






Architecture
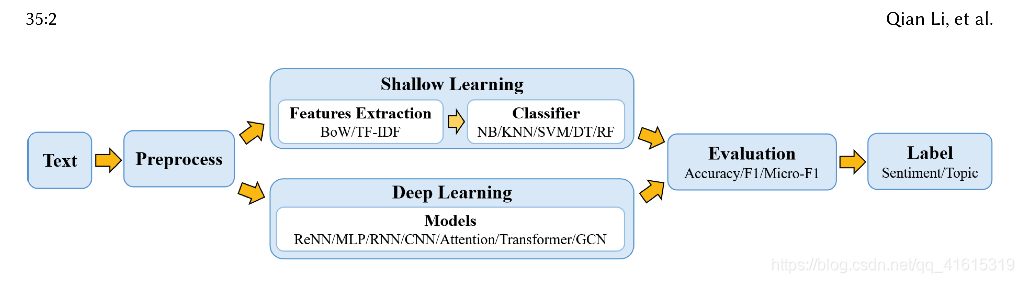
Disadvantage of Shallow Learning
- need feature engineering
- disregard the natural sequential structure / contexted information, hard to learn semantic information
Advantage of Deep Learning
- avoid designing rules and features by human
- semantically meaning
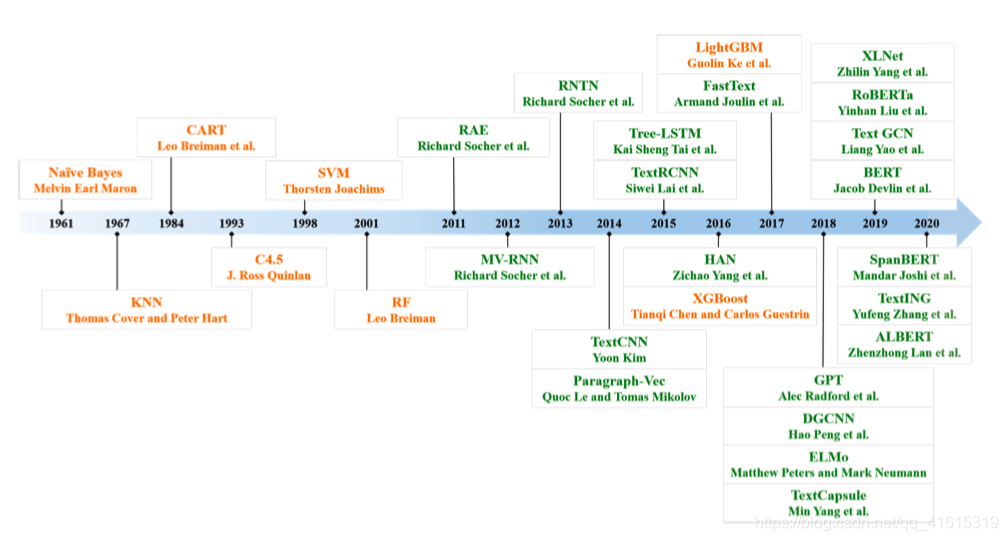
Text Classification Methods:
extracting features from row text data and predicting the categories of text data
Shallow Learning Methods
-
preprocess data: word segmentation, data cleaning, data statistics
-
text representation: 使text形成计算机更易计算/理解的方式:Bag-of-words (BOW), N-gram, term frequency-inverse document frequency (TF-IDF), word2vec and GloVe
- BOW: representing each text with a dictionary-sized vector
- 缺点:cannot properly capture more complex linguistic phenomena in sentiment analysis
- “white blood cells destroying an infection” and “an infection destroying white blood cells” have the same bag-of-words representation,但前者positive reaction后者negative reaction
- N-gram: considers the information of adjacent words and builds a dictionary by considering the adjacent words
- TF-IDF: word frequency and inverses the document frequency to model the text
- word2vec: employs local context information to obtain word vectors
- GloVe: with both the local context and global statistical features – trains on the nonzero elements in a word-word co-occurrence matrix
- BOW: representing each text with a dictionary-sized vector
-
feed the text representation to classifier
- SVM
- Naive Bayes
- KNN
- Decision Tree
Deep Learning Methods
Recursive Neural Network Based Methods
-
Recursive Neural Network [https://zybuluo.com/hanbingtao/note/626300
- motivation
- RNN循环神经网络是将长度不定的输入分割为长度相等的小块输入,如一句话拆分为多个单词,一次输入一个词来处理任意长度的句子。但单纯的序列是不够的,如考虑一句话在不同断句下可能有不同意思,为了表明这些不一样的意思,可以构建树结构/图结构去储存信息。此时需要用到的是递归神经网络去讲一个树/图结构编码为相应向量再去计算向量远近
- forward-propagation
- 子节点编码产生父节点,父节点维度与子节点相同。
- 子节点与父节点之间的神经元为全连接结构。
- backward-propagation:BPTS
- 父节点—>子节点
- motivation
-
Recursive Autoencoder (RAE)
-
Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions
-
Contribution
- Instead of using a BOW, hierarchical structure and uses compositional semantics to understand sentiment.
- 有标签和无标签的数据都能使用
- 不限于positive/negative sentiment, predict a multidimensional distribution over several complex, interconnected sentiments.
-
Neural Word Representation: Word Embedding
- 每个word vector:
n
×
1
n\times1
n×1,|V|个vocabulary,embedding matrix L:
n
×
∣
V
∣
n\times|V|
n×∣V∣
- 方法一:每个word vector从mean为0的Gaussian Distribution中随机采样得到,然后逐步调整去拟合label的distribution
- 方法二:用jointly learn an embedding of words into a vector space and use these vectors to predict how likely a word occurs given its context的model,采用gradient ascent的方式学习从co-occurrence学习syntactic and semantic information
- 每个word vector:
n
×
1
n\times1
n×1,|V|个vocabulary,embedding matrix L:
n
×
∣
V
∣
n\times|V|
n×∣V∣
-
如何对于给定的由m个word组成的句子选取相应的embedding
- 每个word有自己的index k,k标记word所在的位置,考虑one-hot向量 b k b_k bk=[0,0,…1,0,…,0]
- 选取embedding可以看做是矩阵乘法: L b k Lb_k Lbk, n × ∣ V ∣ × ∣ V ∣ × 1 = n × 1 n\times|V|\times|V|\times1 = n\times1 n×∣V∣×∣V∣×1=n×1
- 之前用的binary number representation,现在是用vector组成list,为了方便continuous sigmoid unit。
-
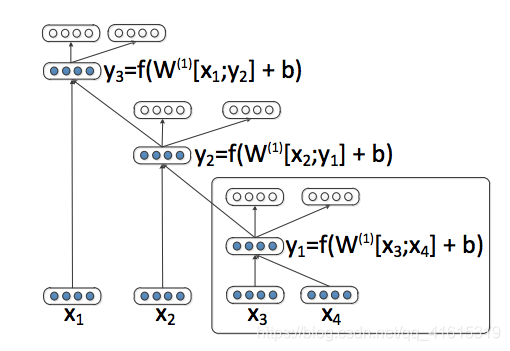
如何得到reduced dimensional vector representation
-
传统方法
- 父节点由两个子节点得到,以 x 3 , x 4 x_3, x_4 x3,x4到 y 1 y_1 y1为例
- y 1 = a c t i v a t e _ f u n c t i o n ( W 1 [ x 3 , x 4 ] + b ) y_1 = activate\_function(W^1[x_3,x_4]+b) y1=activate_function(W1[x3,x4]+b)。其中, [ x 3 , x 4 ] [x_3,x_4] [x3,x4]表示两个vector的cat; W 1 W^1 W1为相应系数矩阵, n × 2 n n\times2n n×2n;b为bias,激活函数通常为tahn
- loss来自于用得到的 y 1 y_1 y1重构 [ x 3 ^ , x 4 ^ ] [\hat{x_3},\hat{x_4}] [x3^,x4^],用重构的与原来的算Euclidean Distance。
-
本文方法: unsupervised
-
assume sentence有m个word, [ x 1 , x 2 , . . . , x m ] [x_1,x_2,...,x_m] [x1,x2,...,xm],遍历所有相邻pair [ x i , x i + 1 ] [x_i,x_{i+1}] [xi,xi+1],储存reconstruction error,取最小error的pair construct parent p p p,替换two children为parent p p p直至全部替换。e.g. [ x 1 , x 2 , x 3 , x 4 ] − − − > [ x 1 , x 2 , p ( 3 , 4 ) ] [x_1,x_2,x_3,x_4]--->[x_1,x_2,p_{(3,4)}] [x1,x2,x3,x4]−−−>[x1,x2,p(3,4)]
-
这里reconstruction error的问题,已经合并过多次的父节点通常比合并次数少/未合并的节点具有更大的weight。所以这里添加相应系数
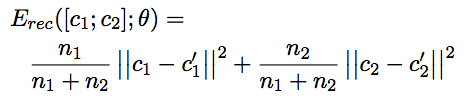
-
length normalization: y 1 = y 1 ÷ ∣ ∣ y 1 ∣ ∣ y_1 = y_1\div||y_1|| y1=y1÷∣∣y1∣∣
-
-
本文方法: semi-supervised
- motivation:extend RAE to predict a sentence/phrase level distribution
- RAE天然的具有了捕捉phrase feature的能力,因为parent node也有自己的distributed vector,而上层的parent可以被看做phrase feature
- 加cross-entropy error
- predict parent label的概率 d K d_K dK, s o f t m a x ( W l a b e l p ) softmax(W^{label}p) softmax(Wlabelp), 一共K个label, ∑ d k = 1 \sum d_k = 1 ∑dk=1, d k d_k dk可认为是给定两个子节点时父节点为K类的conditional probability。
- 则cross-entropy为
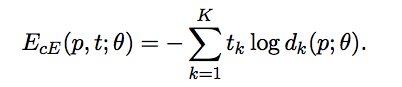
- 此时损失函数为normalize+加权后的reconstruction error 和 cross-entropy error: α E r e c o n s t r u c t i o n − e r r o r + ( 1 − α ) E c r o s s − e n t r o p y \alpha E_{reconstruction-error}+(1-\alpha)E_{cross-entropy} αEreconstruction−error+(1−α)Ecross−entropy
-
-
-
MV-RNN
-
RNTN
-
DeepReNN
Multilayer Perceptron Based Methods
- Paragraph-Vec: Distributed Representations of Sentences and Documents
- 概要:认为BOW存在问题-未关注word order+未关注semantics,所以提出Paragraph Vector to learn fix length feature representations from variable length,并在一些text classification 和 sentiment analysis task
Datasets
-
Sentiment Analysis (SA): binary class and multi-class
-
News Classification (NC): recognizing news topics and recommending related news according to user interest.
-
Question Answering (QA)
-
- Extractive QA: multiple candidate answers for each question to choose which one is the right answer
- Generative QA: 自己生成答案,通常不被认为是text classification
-
Natural Language Inference (NLI): identify whether the meaning of one text can be deduced from another
Evaluation Metrics
-
Single-label: divides the text into one of the most likely categories
-
- Acc + Error Rate
- Precision + Recall + F1: for unbalanced test set
- Exact Match (EM): for QA measuring the prediction that matches all the ground-truth answers precisely
- Mean Reciprocal Rank (MRR): for QA and Information Retrieval tasks
- Hamming-loss (HL): assesses the score of misclassified instance-label pairs where a related label is omitted or an unrelated is predicted
-
Multi-label
-
- Micro-F1
- Macro-F1
- Precision at Top K (P@K)


















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









