







一、准备子文件格式的数据集
dataset/
├── train/
│ ├── class_1/
│ ├── class_2/
│ └── class_3/
├── val/
│ ├── class_1/
│ ├── class_2/
│ └── class_3/
└── test/
├── class_1/
├── class_2/
└── class_3/
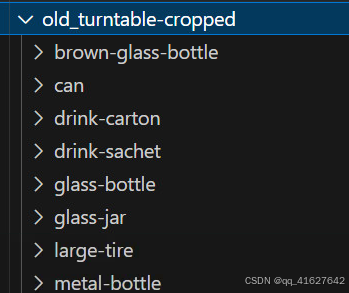
1、对图像进行分类,按照类别放入各自的文件夹中,如下图所示
2、数据集划分
# 深度学历 csdn:李大脑袋741
import os
import shutil
import random
import pandas as pd
# 指定数据集路径
dataset_path = 'dataset/path'
dataset_name = dataset_path.split('_')[0]
print('数据集:', dataset_name)
# 获取类别文件夹
classes = os.listdir(dataset_path)
if not classes:
print("错误:数据集为空或路径错误。")
exit()
# 创建 train、val、test 文件夹
for folder in ['train', 'val', 'test']:
folder_path = os.path.join(dataset_path, folder)
if not os.path.exists(folder_path):
os.mkdir(folder_path)
# 在 train、val、test 文件夹中为每个类别创建子文件夹
for defect in classes:
for folder in ['train', 'val', 'test']:
defect_folder_path = os.path.join(dataset_path, folder, defect)
os.makedirs(defect_folder_path, exist_ok=True)
# 设置验证集和测试集比例
val_frac = 0.3
test_frac = 0.1
random.seed(123) # 固定随机种子,确保结果一致
# 初始化统计数据框
df = pd.DataFrame(columns=['class', 'trainset', 'testset', 'valset'])
# 输出数据集统计
print('{:^18} {:^18} {:^18} {:^18}'.format('类别', '训练集数据个数', '测试集数据个数', '验证集数据个数'))
# 遍历每个类别
for defect in classes:
old_dir = os.path.join(dataset_path, defect)
images_filename = os.listdir(old_dir)
random.shuffle(images_filename)
# 计算各集数据个数
total_count = len(images_filename)
testset_num = int(total_count * test_frac)
valset_num = int(total_count * val_frac)
trainset_num = total_count - testset_num - valset_num
# 分配数据集
testset_images = images_filename[:testset_num]
valset_images = images_filename[testset_num:testset_num + valset_num]
trainset_images = images_filename[testset_num + valset_num:]
# 移动图像至相应文件夹
for image, folder in zip([testset_images, valset_images, trainset_images], ['test', 'val', 'train']):
for img in image:
shutil.move(
os.path.join(dataset_path, defect, img),
os.path.join(dataset_path, folder, defect, img)
)
# 删除旧文件夹
if not os.listdir(old_dir):
shutil.rmtree(old_dir)
# 输出各类别的统计数据
print(f"{defect:^18} {trainset_num:^18} {testset_num:^18} {valset_num:^18}")
# 保存至数据框
df = pd.concat([df, pd.DataFrame({
'class': [defect],
'trainset': [trainset_num],
'testset': [testset_num],
'valset': [valset_num]
})], ignore_index=True)
# 重命名数据集文件夹
new_dataset_path = dataset_name + 'new'
if not os.path.exists(new_dataset_path):
shutil.move(dataset_path, new_dataset_path)
# 保存数据统计信息至 csv 文件
df['total'] = df['trainset'] + df['testset'] + df['valset']
df.to_csv('数据量统计.csv', index=False)
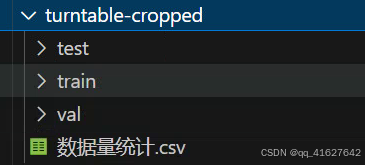
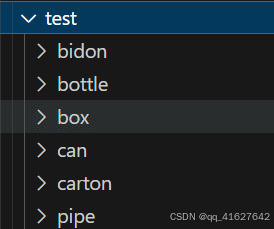
二、设置配置文件
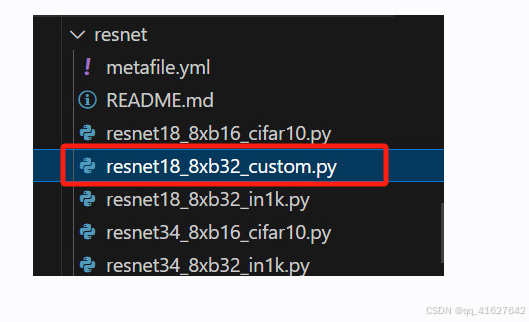
在本教程中,我们使用 configs/mae/mae_vit-base-p16_8xb512-amp-coslr-300e_in1k.py
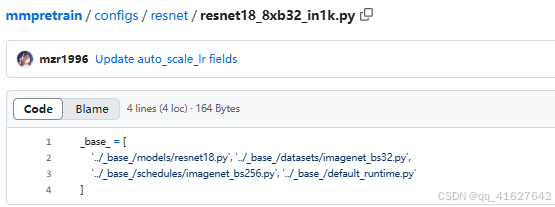
configs/resnet/resnet18_8xb32_in1k.py作为一个示例进行介绍。 首先在同一文件夹下复制一份配置文件,并将其重命名为 resnet18_8xb32_custom.py。
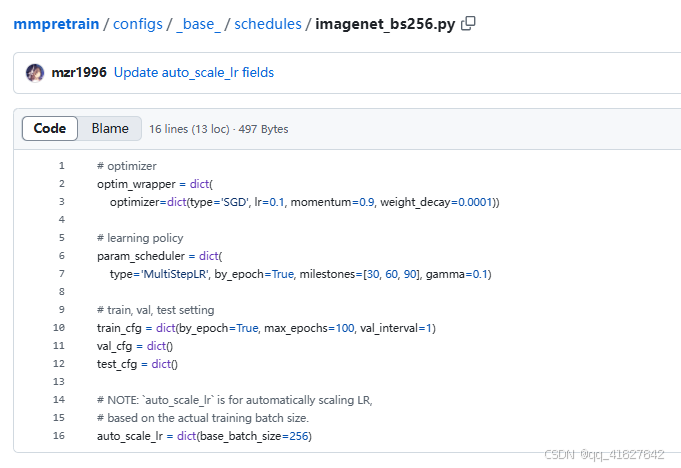
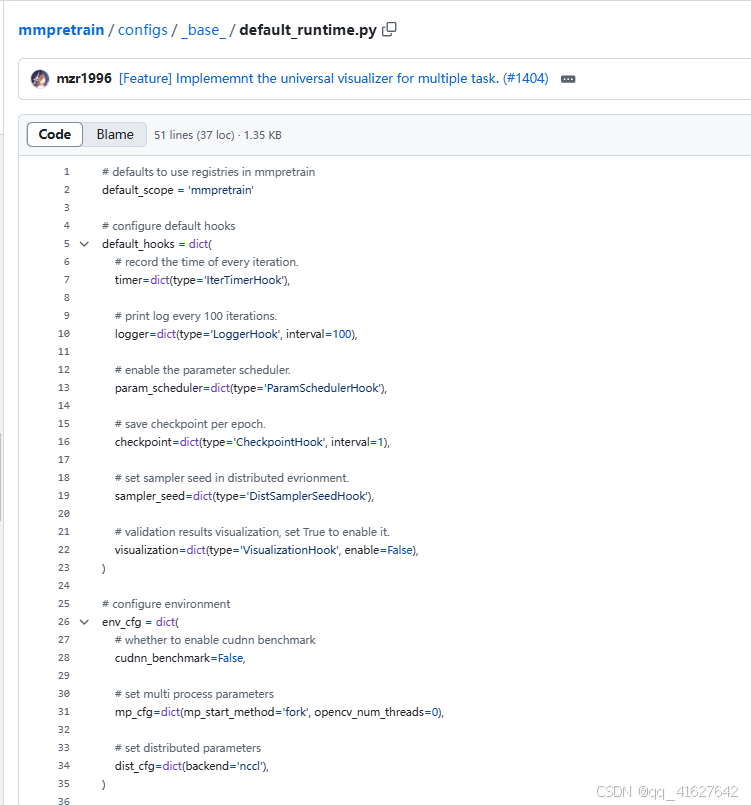
分别按路径打开这四个文件进行设置,它们分别是模型配置文件、数据集配置文件、优化器文件路径、日志配置路径

三:修改数据集设置
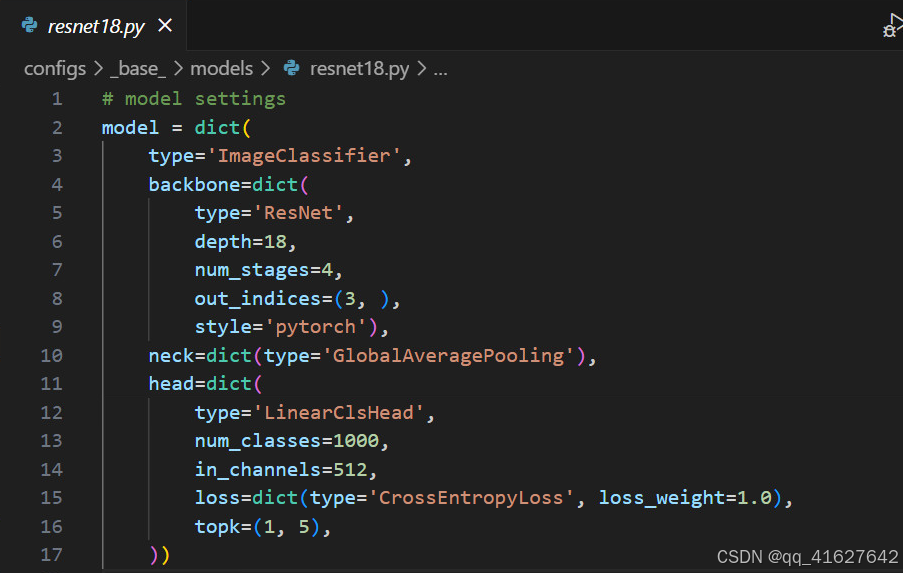
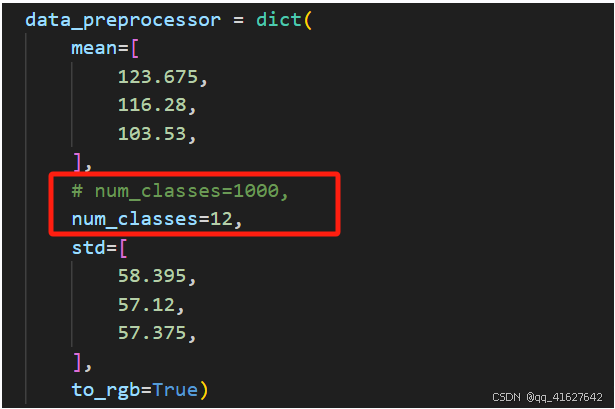
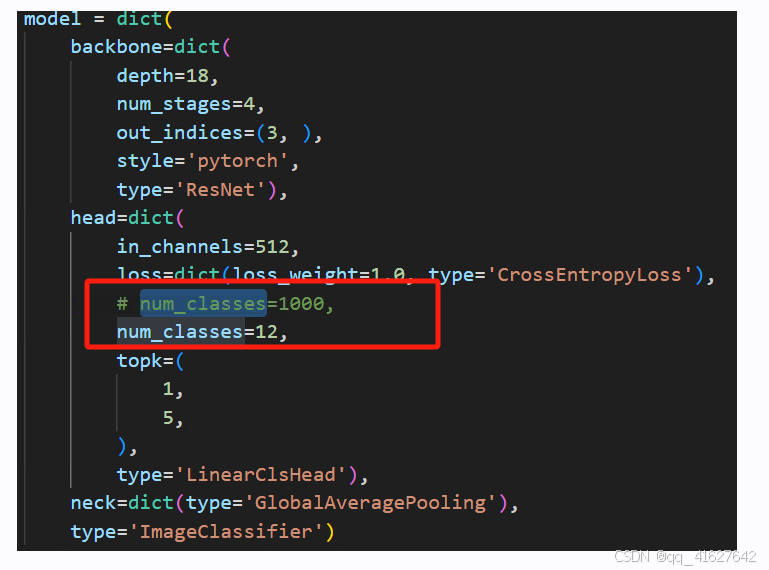
1.首先必须对所有的num_classess进行修改
2.必须对data_root,数据集路径进行修改
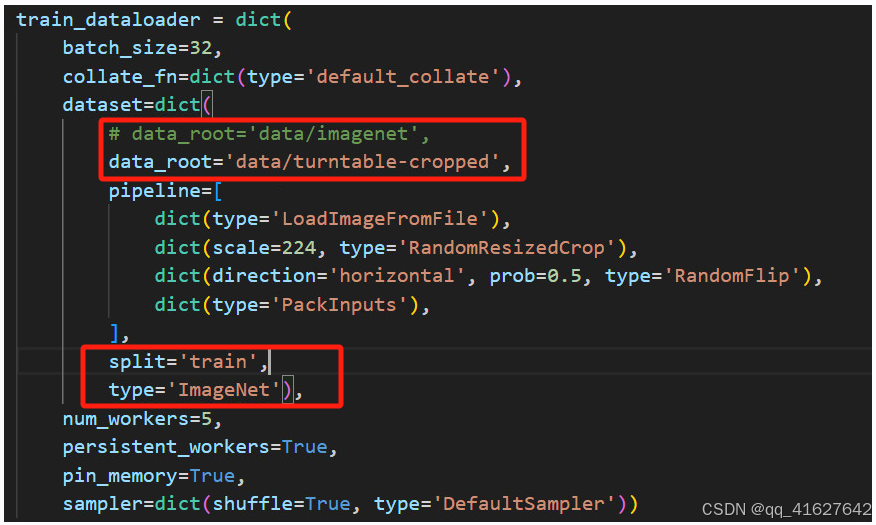
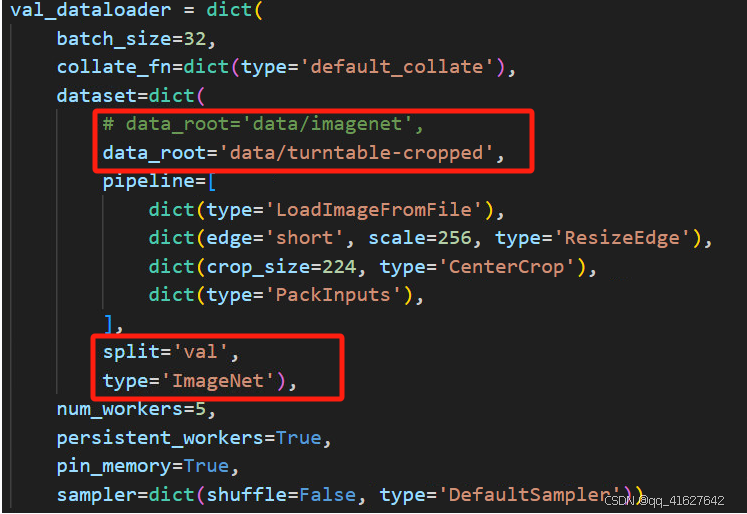
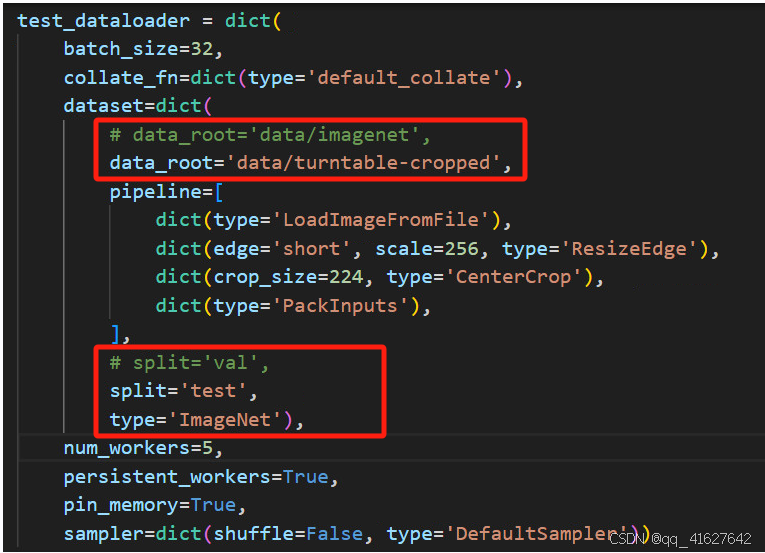
目前使用
3.若数据集的分类少于5类还需要对topk进行修改,将5注释掉
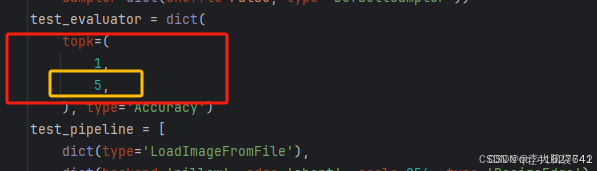
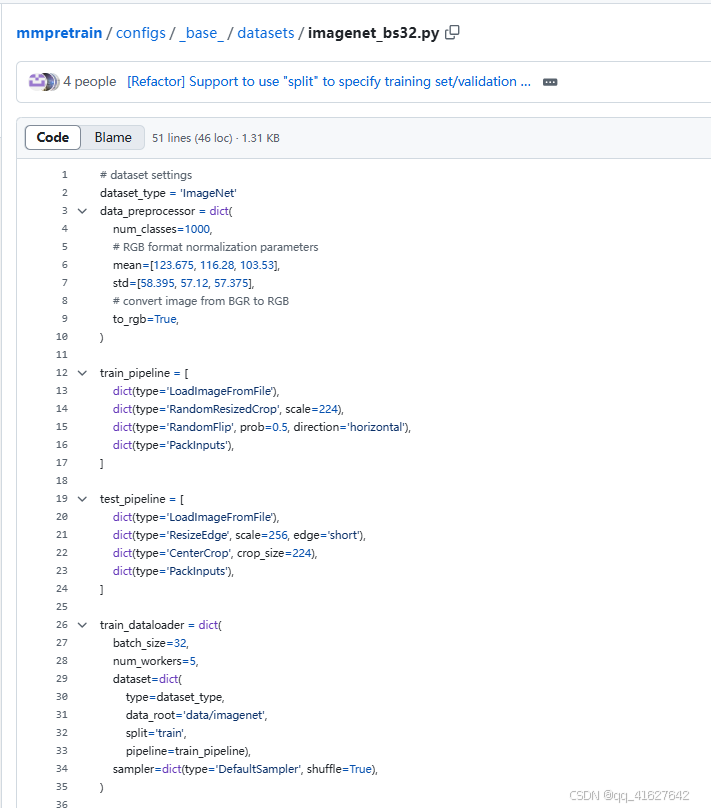
4.设置数据集分类
按照上述方法划分数据集后,即可直接修改然后使用
打开imagenet.py,在此处加入此段代码将其换成自己的分类即可
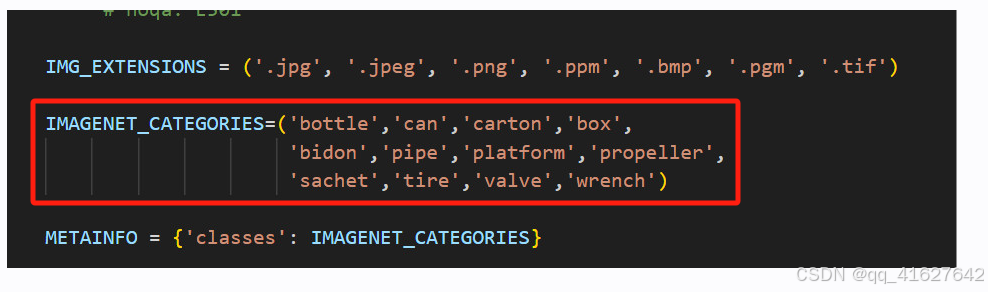
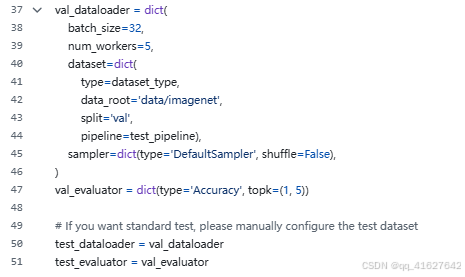
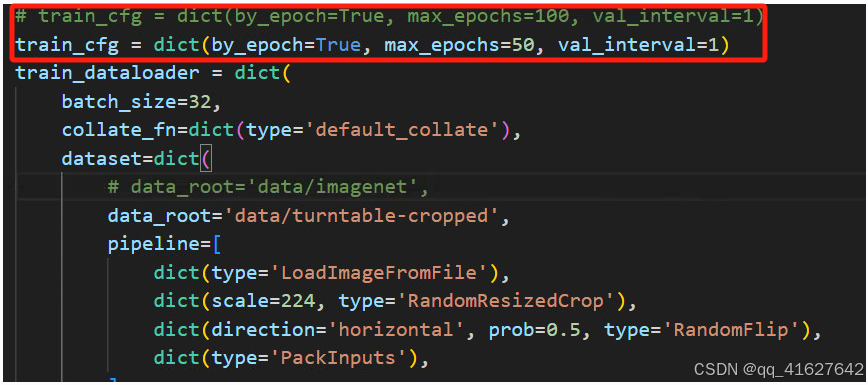
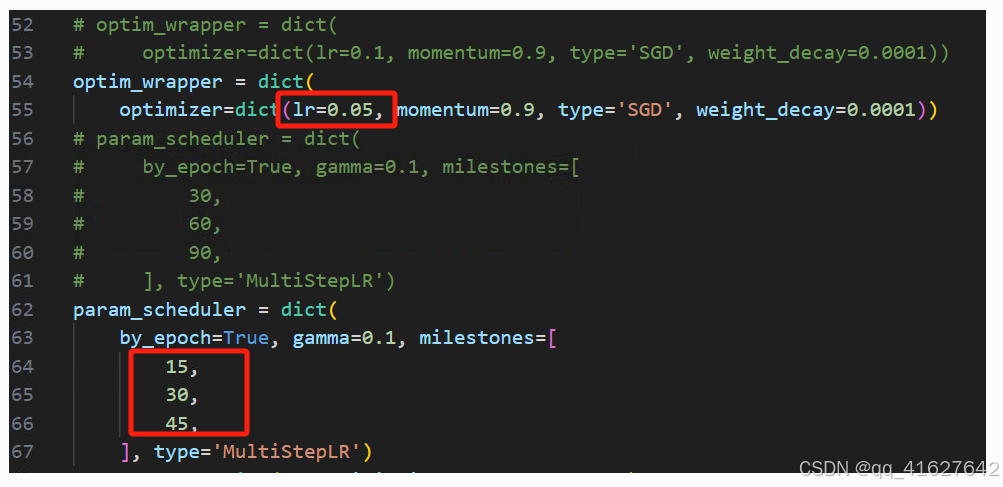
5. 其他
训练多少轮;多少轮保存权重、日志;学习步长等根据需要修改
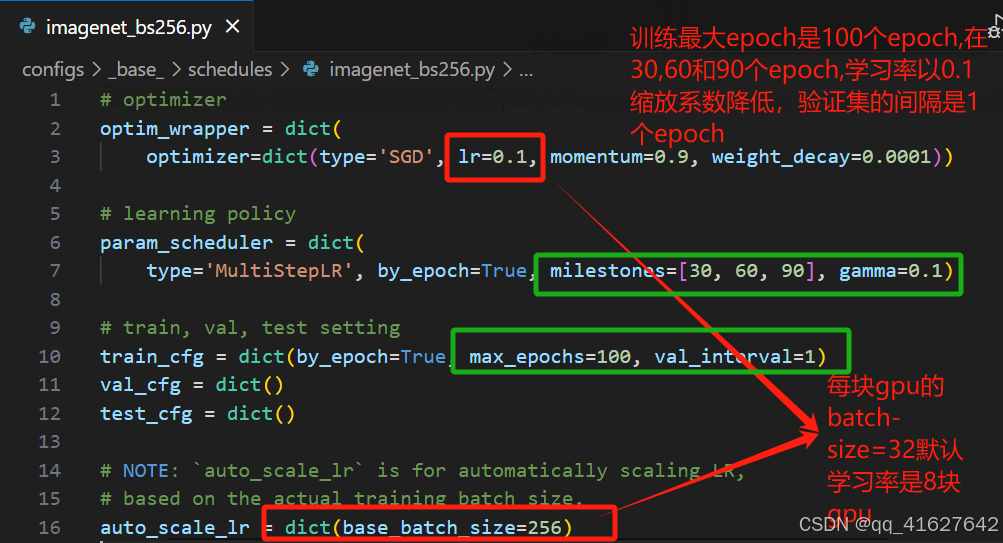
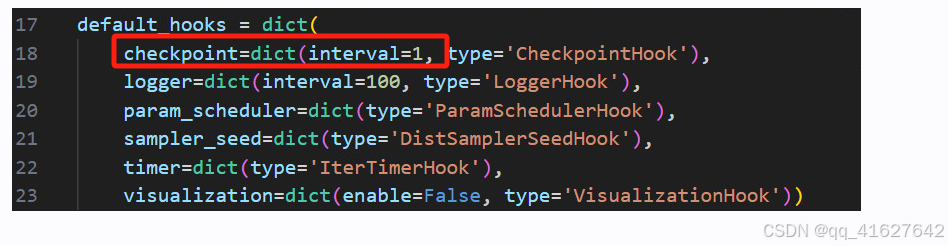
修改后
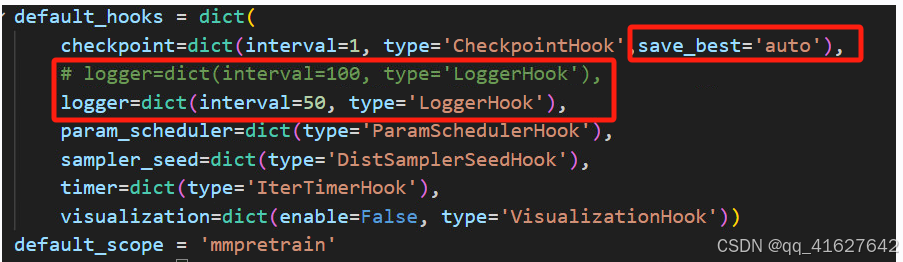
四 开始进行训练
1、单机单卡训练
CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]


















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









