







 本文介绍了word2vec的基本概念,包括Skip-gram和CBOW两种模型的原理,详细阐述了Skip-gram模型的神经网络架构,并探讨了训练参数如min_count、size和workers的影响。此外,还提供了原始语料的处理方法和word2vec模型的训练及保存流程。
本文介绍了word2vec的基本概念,包括Skip-gram和CBOW两种模型的原理,详细阐述了Skip-gram模型的神经网络架构,并探讨了训练参数如min_count、size和workers的影响。此外,还提供了原始语料的处理方法和word2vec模型的训练及保存流程。
word2vec model
1.介绍
word2vec是一种用于词向量计算的工具。它使用浅层神经网络将单词嵌入低维向量空间中,结果是一组词向量,其中在向量空间中靠在一起的向量根据上下文具有相似的含义,而彼此远离的词向量具有不同的含义。
2.原理
word2vec有两个版本:Continuous-bag-of-words (CBOW)和Skip-gram (SG),下面分别作介绍。
2.1 Skip-gram
Word2Vec使用了您可能在机器学习的其他地方见过的一个技巧。我们将训练一个具有单个隐藏层的简单神经网络来执行特定任务,但是实际上,我们将不会使用该神经网络来训练我们的任务! 相反,目标实际上只是学习隐藏层的权重,这些权重实际上就是我们试图学习的“词向量”。
通过下面的讲解将详细体现Skip-gram模型的实现过程。
首先我们知道,我们不能像输入文本字符串一样把单词输入到一个神经网络,所以我们需要一种将单词表示到网络的方法。为此,我们首先从训练文档中构建词汇表-假设我们有10,000个独特单词的词汇表。
我们将把“ants”之类的输入词表示为一个单向向量。 此向量将包含10,000个成分(词汇中的每个词一个),我们将在与“ants”对应的位置放置“ 1”,在所有其他位置放置0。
网络的输出是单个向量(也具有10,000个组成部分),对于我们的词汇表中的每个单词,包含一个随机选择的邻近单词就是该词汇表单词的概率。
下面是神经网络的架构:
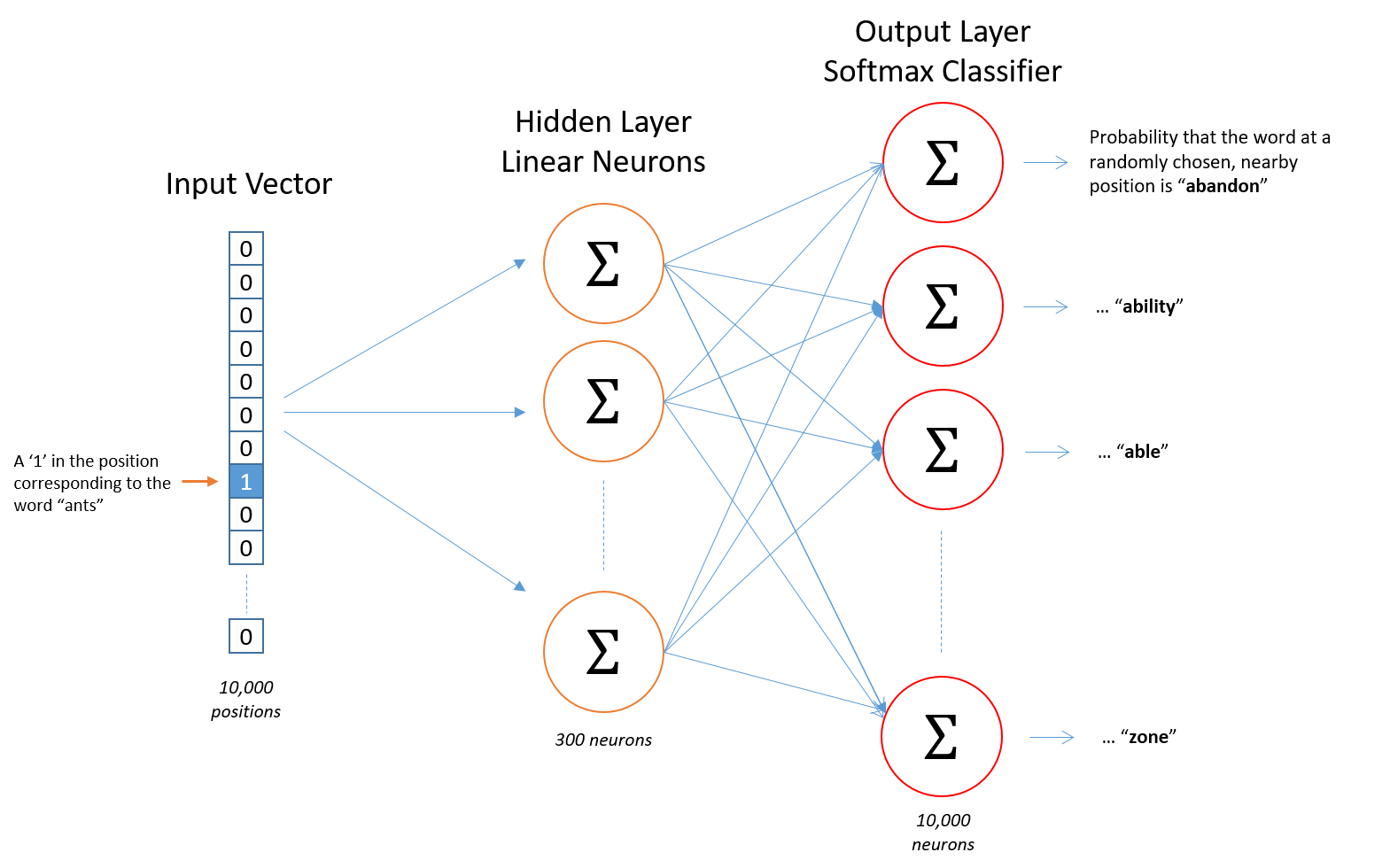
隐藏层神经元上没有激活功能,但是输出神经元使用softmax。 我们稍后会再讨论。
当在单词对上训练此网络时,输入是代表输入单词的one-hot向量,输出也是代表单词的one-hot向量。但是,当在输入单词上评估经过训练的网络时,输出向量实际上将是概率分布(即一堆浮点值,而不是一个one-hot向量)。
对于示例,我们正在学习具有300个特征的单词向量。因此,隐藏层将由权重矩阵表示,该矩阵具有10000行,(词汇表中的每一个单词一个)和300列(每个隐藏神经元一个)。此权重矩阵的行实际上就是我们的词向量。
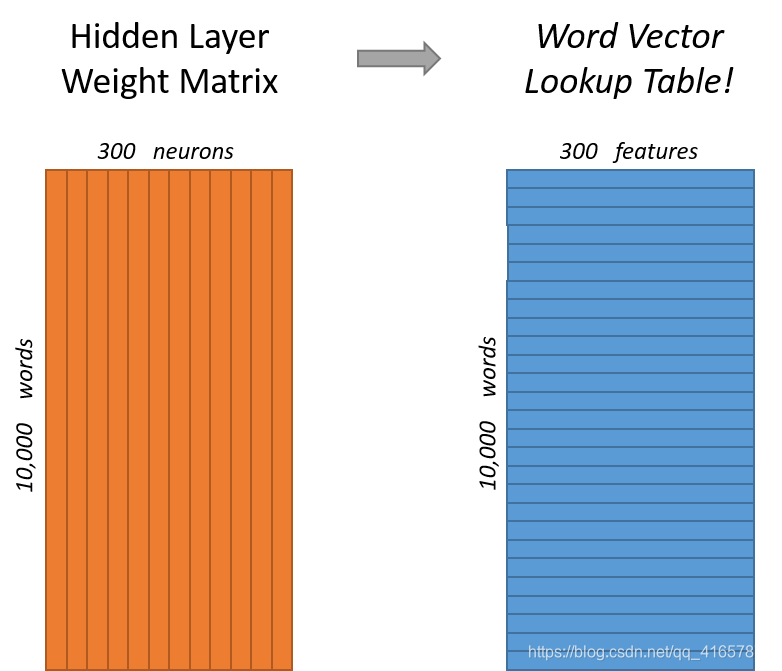
因此,所有这一切的最终目标实际上只是学习此隐藏层权重矩阵,完成后将扔掉输出层!
有一个问题:“one-hot向量几乎全为零……这有什么作用?”如果将一个1 x 10,000个one-hot向量乘以10,000 x 300矩阵,它实际上将选择 对应于“ 1”的矩阵行。 下面是一个例子:

这意味着该模型的隐藏层实际上只是用作查找表。 隐藏层的输出只是输入单词的“词向量”。
接下来将“ants”的1×300词向量送入输出层,这里的输出层是一个Softmax回归分类器。即每个输出神经元(词典中的每个单词)将产生0-1之间的输出,所有输出值的总和为1.
下面是计算单词“ car”的输出神经元输出的示例:

注意,神经网络对输出词相对于输入词的偏移一无所知。 对于输入之前的单词和之后的单词,它不会学习不同的概率集。 为了理解其含义,可以说在我们的训练语料库中,每个“ York”的出现都以“ New”开头。 也就是说,至少根据训练数据,“ New”将在“ York”附近的可能性为100%。 但是,如果我们在“York”附近选择10个单词,并随机选择其中一个,为“New”的可能性不是100%; 你可能在附近选择了其他单词之一。
这里存在一个问题,Skip-gram神经网络包含大量权重……对于示例,具有300个特征和10,000个单词的词汇,隐藏层和输出层中的权重均为3M! 在大型数据集上进行训练是行不通的的,因此word2vec的作者进行了许多调整以使训练可行。 这将涉及到skip-gram 模型优化的策略Negative Sampling,它使得模型更加快速地训练。
2.2 CBOW
CBOW模型与Skip-gram模型非常相似。 它也是一个1层神经网络。 合成训练任务现在使用多个输入上下文单词的平均值,而不是像Skip-gram模型中的单个单词来预测中心单词。 同样,将权重词转换为与隐藏层相同宽度的平均向量的投影权重也被解释为词嵌入。
在连续的单词模型中,上下文由给定目标单词的多个单词表示。例如,我们可以使用“cat”和“tree”作为“攀爬”的上下文单词作为目标单词。这需要修改神经网络架构。如下所示,修改包括将隐藏层连接的输入复制C次,上下文单词的数量,以及在隐藏层神经元中添加除C操作。[警报读者指出,下图可能会让一些读者认为CBOW学习使用了几个输入矩阵。不是这样。它是相同的矩阵WI,它接收代表不同上下文词的多个输入向量]
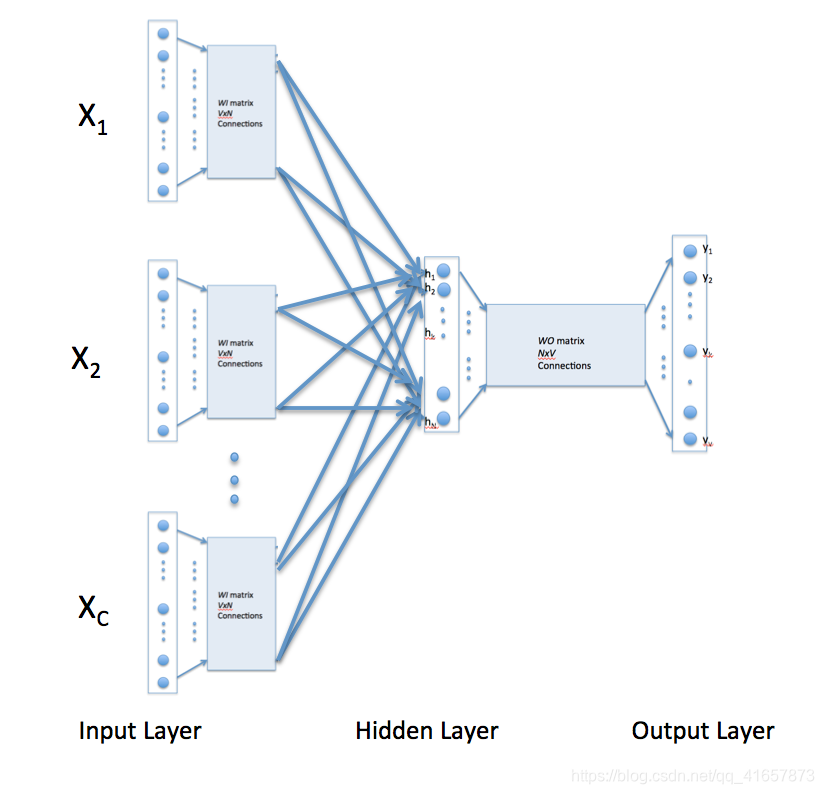
利用上述配置来指定C上下文字,使用1-out-of-V表示编码的每个字意味着隐藏层输出是与输入处的上下文字相对应的字矢量的平均值。输出层保持不变,并且以上面讨论的方式完成训练。
3.训练参数
3.1 min_count
min_count用于修剪内部字典。 在十亿个单词的语料库中仅出现一次或两次的单词可能是无趣的错别字或者垃圾。 此外,没有足够的数据来对这些单词进行任何有意义的训练,因此最好忽略它们:
default value of min_count=5
model = gensim.models.Word2Vec(sentences, min_count=10)3.2 size
size是gensim Word2Vec将单词映射到的N维空间的维数(N)。较大的size值需要更多的训练数据,但可以产生更好(更准确)的模型。 合理的值在数十到数百之间。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









