







 本文探讨了参数化测试中数据不均衡和数据量不足的问题,指出参数化数据应根据业务场景和压力测试需求来确定。参数化数据来源分为已存在和需创建两种,并强调数据分布均衡的重要性。数据量的多少直接影响系统压力,过多或过少都无法准确反映真实场景。在数据库中,数据直方图的均衡性是确保测试有效性的关键因素。
本文探讨了参数化测试中数据不均衡和数据量不足的问题,指出参数化数据应根据业务场景和压力测试需求来确定。参数化数据来源分为已存在和需创建两种,并强调数据分布均衡的重要性。数据量的多少直接影响系统压力,过多或过少都无法准确反映真实场景。在数据库中,数据直方图的均衡性是确保测试有效性的关键因素。
1 参数化出现的问题
1)数据不均衡
同一个数据执行混合场景测试,在这种情况下对服务器的压力和真实环境下的完全不一样。有时我们不得不造很多参数化数据,也有很多工程师不考虑数据库表中的数据直方图,就直接在少量的参数化数据中创建了大量的相关记录。比如说在银行系统中造出大量的个人流水记录。
2)参数化数据量不足
使用少量的参数化数据进行大量业务操作的场景,会导致压力和真实场景不一致。
2 参数化疑问
参数化数据应该用多少数据量?
参数化数据从哪里来?
参数多与少的选择对系统压力有什么影响?
参数化数据在数据库中的直方图是否均衡?
2.1 技术角度解答疑问
举例:
对一个压力工具线程数为 100,TPS 有 1000 的系统,如果要运行 30 分钟
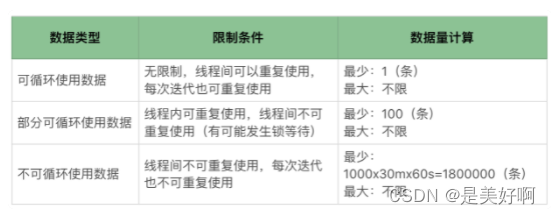
2.2 业务场景解答疑问
我们还是要从实际业务中考虑数据需要用哪种数据,以便计算数据量。数据类型是否可以循环使用等。
场景一:
我们做脚本时考虑的是,有多少线程(Thread)就配置多少用户,让每个线程在同一个用户上循环执行。
用户数据=线程个数
场景二:
电商系统,用同一个用户账号不停循环购买商品,就是不符合真实场景的。
tpsx持续时间(秒级)
场景三:
就是在一个线程之中,可以循环使用固定条目的数
2.3 参数化数据的来源
第一类:
用户输入的数据在后台数据库中已存在,比如我们上面示例中的用户数据。这类数据的特点是什么呢?
存在后台数据库中;
需要用户主动输入;
用户输入的数据会和后台数据库中的数据做比对。
这类数据必须查询数据库之后再参数化到工具中。
第二类
用户输入的数据在后台数据库中不存在。在业务流中,这些数据会 Insert 或 Update 到数据库中。这类数据的特点是什么呢?
数据库中原本不存在这些数据;
在脚本执行成功后会将这些数据 insert 或 update 到数据库中;
每个用户输入的数据可能相同,也可能不同,这取决于业务特点。
这类数据必须通过压力工具做参数化,同时也必须满足业务规则。
造数据要求:
要满足生产环境中数据的分布;
要满足性能场景中数据量的要求。
2.3 参数取多与少对系统压力的影响
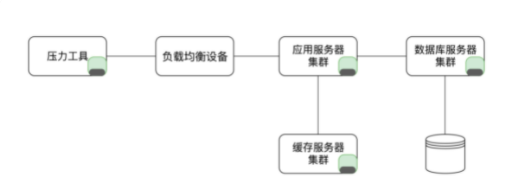
绿色部分代表数据在各系统中的正常大小,而黑色部分代表压力工具中使用的数据量大小。
显然图中所示的黑色部分是很少的,完全不能把后端各类服务器的缓存占用到真实场景中应该有的大小,所以在这种状态之下是测试不出来真实场景下的压力的。
对数据库连接的存储设备来说同样也有影响。如果数据量少,则相应的存储的 I/O 使用就少。对于一个没有被 Cache 的数据来说,首次使用肯定会触发 I/O,也就是会产生寻址、PageFalut 等情况。
参数取得过多,对系统的压力就会大;参数取得过少,不符合真实场景中的数据量,则无法测试出系统真实的压力。
2.4 参数化数据在数据库中的直方图是否均衡
数据库中的数据直方图。 对于直接从生产上拿的数据来说,数据的分布更为精准。但是对于一些在测试环境中造的数据,则一定要在造数据之后,检查下数据分布是否与生产一致。
我们过滤掉不合理的数据即可


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









