







request的查询其实也是大同小异的,换汤不还药
其他部分参考
https://blog.youkuaiyun.com/qq_41612765/article/details/101688223
第一步
我们还是要获取得到的url(如何构建url已经在前面的文章有描述)并且通过request发送请求拿到页面数据,
但是在这个过程中,jd方面做了一些小处理使得通过request直接发送的请求,返回的商品列表不会如我们所愿的索取到一个正常的情况,所以我们需要在请求体的身上加一点东西来简单的模拟浏览器发送的数据,
怎么拿到自己浏览器信息我们在这里拿一个csdn的网站举栗子:
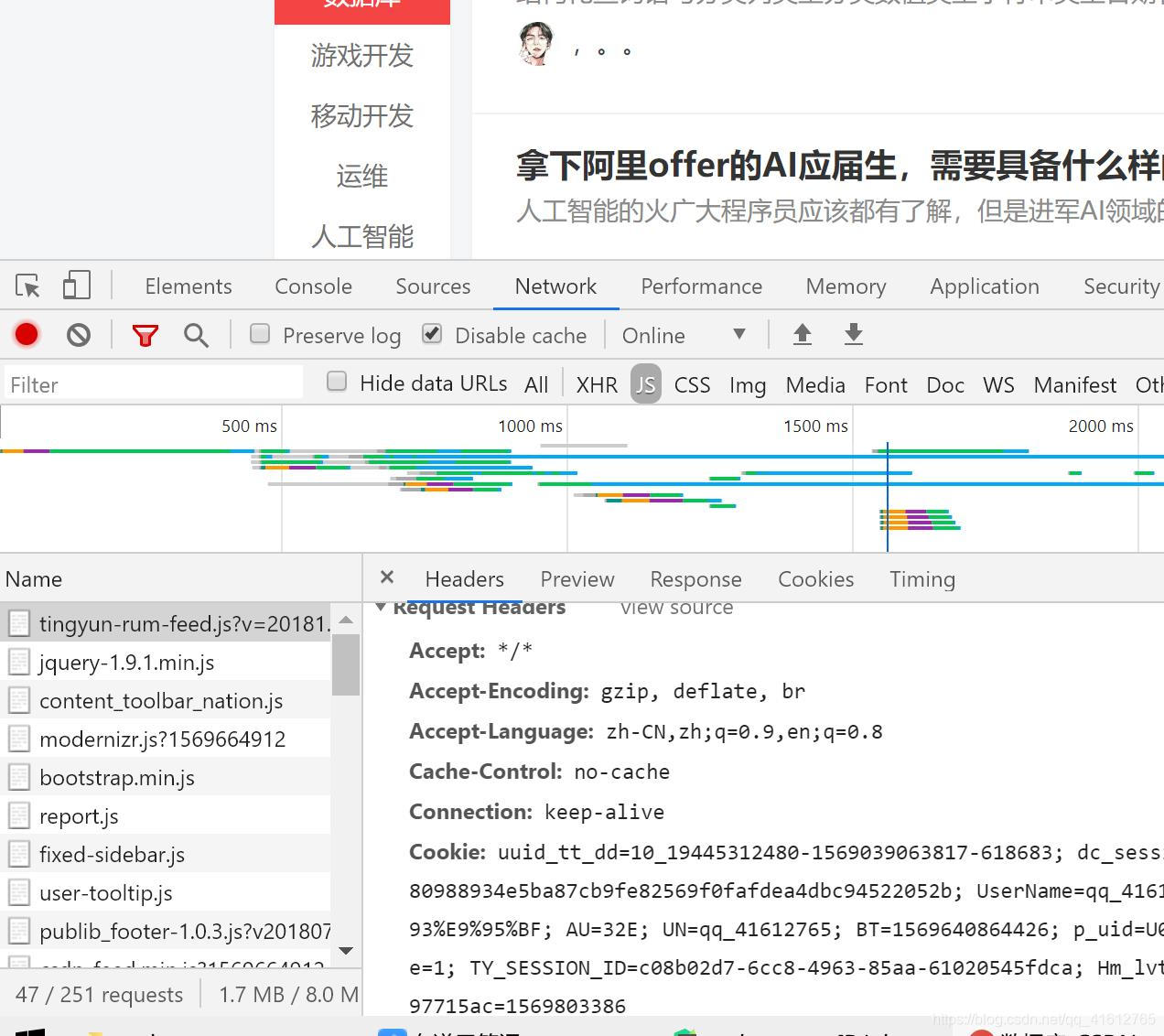
随便点开页面,点出控制台,然后选择Network,点击最前面的信息找到headers,往下翻里面的User-Agent就是我们这一次用到的信息。
接下来当我们成功拿到数据的时候,后面的操作就和我之前写的那一篇操作一摸一样了
#构建请求的header
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
respones=requests.get(url,headers=headers)
html=respones.text
soup=BeautifulSoup(html_sourcode,'lxml')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









