







 本文全面介绍了ElasticSearch,一种基于Lucene的高扩展分布式搜索服务器,探讨了其与Solr的区别,详细讲解了安装配置过程,包括环境要求、配置文件详解及启动步骤。
本文全面介绍了ElasticSearch,一种基于Lucene的高扩展分布式搜索服务器,探讨了其与Solr的区别,详细讲解了安装配置过程,包括环境要求、配置文件详解及启动步骤。
ElasticSearch介绍

总结:
1、elasticsearch是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
2、elasticsearch隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
突出优点:
1.扩展性好,可部署上百台服务器集群,处理PB级数据。
2.近实时的去索引数据、搜索数据。
es和solr选择哪个?
1.如果你公司现在用的solr可以满足需求就不要换了。
2.如果你公司准备进行全文检索项目的开发,建议优先考虑elasticsearch,因为像Github这样大规模的搜索都在用它。
ElasticSearch安装
安装配置:
1、新版本要求至少jdk1.8以上。
2、支持tar、zip、rpm等多种安装方式。
在windows下开发建议使用ZIP安装方式。
3、支持docker方式安装
详细参见:https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
下载ES: Elasticsearch 6.2.1
https://www.elastic.co/downloads/past-releases
或者可以使用我分享的安装包:
链接:https://pan.baidu.com/s/168k0dxfI6GJlNx5AEvfSjg&shfl=sharepset
提取码:i633
bin:脚本目录,包括:启动、停止等可执行脚本
config:配置文件目录
data:索引目录,存放索引文件的地方
logs:日志目录
modules:模块目录,包括了es的功能模块
plugins :插件目录,es支持插件机制
配置文件
三个配置文件:elasticsearch.yml : 用于配置Elasticsearch运行参数 jvm.options : 用于配置Elasticsearch JVM设置 log4j2.properties: 用于配置Elasticsearch日志
elasticsearch.yml
配置格式是YAML,可以采用如下两种方式:
方式1:层次方式
path: data: /var/lib/elasticsearch logs: /var/log/elasticsearch
方式2:属性方式
path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch
本项目采用方式2,例子如下:
注意path.data和path.logs路径配置正确。
cluster.name: qianfeng
node.name: qf_node_1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
#discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: false
node.max_local_storage_nodes: 1
path.data: D:\ElasticSearch\elasticsearch-6.2.1\data
path.logs: D:\ElasticSearch\elasticsearch-6.2.1\logs
http.cors.enabled: true
http.cors.allow-origin: /.*/常用的配置项如下:
cluster.name:
配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name:
节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理
一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
path.conf: 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch path.data: 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。 path.logs: 设置日志文件的存储路径,默认是es根目录下的logs文件夹 path.plugins: 设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.memory_lock: true 设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。 network.host: 设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。 http.port: 9200 设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300 集群结点之间通信端口
node.master: 指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新的master。 node.data: 指定该节点是否存储索引数据,默认为true。
discovery.zen.ping.unicast.hosts: ["host1:port", "host2:port", "..."] 设置集群中master节点的初始列表。
discovery.zen.ping.timeout: 3s 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。 discovery.zen.minimum_master_nodes:
主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。
node.max_local_storage_nodes:
单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1.jvm.options
设置最小及最大的JVM堆内存大小:
在jvm.options中设置 -Xms和-Xmx:
1) 两个值设置为相等
2) 将Xmx 设置为不超过物理内存的一半。
log4j2.properties
日志文件设置,ES使用log4j,注意日志级别的配置。
启动ES
进入bin目录,在cmd下运行:elasticsearch.bat
浏览器输入:http://localhost:9200
显示结果如下(配置不同内容则不同)说明ES启动成功:

head插件安装
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等,head的项目地址在https://github.com/mobz/elasticsearch-head 。
从ES6.0开始,head插件支持使得node.js运行。
1、安装node.js
2、下载head并运行
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
open HTTP://本地主机:9100 /
3、运行
打开浏览器调试工具发现报错:
Origin null is not allowed by Access-Control-Allow-Origin.
原因是:head插件作为客户端要连接ES服务(localhost:9200),此时存在跨域问题,elasticsearch默认不允许跨域访问。
解决方案:
设置elasticsearch允许跨域访问。
在config/elasticsearch.yml 后面增加以下参数:
#开启cors跨域访问支持,默认为false http.cors.enabled: true #跨域访问允许的域名地址,(允许所有域名)以上使用正则 http.cors.allow-origin: /.*/
注意:将config/elasticsearch.yml另存为utf-8编码格式。
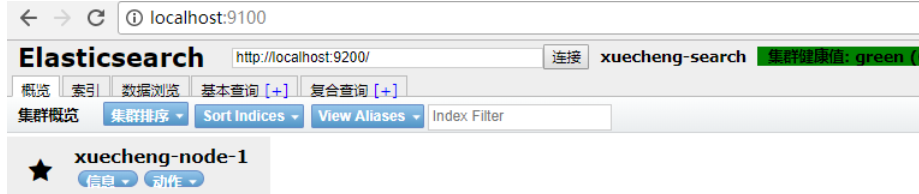
成功连接ES

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









