







 本文深入探讨强化学习中的重要概念,包括重要度采样、时序差分预测及其优势。通过对比蒙特卡洛方法和时序差分学习,阐述了在非平稳环境中的应用策略。并解析了TD(0)的最优性和批量更新策略。
本文深入探讨强化学习中的重要概念,包括重要度采样、时序差分预测及其优势。通过对比蒙特卡洛方法和时序差分学习,阐述了在非平稳环境中的应用策略。并解析了TD(0)的最优性和批量更新策略。
5.8 折扣敏感的重要度采样
之前的离线算法都需要为回报计算重要度采样的权重,它把回报视为单一整体,而不考虑回报是每个时刻的折后收益之和这一内部结构。
假设幕持续100步并且
γ
=
0
\gamma=0
γ=0,那么0时刻的回报就会是
G
0
=
R
1
G_0=R_1
G0=R1,但它的重要度采样却会是100个因子之积,也就是:
![]()
在普通重要度采样中会用整个乘积对回报进行缩放,但是实际上只需要按第一个因子来衡量,即
π
(
A
0
∣
S
0
)
/
b
(
A
0
∣
S
0
)
\pi(A_0|S_0)/b(A_0|S_0)
π(A0∣S0)/b(A0∣S0),另外99个因子都是无关的,因为
γ
=
0
\gamma=0
γ=0意味着得到首次收益后整幕回报就已经确定了,后面的因子与回报相独立且期望值为1,不会改变预期的更新,但它们会极大地增加其方差。
而避免这种与期望更新无关的巨大方差的一个思路就是把折扣看作幕部分终止的概率,也就是回报
G
0
G_0
G0看作在一步内,以
1
−
γ
1-\gamma
1−γ的概率部分终止产生的收益是
R
1
R_1
R1,再在两步内以
(
1
−
γ
)
γ
(1-\gamma)\gamma
(1−γ)γ的概率部分终止产生的收益是
R
1
+
R
2
R_1+R_2
R1+R2,以此类推,那么总回报可看作以上部分终止回报的总和:
 “部分”表示的含义是这些回报不会一直延续到终止,而在
h
h
h处就停止,对应的部分回报为:
“部分”表示的含义是这些回报不会一直延续到终止,而在
h
h
h处就停止,对应的部分回报为:

而对应的重要度采样比也要使用截断式,也就是只考虑到
h
h
h的概率:

该式即是用部分回报乘上对应的重要性采样比再求和,而对应的加权重要度采样即是:

两式与之前的主要区别也就是用部分回报代替了到终止的完整回报。
5.9 每次访问型重要度采样
在离线策略估计器中,分子中求和计算的每一项本身也可以化为收益的求和式:

注意其中每一个子项是一个随机收益和一个随机重要度采样比的乘积,而将其中的第一个子项改写成从t时刻到T时刻的重要度采样链:

这些因子中只有第一个和最后一个是相关的,其他的均为期望值为1的独立随机变量

写回求和的形式的时候,乘上每个动作a选择的时候按照动作策略的概率
b
(
a
∣
S
k
)
b(a|S_k)
b(a∣Sk)即可,这样约分之后就可知道每个因子均为期望值为1的独立随机变量。
每一个状态之间是相互独立的,而独立随机变量乘积的期望就是变量期望值的成绩,因此可以把除了第一项之外的所有因子移出期望,只剩下:

如果从最开始式子中的每一项都采取同样的分析,可以得到:

这样原式的期望就可以写成:
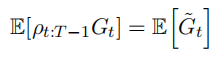
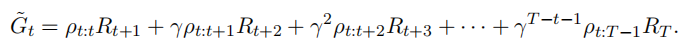
因此可以用这个式子来重新计算方差更小的无偏估计。
5.10 本章小结
本章介绍了从经验中学习价值函数和最优策略的蒙特卡洛方法。
相比DP算法的主要四个优点:
- 不需要描述环境动态特性的模型。
- 可以使用数据仿真或采样模型。
- 可以很简单和高校地聚焦于状态的一个小的子集。
- 在马尔科夫性不成立时的性能损失较小。
设计MC控制方法时,遵循GPI,并且提供了一种新的评估的方法,不需要计算每一个状态的价值,而只需要简单地从这个状态开始得到的多个回报平均即可。MC方法逐幕地进行策略评估和策略改进,并可以逐幕地增量式实现。
试探性出发可以保证足够的搜索。
本章需要掌握的几个重要部分:
- 在线策略和离线策略下的期望值函数和区别。
- 普通重要度采样和加权重要度采样。
- MC方法与DP方法的区别。
6.1 时序差分预测
时序差分学习结合了MC算法和DP算法的思想,可以直接从环境交互中学习而不需要构建环境特性模型,采用自举思想,可以基于已得到的其他状态的估计值来更新当前状态的价值函数。
MC方法需要一直等到一次访问后的回报知道之后,再用这个回报作为
V
(
S
t
)
V(S_t)
V(St)的目标进行估计,一个适用于非平稳环境的每次访问型MC方法可以表示成:

称为常量
α
\alpha
αMC,必须等到一幕的结尾才能确定对
V
(
S
t
)
V(S_t)
V(St)的增量,此时
G
t
G_t
Gt才已知,而TD方法只需要等到下一个时刻即可,也就是在时刻
t
+
1
t+1
t+1,TD方法可以使用观察到的收益Rt+1和估计值V(St+1)进行更新:

对应的表格型TD(0)算法如下:

TD(0)直接根据一个后继状态节点的单次采样转移来更新,TD算法和MC方法都是采样更新,并且TD更新的括号内的式子其实就是TD误差:

每个时刻的误差就是当前时刻估计的误差,取决于下一个状态和下一个收益。
而MC误差可以写成所有TD误差的和:

6.2 时序差分预测方法的优势
- 不需要环境模型。
- 运用了在线的、完全递增的方法来实现。
- 如果步长参数是一个足够小的参数,那么它的均值就能收敛到 v π v_\pi vπ。
- 虽然理论上很难证明不同方法的收敛速度,但是在实际应用中,TD方法在随机任务上通常比常量 α \alpha αMC算法收敛地更快。
6.3 TD(0)的最优性
在算法中,可以使用批量更新,也就是价值函数仅根据所有增量的和改变一次,虽然不能直接得到各自的更新结果,但是它们都是在朝那个最终方向上做出了某种程度的更新。
批量MC方法总是找到最小化训练集上的均方差误差的估计,而批量TD(0)总是找出完全符合MDP模型的最大似然估计参数,通常一个参数的最大似然估计是使得生成训练数据的概率最大的参数值。
从i到j的转移概率估计值,就是观察数据中从i出发转移到j的次数占从i出发的所有转移次数的比例,而相应的期望收益则是在这些转移中观察到的收益的平均值,可以据此来估计价值函数,当模型正确时,我们的估计就完全正确,这被称为确定性等价估计,因为它等价于假设潜在过程参数的估计是确定性的而不是近似的,批量TP(0)通常收敛到的就是确定性等价估计,这一点也就是TP方法比MC方法更快收敛的主要原因。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









