







首先我们要爬取一家银行数据
发现它的表单使用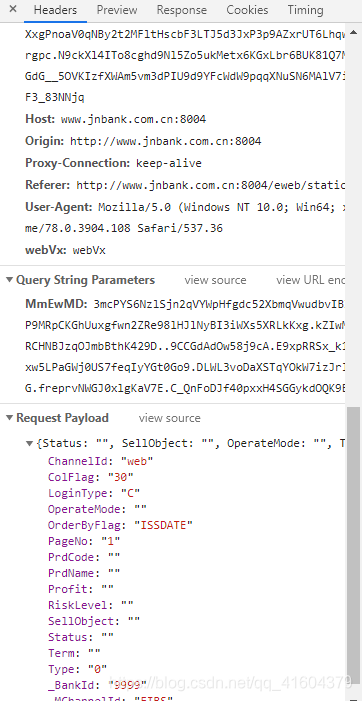
而不是一般使用的formdata
这时候我们要注意传过去的数据类型一定要是接送类型的
import requests
from fake_useragent import UserAgent
import json
headers = {"User-Agent": UserAgent().random,
}
cookies = {"Cookie": "FSSBBIl1UgzbN7N80S=N0Wj0MeCgtf1VKML0c4enCZwAqnGt3Z__zAl.983feP0HDC6LfZXOT8UuBNo94Bz; UM_distinctid=16eedd9aad7427-05dc1c99f7b591-2393f61-1fa400-16eedd9aad82ec; FSSBBIl1UgzbN7N8004S=Zv2vcq030TBJh8G.LktooAVdeBOP16arklQBtLR28K_UlBRhWNXz4oC46Wdfj7Vh; BIGipServerpool_ruishu_gw_8004=35995402.17439.0000; BIGipServerpool_menghu=19218186.20480.0000; BIGipServerpool_lsywly_7004=52653342.23579.0000; BIGipServerpool_gw_8004=18431754.17439.0000; BIGipServerpool_menghu_new_80=!cvODfqURptZHDbnZDfWm7qhBrhR0JVrI7BBFhfflVb4NDP2DuublcyGL1fYn0ruyuPhlOpFi3HJU; BIGipServerpool_mh_8000=!89nLaRuOdkfqIFDZDfWm7qhBrhR0JcmZohVQvXVHxAwZ2yczLZATPofP9n3PS+Ld8+xauOs77ADc; CNZZDATA1258289861=1740492663-1575948154-%7C1576111692; BIGipServerpool_mh_8001=18443550.16671.0000; JSESSIONID=G3b3xby9agMcKKH9kBXahRvX4gCkGDPZlze9m8Clh1nXmX6R8xQQ!-364854237; FSSBBIl1UgzbN7N80T=3tV5g5fy8gPgWgo7KBicSEFTb55gwHNWrl9gvFpATtyRdOQwJsm5sKK40jfVtDRedZPGIc1WwLo3o3gHIbAT8OnufOluPz62A6WiWG0knY4RspEhfaZuAbauG1WZBAGmNV099DzaCtjyrFcF8FCjKYYv0Uo13mWwcQaxfftci0PiGY2MMy7NbV8xPhwuXHaaC.g4vLXBkyyUD.EwQTa8chmSl35W4fk8_G.TUzO4K84kJ2_7ZqdAwqYXAFgS1ZOFgJDjOn8E.Gwq5AOyW.2oTyvfc; FSSBBIl1UgzbN7N8004T=3BEqeMehmX4EFHtCebMzx1TGKH9lzj8dMY7m6mC1CSIILi_2sCh_kvAiluuMk1JWEYpytZwYHBrMoRoQ8PtyeLLDu1dqvQbfXnJbRIkTTDNgHT2JI1KUzh4emjJcTOhnPz17hPxK0n4ps0FeLox45u6dbMbB2kuXDzCpMVRibGMh7Lz_MbG9wSdZVL6ZyR2HGa8drgn4Fej3E2raNVjlywlulOld9Efm.JHHSRwKRgW3504nUwWLcAWgbx_zsrGAk.IsMLJYL0KgfEdjaBU0cMD_OxY6HuBib9LeVJtFmqNgdia"}
payloadData = {
"ChannelId": "web",
"ColFlag": "30",
"LoginType": "C",
"OperateMode": "",
"OrderByFlag": "ISSDATE",
"PageNo": "1",
"PrdCode": "",
"PrdName": "",
"Profit": "",
"RiskLevel": "",
"SellObject": "",
"Status": "",
"Term": "",
"Type": "0",
"BankId": "9999",
"MChannelId": "EIBS",
"locale": "zh_CN"
}
# url = 'http://www.jnbank.com.cn:8004/eweb/static/index.html#/app/FProducts'
start_url = "http://www.jnbank.com.cn:8004/eweb/queryFinacialList.do?MmEwMD="
response = requests.post(url=start_url, data=json.dumps(payloadData),headers=headers)
# response = requests.Session.post(url=start_url, data=data, cookies=cookies,headers=headers)
print(response)
然后我们用requests测试了一下response返回给我们什么响应
竟然是一个400
我觉得是被反爬机制给发现了 但我还找不到他的js是怎么写的
这时候我选择了使用senlenium
使用senlenium跳过js 对页面进行渲染返回数据
一开始使用谷歌浏览器,发现页面还没等返回json数据就被拦截了
应该是我们使用selenium被反爬机制给监听到了
这个问题困扰了我几乎一天
然后后来才发现原来换个浏览器就好使了。。。。
火狐返回的数据是这样的 他抓取到了渲染后的网页
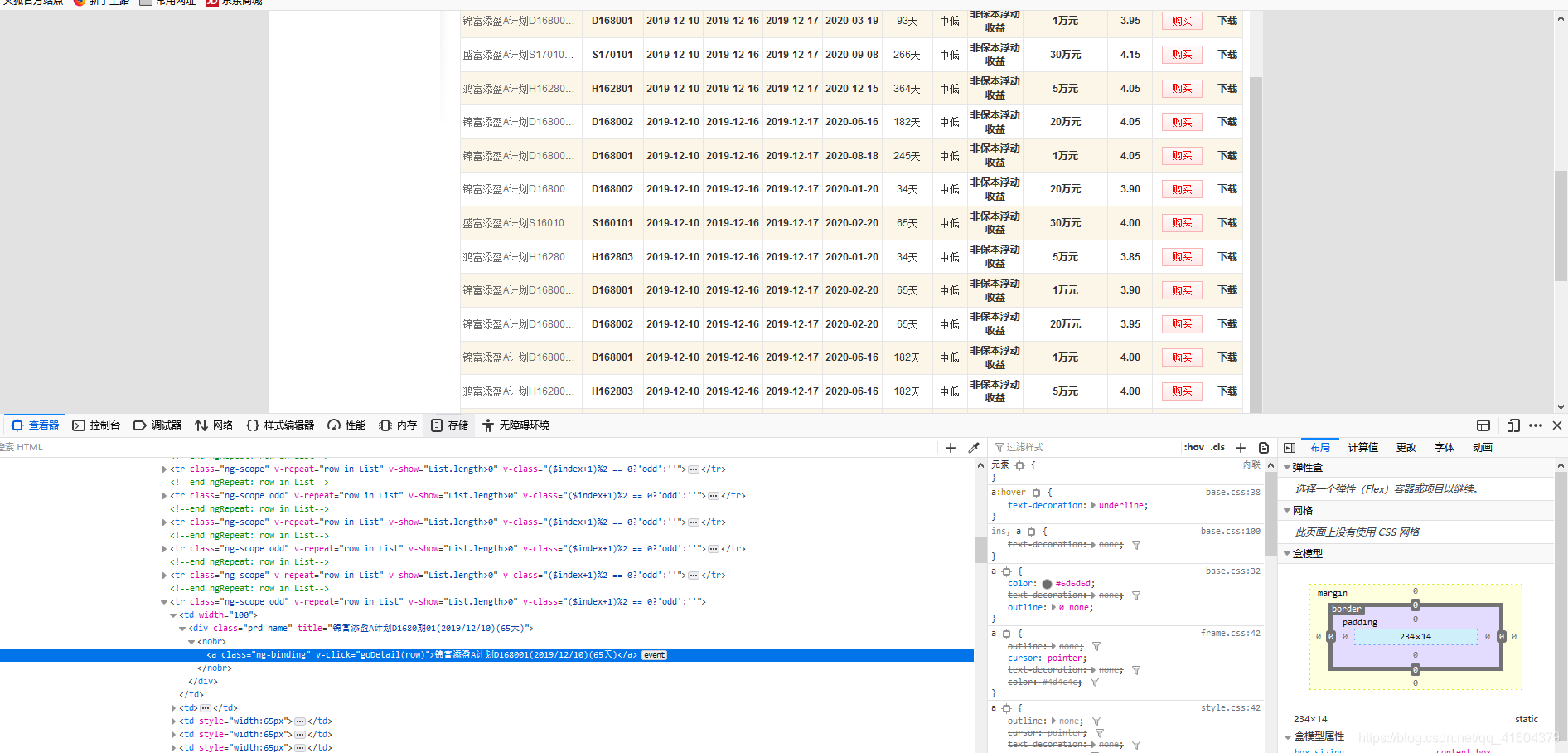
现在我们就需要将scrapy 和selenium结合起来
我们都知道爬虫的原理是这样的
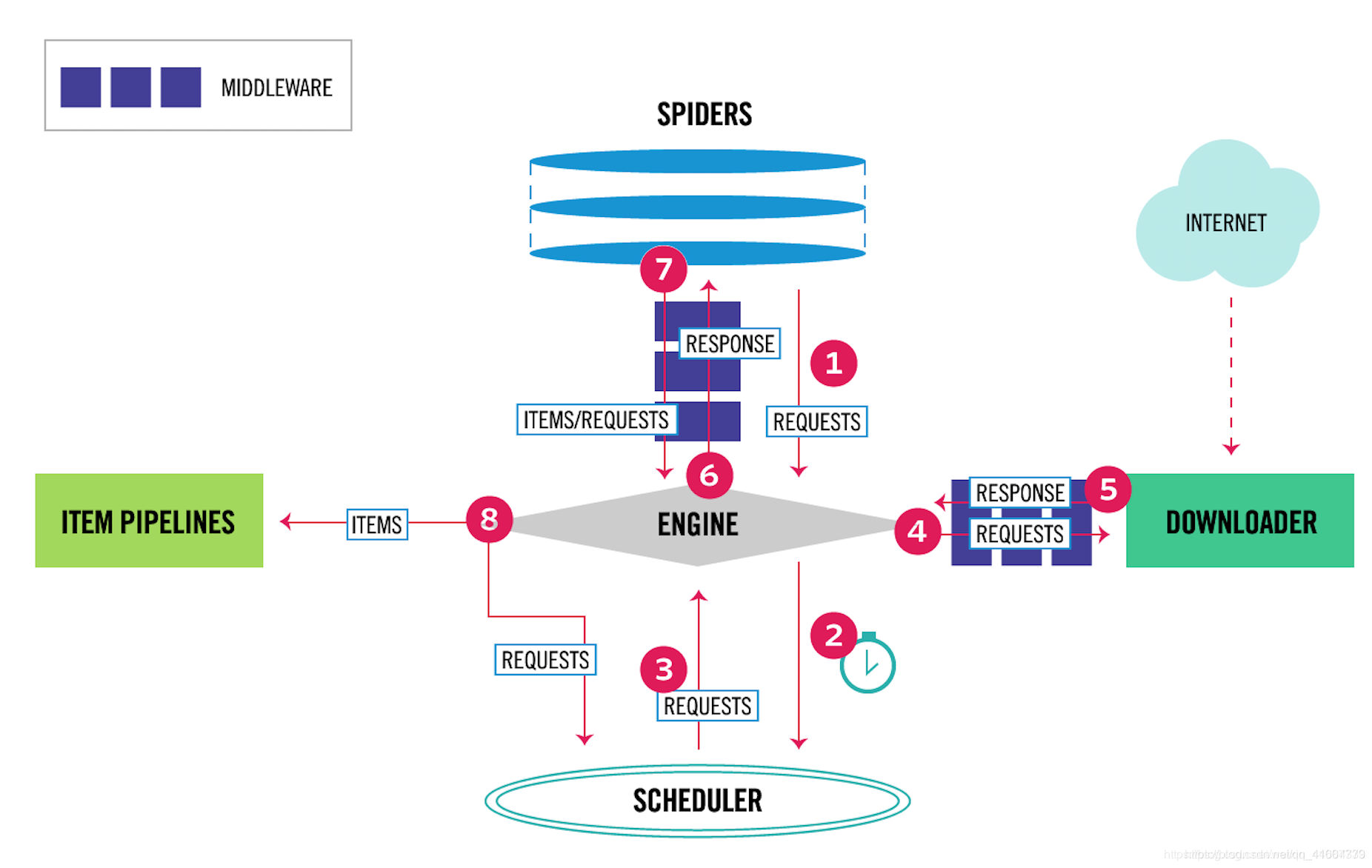
selenium是一个中间件 我们则需要他在第4步以及第5步给我们返回渲染过的代码 这样我们就可以根据返回回来的静态的html代码来分析数据了
所以我们要在middleware里配置selenium然后通过截取request 来返回response
大概就是这样的原理

















 3032
3032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









