









这里使用两种方式做数据爬取

这是网页源码形式
1.beautifulsoup的html.parse解码
import requests
from bs4 import BeautifulSoup
import csv
def get_city_dict():
"""获取城市和对应链接字典 第一步"""
url = 'http://www.air-level.com/'
r = requests.get(url, timeout=30)
soup = BeautifulSoup(r.text, 'html.parser')
# 获取城市div
city_div = soup.find_all('div', class_='citynames')[1:]
# 获取城市标签链接
city_list = []
for each in city_div:
city_list.append(each.find_all('a'))
# 获取名字:链接列表
name_link = {}
for each in city_list:
for city in each:
if city.text not in ['克孜勒苏州', '莱芜', '那曲', '思茅', '襄樊', '伊犁哈萨克']:
name_link[city.text] = city.get('href')
return name_link
def get_city_information(city_url):
"""得到每个城市的信息 第三步"""
response = requests.get('http://www.air-level.com' + city_url, timeout=30)
soup = BeautifulSoup(response.text, 'html.parser')
information_table = soup.find_all('table')
# 城市地区的数据
city_data = information_table[0].find_all('tr')[1:]
all_data = []
for each in city_data:
data_list = each.find_all('td')
data = list()
for i in data_list:
data.append(i.text)
all_data.append(data)
return all_data
def get_information(city_link_dict):
"""爬取数据 第二步"""
print('总城市数为', len(city_link_dict))
information_list = []
for each in city_link_dict.keys():
ciy_url = city_link_dict[each]
# 返回城市数据
print('开始爬取' + each + '数据')
city_information = get_city_information(ciy_url)
information_list.extend(city_information)
print(each + '数据爬取完成')
print('全部数据爬取完成.......................')
return information_list
def write_information(information):
"""写入csv文件"""
headers = ['监测站', 'AQI', '空气质量等级', 'PM2.5', 'PM10', '首要污染物']
print('开始写入数据')
with open(r'city_information.csv', 'w', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(information)
print('数据写入完成')
if __name__ == '__main__':
# 城市链接
city_link = get_city_dict()
# 数据
data = get_information(city_link)
# 写数据
write_information(data)
2.xpath解析器
import requests
from lxml.html import etree
import csv
def get_city_link():
"""第一步:得到城市和其链接"""
url = 'http://www.air-level.com/'
response = requests.get(url, timeout=30)
html = etree.HTML(response.text)
all_city = html.xpath("//div[@class='citynames']/a/text()")[7:]
all_link = html.xpath("//div[@class='citynames']/a/@href")[7:]
city_link_dict = {all_city[i]: all_link[i] for i in range(len(all_link))}
return city_link_dict
def download_information():
"""第二步:下载数据"""
information_dict = get_city_link()
print("城市总数为:", len(information_dict))
url = 'http://www.air-level.com'
download_information_dict = {}
for each in information_dict.keys():
print('开始下载', each + '数据')
if each not in ['克孜勒苏州', '莱芜', '那曲', '思茅', '襄樊', '伊犁哈萨克', '瓦房店']:
each_url = url + information_dict[each]
response = requests.get(each_url, timeout=30)
html = etree.HTML(response.text)
city_name = html.xpath("//table[@class='table text-center']/tr/td[1]/text()")
information_table = html.xpath("//table[@class='table text-center']/tr/td/text()")
# 清洗数据
name = ''
data = []
j = 0
air_quality = html.xpath("//table[@class='table text-center']/tr/td/span/text()")
for i in range(len(information_table)):
if i != len(information_table) - 1:
if information_table[i] in city_name:
if len(data):
data.insert(1, air_quality[j])
download_information_dict[name] = data
j += 1
data = []
name = information_table[i]
else:
name = information_table[i]
else:
data.append(information_table[i])
else:
data.append(information_table[-1])
data.insert(1, air_quality[j])
download_information_dict[name] = data
print(each, '数据下载完成')
print('所有城市天气数据下载完成..................')
return download_information_dict
def write_information():
"""写入csv文件"""
headers = ['监测站', 'AQI', '空气质量等级', 'PM2.5', 'PM10', '首要污染物']
all_data = download_information()
data = []
city_data = []
for each in all_data.keys():
city_data.append(each)
city_data.extend(all_data[each])
data.append(city_data)
city_data = []
print('开始写入数据')
with open(r'city_information.csv', 'w', newline='', encoding='utf-8') as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(data)
print('数据写入完成')
if __name__ == '__main__':
write_information()3.注意
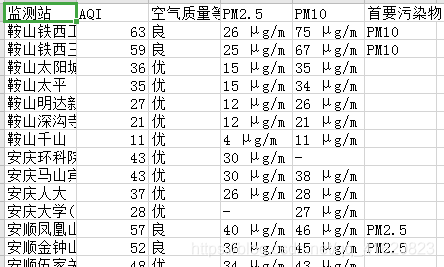
剔除一些城市主要是由于哪些城市的链接访问不了,会产生超时。还要就是解析网页的etree库在python3中被更新到了lxml.html.etree中。以下是效果图。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









