







电商交易数据清洗和分析
数据源:csv文件,某电商的交易数据,需要对这部分数据进行清洗和分析
工具:python(matplotlib/numpy/pandas),jupyter实现
数据清洗
加载数据分析需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt加载数据,加载数据之前先用文本编辑器查看一下数据格式,首行和分隔符等
df = pd.read_csv('./order_info_2016.csv',index_col='id') #index_col='id' 表示将id这一列作为行索引
df.index.name=None #去掉行索引的名字
df.head() #查看一下前5行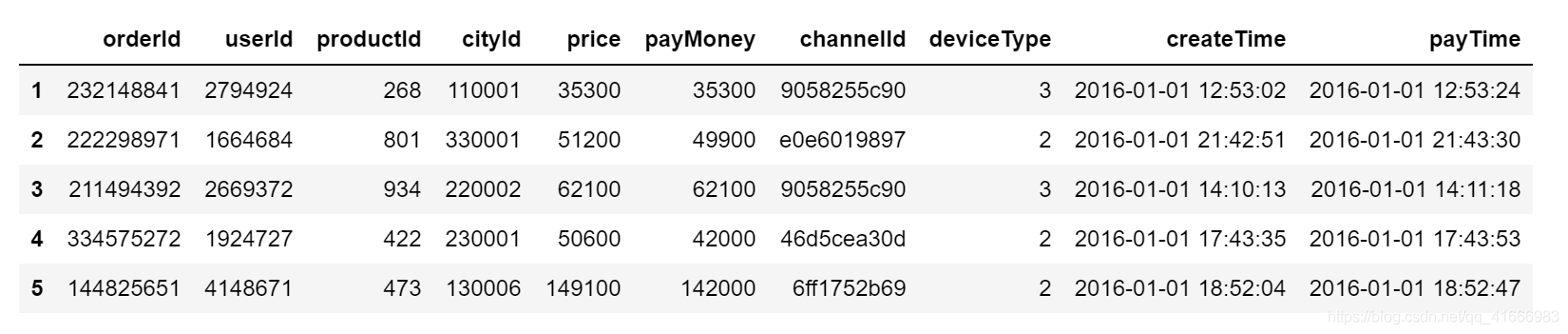
加载好数据后,先分别使用describe和info方法看下数据的分布情况
df.describe()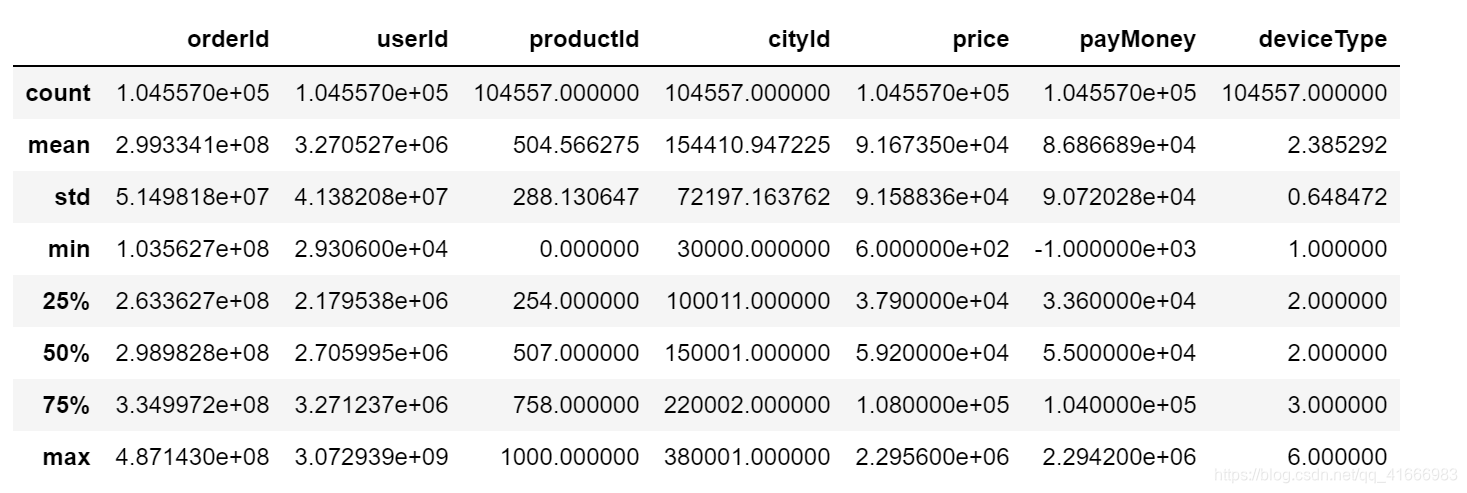
df.info()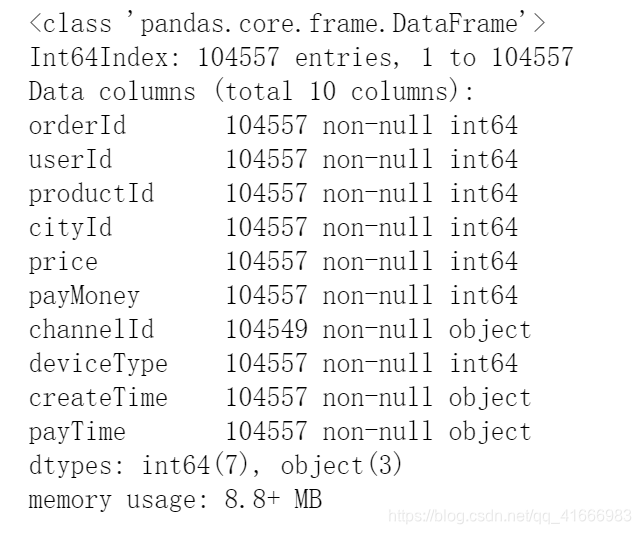
可以看出数据总量是104557,其中channelId有缺失数据,后续要对它进行处理
先整体看一下有没有重复数据
df[df.duplicated()] #为空,即没有完全重复的数据orderId
我们都知道orderId在一个系统中是唯一的,因此需要查看一下其是否满足唯一性
df[df['orderId'].duplicated()] #确有重复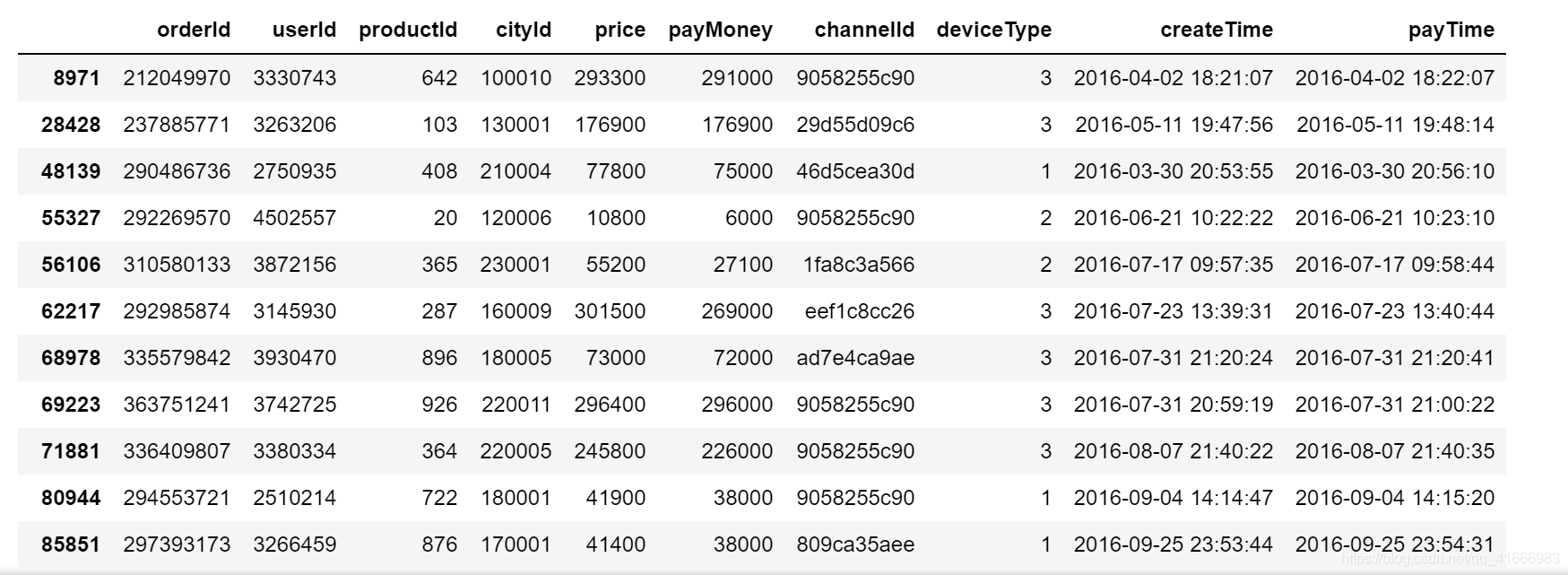
我们也可以验证一下
df[df['orderId']==212049970]
#以下方法也可以查看是否存在重复
df['orderId'].unique().size #104530
df['orderId'].size #104557如果有重复,我们一般也是最后处理,因为其他列可能影响重复值,我们先处理其他列
userId
userId,我们只要从上边的describe和info中查看其值在正常范围内就可以了,对于订单数据,一个用户可能有多个订单,重复是合理的
productId
productId的最小值为0,先来看一下为0的记录数
df.productId[(df.productId==0)].size #177177条记录,数量不多,可能是商品的上下架引起的,处理完其他值我们把这些删掉
cityId
cityId类似于userId,值都在正常范围,不需要处理
price
price没有空值,且都大于0,注意单位是分,我们把它转换成元
df.price = df.price/100payMoney
payMoney中存在负值,不符合逻辑,因此要删除掉这写记录
#展示payMoney为负值的记录
df[df['payMoney']<0]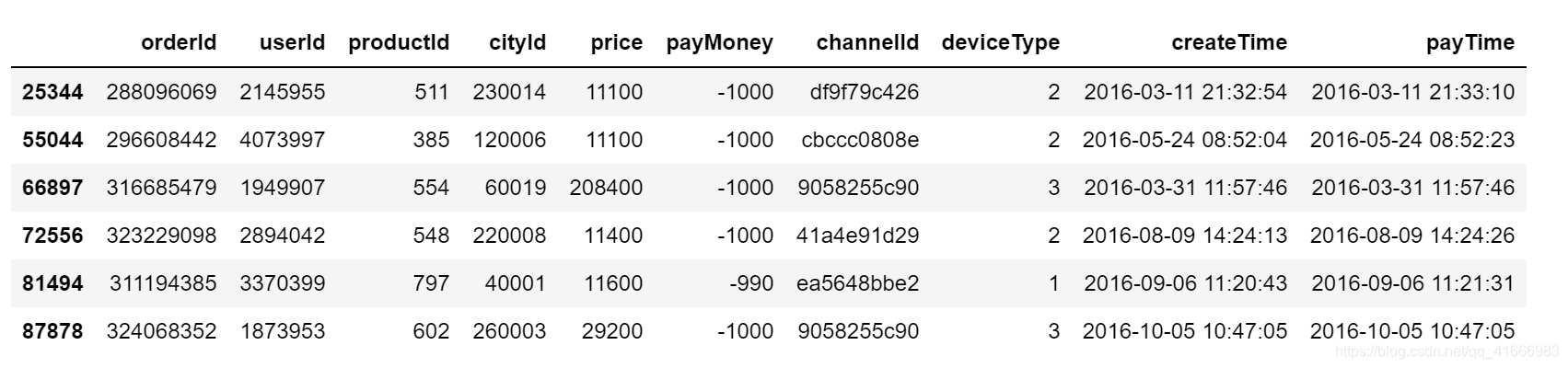
#删除payMoney为负的记录
df.drop(df[df['payMoney']<0].index,inplace=True)#再检查一下
df[df['payMoney']<0] #为空#变成元
df.payMoney = df.payMoney/100channelId
channelId根据info结果,有些nu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









