







-
java中有几种基本数据类型
byte、shot、int、long、float、double、char、 boolean -
String
- String重写了hashcode方法和 equals方法。
- 常量找池、变量找堆,new出来的也在堆里。(如果是常量,没有进堆,就没有内存地址一说, 只要值一样,==就相等)
//常量 System.out.println(a == "abc");//true System.out.println(d == "abc");//true System.out.println(a == "ab" + "c");//true //变量,也就是字符串拼接为什么不用String,而用Stringbuffer、StringBuilder System.out.println(a == (b + c));//false System.out.println(a == (b + "c"));//false - string.intern()的值在池中。
String a = "abc"; String b = new String("abc"); System.out.println(a == b.intern());//true System.out.println(a.intern() == b.intern());//true System.out.println(a == "abc".intern());//true - 基本数据类型传的是值。
new传的是地址。
String会先去池中找,找不到会去堆里找。
public static void main(String[] args) { int a = 0; Product product = new Product(); product.setContent("内容"); String string = new String("test"); String string2 = test"; UploadAndDownloadApplication up = new UploadAndDownloadApplication(); up.test1(a); //传的是引用,到堆里面 up.test2(product); //传的是String对象 up.test3(string); //传的是String值 up.test4(string2); System.out.println(a);//0 System.out.println(product.getContent());//xxx System.out.println(string);//test System.out.println(string2);//test } public void test1(int a){ a = 30; } //是同一个地址,修改掉 public void test2(Product product){ product.setContent("xxx"); } //传入String string = new String("test");在堆里 //堆 String test = "xxx"; //先去池中找没有string,再去堆找string,找到“test” public void test3(String string){ string = "xxx"; } //传入String string = "test";在池中 //堆 String test = "xxx"; //先去池中找没有string,再去池找string,找到“test” public void test4(String string){ string = "xxx"; }
- 常量找池、变量找堆,new出来的也在堆里。(如果是常量,没有进堆,就没有内存地址一说, 只要值一样,==就相等)
- String重写了hashcode方法和 equals方法。
-
int占几个字节
4个字节 32位 -
面向对象的特征
封装、抽象、继承、多态。 -
==和equals的区别
- 内存地址、hashcode、equals三者不同。
- == 既可以比较基本类型也可以比较引用类型。对于基本类型就是比较值,对于引用类型就是比较内存地址(不是hashcode)。
- equals 他是属于lava.lang.Object类里面的方法,如果该方法没有被重写过默认也是==,我们可以看到String类的equals方法是被重写过得,而且String类在日常开发中用的比较多,久而久之,形成了equals是比较值得错误观点。
- 具体要看这有没有重写Object的hashcode方法和equals方法来判断。重写equals方法,equals就相当,重写了equals和hashcode,则二者都相等。
//字符串重写的equals方法 String a = new String("aaa"); String b = new String("aaa"); System.out.println(a == b); // false System.out.println(a.equals(b)); // true Product product1 = new Product(); Product product2 = new Product(); //没有重写equals方法和hashCode方法 System.out.println(product1 == product2);//false System.out.println((product1.equals(product2));//false //set里面重复是根据hashcode值和equals是否一样来判断 Set<Product> set = new HashSet<>(); set.add(product1); set.add(product2); System.out.println(set.size());//2 //重写equals方法 System.out.println(product1 == product2);//false System.out.println(product1.equals(product2));//true //set长度为2 //重写hashcode方法 System.out.println(product1 == product2);//false System.out.println(product1.equals(product2));//false //set长度为2 //重写hashcode方法和equals方法 System.out.println(product1 == product2);//false System.out.println(product1.equals(product2));//true //set长度为1 -
-
为什么hashCode方法,有31这个数字。
-
31是个质数,在存储数据计算hash地址的时候,我们希望尽量减少有相同的地址。
-
n*31就可以被JVM优化为(n<<5)-n,移位和减法的操作效率要比惩罚的操作效率高的多,对左移虚拟机里面都有相关优化,并且31只占用5bits.
-
-
- 内存地址、hashcode、equals三者不同。
-
装箱和拆箱
- 装箱:把基本的数据类型转换成对象类型。
- 拆箱:把包装类型转换为基本数据类型,
int a = Integer.valueOf(5); //自动装箱 Integer b = Integer.valueOf(a);
-
String、StringBuffer、StringBuilder
- String是不可变长度,被final修饰,拼接字符串的时候,会每次创建一个对象。
- StringBuffer是可变长度,所有方法被synichronized修改,是线程安全的
- StringBuilder 没有修饰词,相比StringBuffer要快
String c = "aa"; //private final char value[]; StringBuffer stringBuffer = new StringBuffer(); //synchronized char[] value; stringBuffer.append("a").append("b"); StringBuilder stringBuilder = new StringBuilder(); // char[] value; stringBuilder.append("a").append("b");
-
java中的集合
- List是有序的,可以重复
- Set是无序的,不可以重复,根据equals和hashcode判断,一个对象要存储在Set中,必须重写equals和hashCode方法。
- map存储key-value
-
ArrayList和LinkedList 区别
- ArrayList底层使用数组,数组查询具有所有查询特定元素比较快,而插入和删除和修改表较慢(数组在内存中是一块连续的内存,如果插入或删除是需要移动内存的) ,ArrayList每次扩容1.5倍,还要将老数组copy到新数组上。
- LinkedList 使用的是链表,链表不要求内存是连续的,查询时需要从头部开始,一个一个的查找,效率低下。插入式不需要移动内存,只需要链头或者链尾插入。
-
HashMap和HashTable的区别

-
字节流和字符流
-
InputStream 和OutputStream,两个是为字节流设计的,主要用来处理字节或二进制对象
-
Reader和 Writer.两个是为字符流(一个字符占两个字节)设计的,主要用来处理字符或字符串
-
在所有的硬盘上保存文件或进行传输的时候都是以字节的方法进行的,包括图片也是按字节完成,而字符是只有在内存中才会形成的,所以使用字节的操作是最多的
-
-
什么是线程什么是进程(待补充)
- 进行就是一个应用,打开任务管理器,就有一个进程界面,里面运行的每个应用都是一个进程
- 线程:比如发QQ消息,传送文件,都有相应的线程处理。
-
线程的几种实现方式
- 实现方式
- 通过集成Thread类实现一个线程
- 通过实现Runable接口实现一个线程
- FutureTask
- 线程池
- 怎么启动
thread.start()启动线程使用start方法,而启动了以后执行的是run方法。 - 怎么区分线程?
在一个系统中有很多线程,每个线程都会打印日志,我想区分是哪个线程打印的怎么办?
thread.setName设置一个线程名称。
- 实现方式
-
- 线程状态:Thread.State枚举类 :NEW, RUNNABLE, BLOCKED, WAITING, TIMED_WAITING, terminated
- 线程生命周期:线程状态
- 线程都是:1、线程 操作 资源 2、高内聚低耦合
- 线程实战:https://mp.youkuaiyun.com/console/editor/html/104239329
-
http中get和post区别
- get请求提交的数据会在地址栏显示出来。post不会。
- 传输数据的大小不同。
- 安全性,post的安全性要比get的安全性高。

-
servlet是什么?

-
servlet生命周期

-
forward和redirect区别

5、redirect携带数据到页面,需要传到model中。forward放到request中就可以。 -
jsp的9个内置对象、四大作用域,以及作用
- 9个内置对象
- request用户端请求,此请求会包含来自GET/POST请求的参数。
- response网页传回用户端的回应
- pageContext网页的属性是在这里管理
- session与请求有关的会话期
- application 全域(正在执行的内容)
- out 用来传递回应的输出
- config 架构部件
- page 网页本身
- exception 异常
- 四大作用域
- pageContext
- request
- session
- application
- 传递值
- request
- session
- application
- cookie
- 9个内置对象
-
session和cookie区别



-
什么是springMVC

-
-
mysql的默认最大连接数
100 -
session共享
将session放到redis中。
学习地址:https://www.cnblogs.com/SimpleWu/p/10118674.html -
多态
运行时行为,xml中一个id,多个class,只有运行时决定使用哪一个。 -
从父到子,静态先行
静态代码块优于构造方法。
静态只加载一遍 -
Override
1、子类不能比父类跑出更大的异常
2、子类比父类修饰符相等或更大
3、public protected default private
-
HashMap
- 当key的hashcode()值不同时,数组横向添加,当key的hashcode()值相同时,则竖向添加。人称虾扯蛋。
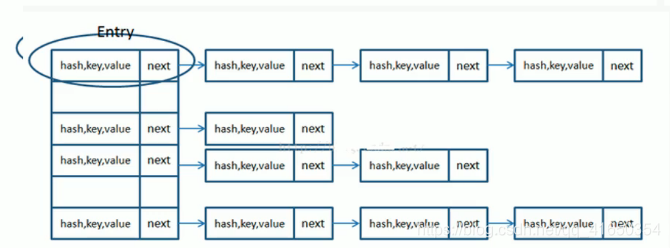

- 负载因子:0.75

- hashMap默认大小:16(1>>4) 2的四次方
- hashMap的扩容机制:当size>=16*0.75 扩容一倍
- hashMap底层是由数组+链表形式组成。
- map遍历方式
Map<String, Object> map = new HashMap<>(); map.put("key1",1); map.put("key2",2); //迭代器遍历 Iterator<Map.Entry<String, Object>> iterator1 = map.entrySet().iterator(); while (iterator1.hasNext()){ System.out.println("iterator1:"+iterator1.next()); } //第二种 for (Map.Entry<String, Object> entry : map.entrySet()){ System.out.println("key:"+entry.getKey()+";value:"+entry.getValue()); }
- 当key的hashcode()值不同时,数组横向添加,当key的hashcode()值相同时,则竖向添加。人称虾扯蛋。
-
HashSet底层使用的是HashMap

add的是hashmap的key,value new了一个object的实例对象。
-
ArrayList、LinkedList、Vector的区别。(待补充)
- 理解
- ArrayList底层
- 扩容机制
- 区别
-
类的加载顺序
static、代码块、构造方法、普通方法
static会在类初始化前先加载,当运行main方法时,先运行main方法中的static,在运行mian。 -
linux服务器故障排查
- top命令(q退出):
1、查看CPU
2、MEM(内存) 按数字1查看所有的cpu
3、ID(idle)空闲率, 越大越好,如果系统慢了,这个数贼大,那么绝对不是CPU的问题。
4、load average 系统负载,后面三个数代表1分钟、5分钟、15分钟负载率,三个相加除以3乘以100%,超过60%系统就有压力,超过80%系统快要蹦了。(使用命令uptime也可以查看) - uptime 系统负载
- free -m 查看内存使用情况
- df -h 磁盘空闲使用率
- vmstat -n 2 3 cpu 包含但不限于 r 正在运行的 b阻塞 us+sy不能大于60% id空闲
- iostat -xdk 2 3 磁盘IO(跟读写有关) 主要看%util,如果长时间过大,需要sql调优。
- top命令(q退出):
-
说说二叉树。
https://mp.youkuaiyun.com/postedit/104252201 -
lambda表达式与函数式编程
https://blog.youkuaiyun.com/qq_41650354/article/details/104261676 - jvm
https://blog.youkuaiyun.com/qq_41650354/article/details/104278846 - i++和++i
- i = i++;i永远不变 (只有前后变量一致,没有任何计算方式只有单纯的i=i++才值不变)
- ++在前先计算,++在后计算。
- 代码
int i =1; i = i++;//前后变量一样,值永远不变。 int j = i++;//i赋值前是1 赋值之后是2。 System.out.println(i);//2 System.out.println(j);//1 int k = i + ++i * i++;//从左往右计算, ++在前先计算 ++ 在后不计算 System.out.println(k);//11 i = i++; System.out.println(i);//11//前后变量一样,值永远不变。 //例子二 int i =1; i = i++ * i++;// i= 1*2 涉及运算符号(加减乘除) i++ 加1 System.out.println(i);//2
- 单例模式
https://blog.youkuaiyun.com/qq_41650354/article/details/104103988 - 类初始化过程
- main方法
- 一个子类要初始化需要先初始化父类
- 静态变量 = 静态代码块 > 匿名内部类 > 构造方法
- 代码
class per{ public static void aa(){ System.out.println("静态方法+++"); } public static int bb(){ System.out.println("静态变量+++"); return 6; } public void cc(){ System.out.println("cc方法+++"); } { System.out.println("匿名内部类+++"); } static { System.out.println("静态代码块+++"); } per(){ System.out.println("构造方法"); } private static int i = bb(); } public class Client { public static void main(String[] args) { System.out.println("7777"); per per= new per(); System.out.println("6666"); } } //结果 7777 静态代码块+++ 静态变量+++ 匿名内部类+++ 构造方法 6666
- bean的作用域
- 可以通过scopr属性来指定bean的作用域
- singleton :默认值,当IOC容器一创建就会创建bean的实例,而且是单例的,每次得到的都是同一个对象
- prototype:原型的,当IOC容器一创建不在实例化该Bean,每次调用getBean方法时实例化该bean,而且每次的得到的不同对象。
- request :每次请求实例化一个bean
- session:再一次会话中共享一个bean
- 请检单介绍Spring支持的常用数据库事务传播属性和事务隔离级别。
- 设置事务

- 事务的传播属性有七种,常用2种。
- 事物的得传播属性:一个方法运行在一个开启了事务的方法中时,当前方法时使用原来的事务还是开启一个新的事务。
- Propagation.REQUIRED 默认值,原来的事务
- Propagation.REQUIRED_NEW 将原来的事务挂起,开启一个新的事务
- 事务的隔离级别
- READ uncommitted 读未提交
- READ committed 读已提交 :一个方法内,查询A的名字“张三” 改名字“李四” 继续查询A的名字是李四
- repeatable READ可重复读(mysql默认级别): 一个方法内,查询A的名字“张三” 改名字“李四” 继续查询A的名字仍是张三
- 串行化 serializable
- 数据库事务并发问题
- 脏读:修改未提交,读取到了
- 不可重复读: 一个事务内,查询A的名字“张三” 改名字“李四” 继续查询A的名字仍是张三
- 幻读:查询A的名字“张三” 改名字“李四” 继续查询A的名字是李四
- 设置事务
-
什么是事务?事务的四大特性。
去仓库取材料A,仓库的材料A数量减少,我手里的材料A增加,这就是一个事务。也就是在一个方法内完成的操作可以称为一个事务。- 原子性:事务内操作不可分割。
- 一致性:要么都成功、要么都是失败。
- 隔离性:一个事务的执行不能被其他事务干扰。
- 持久性:指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
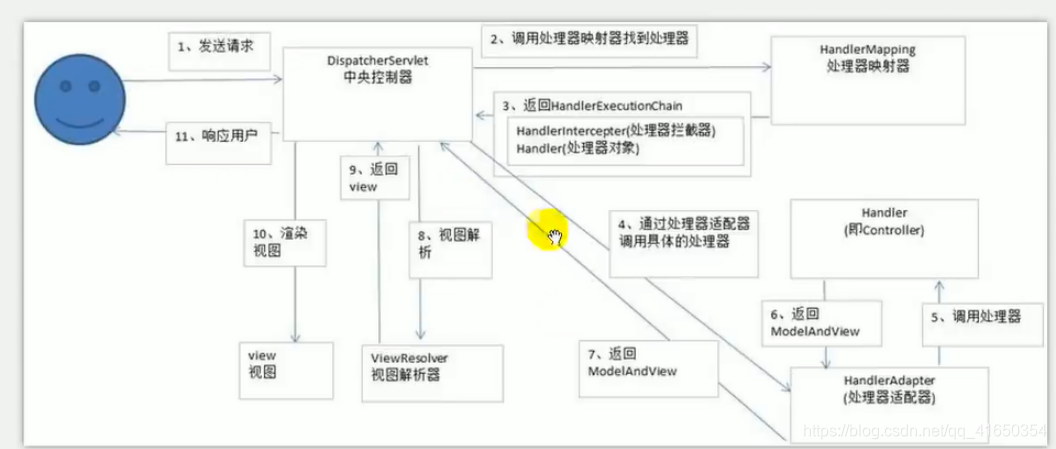
- springMVC工作流程

















03-23
 7008
7008
7008
08-29
07-28
3928
3928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









