调试器看到的只是一个和谐的场景(理想状态)。
调试着的调试行为干扰了程序的运行,导致看到的是一个干扰后的现象。
既然断点和单步不一定好用,那怎搞?
绝招:输出log日志,它可以避免断点和单步所导致的副作用。
这里把上面4和5部分的两个代码分别放入gdbfork.cc和gdbthread.cc中

gdbfork.cc代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> // 用于fork()、getpid()、sleep() 和 getppid() 函数
#include "_freecplus.h"
int main(){
CLogFile logfile;
logfile.Open("/apps/xsw/tests/gdbfork.log", "w+");
logfile.Write("begin\n");
if(fork() != 0){
logfile.Write("我是父进程:pid = %d, ppid = %d\n", getpid(), getppid());
int i;
for(i = 0; i < 10; ++i){
logfile.Write("i = %d\n", i);
sleep(1);
}
exit(0);
} else {
logfile.Write("我是子进程:pid = %d, ppid = %d\n", getpid(), getppid());
int j;
for(j = 0; j < 10; ++j){
logfile.Write("j = %d\n", j);
sleep(1);
}
exit(0);
}
return 0;
}
gdbthread.cc代码如下:
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include "_freecplus.h"
// 把对象定义为全局的
CLogFile logfile;
int x = 0, y = 0; // x用于线程1,y用于线程2
pthread_t pthid1, pthid2;
// 第一个线程的主函数
void *pth1_main(void *arg);
// 第二个线程的主函数
void *pth2_main(void *arg);
int main(){
// 打开日志文件
logfile.Open("/apps/xsw/tests/gdbthread.log", "w+");
// 创建线程1
if(pthread_create(&pthid1, NULL, pth1_main, (void*)0) != 0){
logfile.Write("pthread_create pthid1 failed.\n");
return -1;
}
// 创建线程2
if(pthread_create(&pthid2, NULL, pth2_main, (void*)0) != 0){
logfile.Write("pthread_create pthid2 failed.\n");
return -1;
}
logfile.Write("111\n");
pthread_join(pthid1, NULL);
logfile.Write("222\n");
pthread_join(pthid2, NULL);
logfile.Write("333\n");
return 0;
}
// 第一个线程的主函数
void *pth1_main(void *arg){
for(x = 0; x < 10; ++x){
logfile.Write("x = %d\n", x);
sleep(1);
}
pthread_exit(NULL);
}
// 第二个线程的主函数
void *pth2_main(void *arg){
for(y = 0; y < 10; ++y){
logfile.Write("y = %d\n", y);
sleep(1);
}
pthread_exit(NULL);
}
2 解决方法
1 多进程
在屏幕上输出
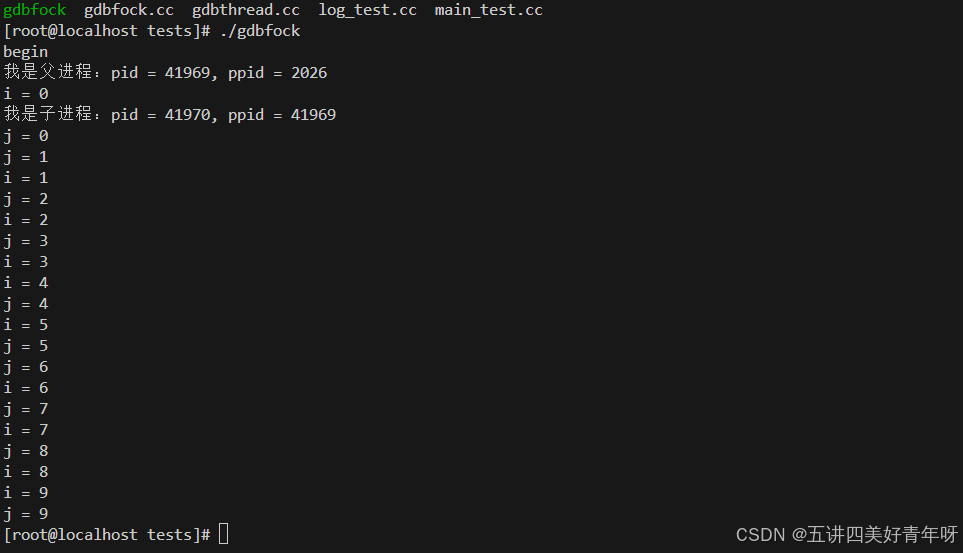
这么做有两个问题:
- 一个是,如果输出的日志比较多,那屏幕根本没法看,满屏都是
- 另外一个,没有准确的记录时间,也就是没有记录在什么时间,产生了什么日志,这个非常重要,这里就没有记录
这里就需要一个把日志记录到文件里的工具,我在这里使用freecplus框架,具体见这篇博客
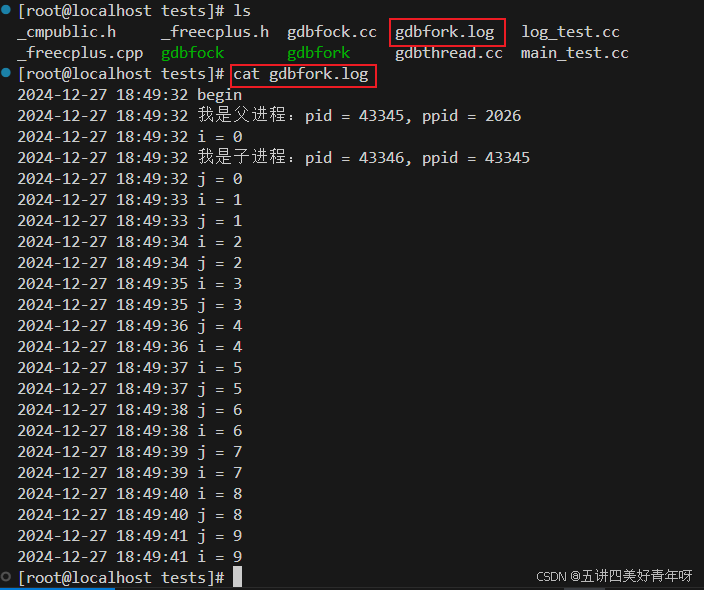
通过freecplus后,具体的编译和运行见下图:

然后运行完成后,日志会输出到这里面/apps/xsw/tests/gdbfork.log
2 多线程
如下例子
g++ -o gdbthread gdbthread.cc -g _freecplus.cpp -lpthread
分别解释下这个命令的参数是什么意思
g++:这是 GUN C++编译器,用于编译和连接C++代码。它可以处理C++源文件(.cc、.cpp等)并生成可执行文件-o gdbthread:这是指定 输出文件的名字。-o后面跟着生成的可执行文件的名字。在这个例子中,输出文件将命名为 gdbthread。gdbthread.cc:这是输入的 源代码文件,即包含 C++ 代码的源文件。编译器会根据这个文件生成目标代码。这里的 gdbthread.cc 是你编写的 C++ 源文件,文件扩展名通常是 .cc 或 .cpp,表示 C++ 源代码文件。-g:这个选项告诉编译器在生成目标文件时 生成调试信息。调试信息包括变量名称、行号等信息,这样在调试时(例如使用 GDB 调试器)可以提供更有用的反馈。当程序崩溃时,调试信息可以帮助开发人员定位问题。_freecplus.cpp:这是另一个源文件,通常用于链接和编译的第二个源代码文件。_freecplus.cpp 文件被包含在编译过程中,和 gdbthread.cc 一起编译链接。-lpthread:这是 链接选项,用于指定要链接的库。-lpthread表示在编译过程中链接 POSIX 线程库(pthread),该库提供了多线程编程支持。在多线程程序中,使用 pthread 库来管理线程,创建线程、同步线程、销毁线程等。需要使用这个选项才能正确链接多线程相关的函数。

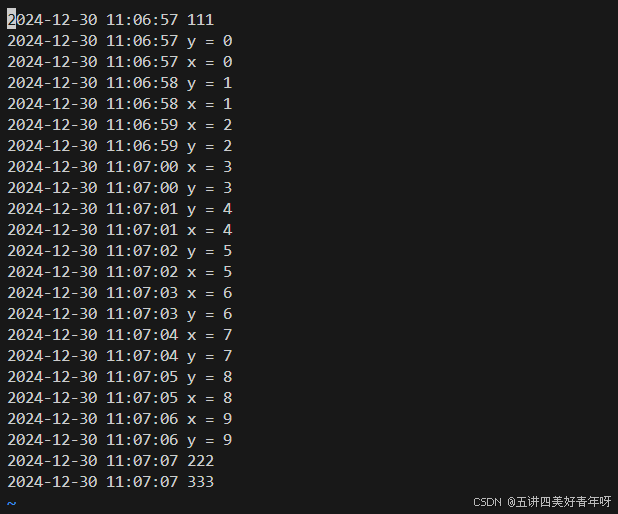
通过vi gdbthread.log查看日志文件的内容如下:


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











