







16、kafka是如何做到高效读写
1)Kafka 本身是分布式集群,可以采用分区技术,并行度高
2)读数据采用稀疏索引,可以快速定位要消费的数据。(mysql中索引多了之后,写入速度就慢了)
3)顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端, 为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
4)页缓存 + 零拷贝技术
零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用 走应用层,传输效率高
PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入 PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用
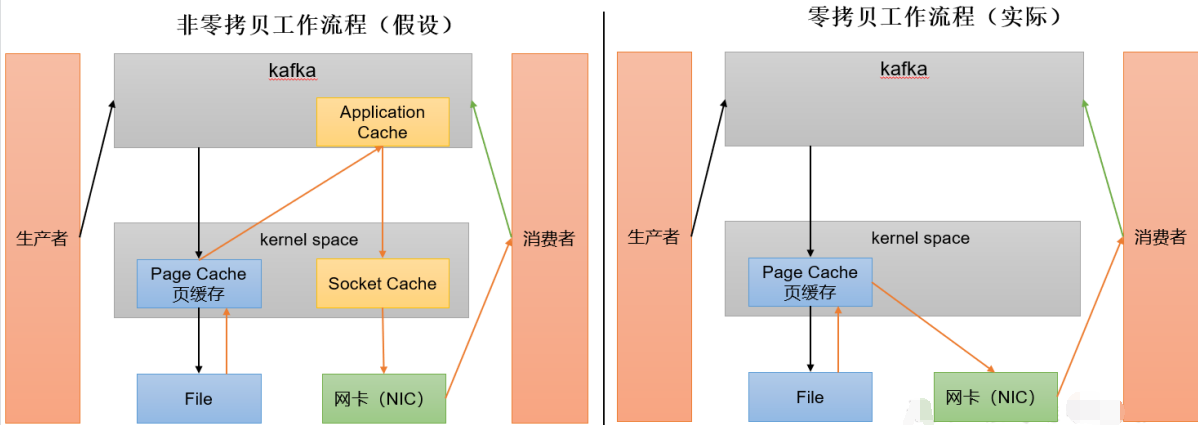
生产者将数据发送给kafka,kafka将数据交给Linux内核,Linux内核将数据放入自身操作系统的页缓存中,然后到一定值写入磁盘,假如消费者过来消费,直接从页缓存中,通过网卡发送给消费者,根本就没有去kafka的业务系统中获取数据,所以速度比较快。
跟这个问题非常像:mysql读取数据的速度为什么这么快!--buffer pool
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









