







前提
最近可能要做一些异构编程的东西,大家都知道的异构编程莫非就是Cuda编程了,有host有device。这里对Cuda程序也就是.cu文件的编译过程做一个简单的梳理,网上已经有比较多的资料了,这里之所以写这样的一篇博客是想将这个过程亲自动手实践下。
正文
可以从cuda官网得到cuda程序的编译过程流图,如下所示:
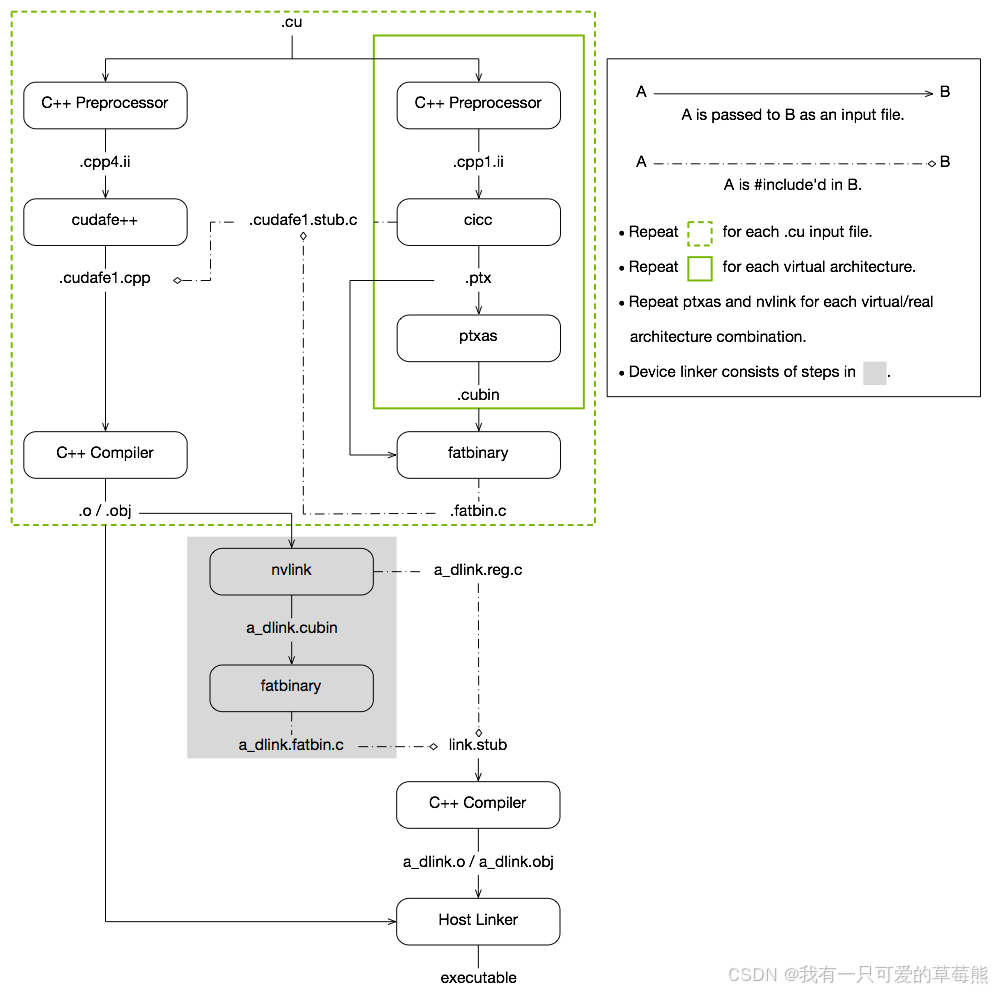
接下来我们就对着这张图将整个cuda程序编译的过程走一遍。
本次实验是在 NVIDIA GeForce GTX 1080显卡上进行,nvcc的版本是12.4。
准备一个cuda程序
这里我们写一个简单的向量加和的cuda程序vectorAdd.cu,什么程序不重要,重要的是编译的这个过程。
#include <iostream>
#include <cuda_runtime.h>
__global__ void vectorAdd(const float *A, const float *B, float *C, int n) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < n) {
C[i] = A[i] + B[i];
}
}
int main() {
int n = 100000;
size_t size = n * sizeof(float);
// 分配主机内存
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
// 初始化输入向量
for (int i = 0; i < n; i++) {
h_A[i] = static_cast<float>(i);
h_B[i] = static_cast<float>(i * 2);
}
// 分配设备内存
float *d_A, *d_B, *d_C;
cudaMalloc((void **)&d_A, size);
cudaMalloc((void **)&d_B, size);
cudaMalloc((void **)&d_C, size);
// 将输入数据从主机复制到设备
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// 定义线程块和网格尺寸
int blockSize = 256;
int numBlocks = (n + blockSize - 1) / blockSize;
// 启动 CUDA 核函数
vectorAdd<<<numBlocks, blockSize>>>(d_A, d_B, d_C, n);
// 将结果从设备复制回主机
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// 检查结果(只打印前10个元素以验证)
for (int i = 0; i < 10; i++) {
std::cout << "C[" << i << "] = " << h_C[i] << std::endl;
}
// 释放设备内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 释放主机内存
free(h_A);
free(h_B);
free(h_C);
return 0;
}
编译过程探究
编译vectorAdd.cu,这里我们添加-dryrun选项,-dryrun用于显示nvcc实际执行的编译和链接命令,而不去执行它们。总得来说,当使用-dryrun选项时,nvcc会显示编译器如何处理CUDA代码,包括调用预处理器,编译器,汇编器和链接器的具体命令。
在终端输入:
nvcc -dryrun vectorAdd.cu
输出如下:
#$ _NVVM_BRANCH_=nvvm
#$ _NVVM_BRANCH_SUFFIX_=
#$ _SPACE_=
#$ _CUDART_=cudart
#$ _HERE_=/usr/local/cuda-12.4/bin
#$ _THERE_=/usr/local/cuda-12.4/bin
#$ _TARGET_SIZE_=
#$ _TARGET_DIR_=
#$ _TARGET_DIR_=targets/x86_64-linux
#$ TOP=/usr/local/cuda-12.4/bin/..
#$ NVVMIR_LIBRARY_DIR=/usr/local/cuda-12.4/bin/../nvvm/libdevice
#$ LD_LIBRARY_PATH=/usr/local/cuda-12.4/bin/../lib:/usr/local/cuda-12.4/lib64:
#$ PATH=/usr/local/cuda-12.4/bin/../nvvm/bin:/usr/local/cuda-12.4/bin:/usr/local/cuda-12.4/bin:/home/hacker/Software/miniconda3/bin:/home/hacker/Software/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
#$ INCLUDES="-I/usr/local/cuda-12.4/bin/../targets/x86_64-linux/include"
#$ LIBRARIES= "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib"
#$ CUDAFE_FLAGS=
#$ PTXAS_FLAGS=
#$ gcc -D__CUDA_ARCH_LIST__=520 -D__NV_LEGACY_LAUNCH -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-12.4/bin/../targets/x86_64-linux/include" -D__CUDACC_VER_MAJOR__=12 -D__CUDACC_VER_MINOR__=4 -D__CUDACC_VER_BUILD__=99 -D__CUDA_API_VER_MAJOR__=12 -D__CUDA_API_VER_MINOR__=4 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -include "cuda_runtime.h" -m64 "vectorAdd.cu" -o "/tmp/tmpxft_0002eb1a_00000000-5_vectorAdd.cpp4.ii"
#$ cudafe++ --c++17 --gnu_version=110400 --display_error_number --orig_src_file_name "vectorAdd.cu" --orig_src_path_name "/home/hacker/Workspace/vectorAdd.cu" --allow_managed --m64 --parse_templates --gen_c_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.cpp" --stub_file_name "tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.stub.c" --gen_module_id_file --module_id_file_name "/tmp/tmpxft_0002eb1a_00000000-4_vectorAdd.module_id" "/tmp/tmpxft_0002eb1a_00000000-5_vectorAdd.cpp4.ii"
#$ gcc -D__CUDA_ARCH__=520 -D__CUDA_ARCH_LIST__=520 -D__NV_LEGACY_LAUNCH -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-12.4/bin/../targets/x86_64-linux/include" -D__CUDACC_VER_MAJOR__=12 -D__CUDACC_VER_MINOR__=4 -D__CUDACC_VER_BUILD__=99 -D__CUDA_API_VER_MAJOR__=12 -D__CUDA_API_VER_MINOR__=4 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -include "cuda_runtime.h" -m64 "vectorAdd.cu" -o "/tmp/tmpxft_0002eb1a_00000000-9_vectorAdd.cpp1.ii"
#$ cicc --c++17 --gnu_version=110400 --display_error_number --orig_src_file_name "vectorAdd.cu" --orig_src_path_name "/home/hacker/Workspace/vectorAdd.cu" --allow_managed -arch compute_52 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin.c" -tused --module_id_file_name "/tmp/tmpxft_0002eb1a_00000000-4_vectorAdd.module_id" --gen_c_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.c" --stub_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.stub.c" --gen_device_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.gpu" "/tmp/tmpxft_0002eb1a_00000000-9_vectorAdd.cpp1.ii" -o "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx"
#$ ptxas -arch=sm_52 -m64 "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx" -o "/tmp/tmpxft_0002eb1a_00000000-10_vectorAdd.sm_52.cubin"
#$ fatbinary -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " "--image3=kind=elf,sm=52,file=/tmp/tmpxft_0002eb1a_00000000-10_vectorAdd.sm_52.cubin" "--image3=kind=ptx,sm=52,file=/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx" --embedded-fatbin="/tmp/tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin.c"
#$ rm /tmp/tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin
#$ gcc -D__CUDA_ARCH__=520 -D__CUDA_ARCH_LIST__=520 -D__NV_LEGACY_LAUNCH -c -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -Wno-psabi "-I/usr/local/cuda-12.4/bin/../targets/x86_64-linux/include" -m64 "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.cpp" -o "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o"
#$ nvlink -m64 --arch=sm_52 --register-link-binaries="/tmp/tmpxft_0002eb1a_00000000-7_a_dlink.reg.c" "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib" -cpu-arch=X86_64 "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o" -lcudadevrt -o "/tmp/tmpxft_0002eb1a_00000000-12_a_dlink.sm_52.cubin" --host-ccbin "gcc"
#$ fatbinary -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " -link "--image3=kind=elf,sm=52,file=/tmp/tmpxft_0002eb1a_00000000-12_a_dlink.sm_52.cubin" --embedded-fatbin="/tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin.c"
#$ rm /tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin
#$ gcc -D__CUDA_ARCH_LIST__=520 -D__NV_LEGACY_LAUNCH -c -x c++ -DFATBINFILE="\"/tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin.c\"" -DREGISTERLINKBINARYFILE="\"/tmp/tmpxft_0002eb1a_00000000-7_a_dlink.reg.c\"" -I. -D__NV_EXTRA_INITIALIZATION= -D__NV_EXTRA_FINALIZATION= -D__CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__ -Wno-psabi "-I/usr/local/cuda-12.4/bin/../targets/x86_64-linux/include" -D__CUDACC_VER_MAJOR__=12 -D__CUDACC_VER_MINOR__=4 -D__CUDACC_VER_BUILD__=99 -D__CUDA_API_VER_MAJOR__=12 -D__CUDA_API_VER_MINOR__=4 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -m64 "/usr/local/cuda-12.4/bin/crt/link.stub" -o "/tmp/tmpxft_0002eb1a_00000000-13_a_dlink.o"
#$ g++ -D__CUDA_ARCH_LIST__=520 -D__NV_LEGACY_LAUNCH -m64 -Wl,--start-group "/tmp/tmpxft_0002eb1a_00000000-13_a_dlink.o" "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o" "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib" -lcudadevrt -lcudart_static -lrt -lpthread -ldl -Wl,--end-group -o "a.out"
可以看到有很多信息,这里我先将重要信息摘出来,再做分析,如下:
1. #$ gcc -m64 -E "vectorAdd.cu" -o "/tmp/tmpxft_0002eb1a_00000000-5_vectorAdd.cpp4.ii"
2. #$ cudafe++ --orig_src_file_name "vectorAdd.cu" --orig_src_path_name "/home/hacker/Workspace/vectorAdd.cu" --gen_c_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.cpp" --stub_file_name "tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.stub.c --gen_module_id_file --module_id_file_name "/tmp/tmpxft_0002eb1a_00000000-4_vectorAdd.module_id" "/tmp/tmpxft_0002eb1a_00000000-5_vectorAdd.cpp4.ii"
3. #$ gcc -m64 -E "vectorAdd.cu" -o "/tmp/tmpxft_0002eb1a_00000000-9_vectorAdd.cpp1.ii"
4. #$ cicc --orig_src_file_name "vectorAdd.cu" -m64 --include_file_name "tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin.c" --module_id_file_name "/tmp/tmpxft_0002eb1a_00000000-4_vectorAdd.module_id" --gen_c_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.c" --stub_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.stub.c" --gen_device_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.gpu" "/tmp/tmpxft_0002eb1a_00000000-9_vectorAdd.cpp1.ii" -o "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx"
5. #$ ptxas "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx" -o "/tmp/tmpxft_0002eb1a_00000000-10_vectorAdd.sm_52.cubin"
6. #$ fatbinary -64 "--image3=kind=elf,sm=52,file=/tmp/tmpxft_0002eb1a_00000000-10_vectorAdd.sm_52.cubin" "file=/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx" --embedded-fatbin="/tmp/tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin.c"
7. #$ rm /tmp/tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin
8. #$ gcc -m64 "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.cpp" -o "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o"
9. #$ nvlink --register-link-binaries="/tmp/tmpxft_0002eb1a_00000000-7_a_dlink.reg.c" -cpu-arch=X86_64 "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o" -o "/tmp/tmpxft_0002eb1a_00000000-12_a_dlink.sm_52.cubin"
10. #$ fatbinary -link "--image3=kind=elf,sm=52,file=/tmp/tmpxft_0002eb1a_00000000-12_a_dlink.sm_52.cubin" --embedded-fatbin="/tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin.c"
11. #$ rm /tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin
12. #$ gcc -c -DFATBINFILE="\"/tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin.c\"" -m64 "/usr/local/cuda-12.4/bin/crt/link.stub" -o "/tmp/tmpxft_0002eb1a_00000000-13_a_dlink.o"
13. #$ g++ "/tmp/tmpxft_0002eb1a_00000000-13_a_dlink.o" "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o" "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib/stubs" -o "a.out"
接下来我们一条一条指令地去分析这个过程。
第一条命令
第一条命令是:
gcc -m64 -E "vectorAdd.cu" -o "/tmp/tmpxft_0002eb1a_00000000-5_vectorAdd.cpp4.ii"
非常清楚了吧,就是输入vectorAdd.cu,输出xxxx_vectorAdd.cpp4.ii文件。其中-m64表示目标架构是64位的,-E表示只进行预处理。和流程图中标1的步骤完全一样。
第二条命令
第二条命令是:
cudafe++ --orig_src_file_name "vectorAdd.cu" --orig_src_path_name "/home/hacker/Workspace/vectorAdd.cu" --gen_c_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.cpp" --stub_file_name "tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.stub.c --gen_module_id_file --module_id_file_name "/tmp/tmpxft_0002eb1a_00000000-4_vectorAdd.module_id" "/tmp/tmpxft_0002eb1a_00000000-5_vectorAdd.cpp4.ii"
cudafe++的目的是从预处理后的文件xxx_vectorAdd.cpp4.ii中分离出host和device代码。
--gen_c_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.cpp"会产生一个C++的中间文件,包含主机代码和与设备代码的接口(可以理解为是主机文件)。--stub_file_name "tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.stub.c生成包含设备代码的文件。--module_id_file_name "/tmp/tmpxft_0002eb1a_00000000-4_vectorAdd.module_id"生成模块的唯一标识符和版本信息,在我们这篇博客中没有太多的用处。
总得来说,第二条命令对应流程图中的步骤2。
第三条命令
gcc -m64 -E "vectorAdd.cu" -o "/tmp/tmpxft_0002eb1a_00000000-9_vectorAdd.cpp1.ii"
这一条指令和第一条指令相似,都是做预处理。对应流程图中的标号3。
第四条命令
cicc --orig_src_file_name "vectorAdd.cu" -m64 --include_file_name "tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin.c" --module_id_file_name "/tmp/tmpxft_0002eb1a_00000000-4_vectorAdd.module_id" --gen_c_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.c" --stub_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.stub.c" --gen_device_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.gpu" "/tmp/tmpxft_0002eb1a_00000000-9_vectorAdd.cpp1.ii" -o "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx"
cicc命令将设备代码文件编译为.ptx文件。其中
--gen_device_file_name "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.gpu"保存着实际在GPU上执行的代码。-o "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx"输出.ptx文件。.ptx是NVIDIA的中间表示格式(类似汇编),描述了设备代码的指令。
这一步对应着标号4。
第五条命令
$ ptxas "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx" -o "/tmp/tmpxft_0002eb1a_00000000-10_vectorAdd.sm_52.cubin"
ptxas是CUDA编译工具链中的汇编器,用于将.ptx(Parallel Thread Execution)文件编译成 .cubin(CUDA binary)文件。.cubin 是底层的二进制文件,直接用于在 GPU 上运行。
这一步对应着标号5。
第六条命令
fatbinary -64 "--image3=kind=elf,sm=52,file=/tmp/tmpxft_0002eb1a_00000000-10_vectorAdd.sm_52.cubin" "file=/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.ptx" --embedded-fatbin="/tmp/tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin.c"
fatbinary用于创建fat的二进制文件,将.ptx文件和.cubin文件打包成一个fat二进制文件,并嵌入到.fatbin.c文件中供后续使用。
从图中可以看到,.fatbin.c被include在.cudafe1.stub.c里,而.cudafe1.sub.c又被include在.cudafe1.cpp里,这样一来,生成的xxx_vectorAdd.fatbin.c最终也是被include在了.cudafe1.cpp里。
第七条命令
rm /tmp/tmpxft_0002eb1a_00000000-3_vectorAdd.fatbin
这条命令应该是将中间文件删除
第八条命令
gcc -m64 -c "/tmp/tmpxft_0002eb1a_00000000-6_vectorAdd.cudafe1.cpp" -o "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o"
-c代表gcc只执行编译过程,但不进行链接,生成.o文件。
第九条命令
nvlink --register-link-binaries="/tmp/tmpxft_0002eb1a_00000000-7_a_dlink.reg.c" -cpu-arch=X86_64 "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o" -o "/tmp/tmpxft_0002eb1a_00000000-12_a_dlink.sm_52.cubin"
nvlink用于将CUDA设备代码链接起来,生成一个.cubin文件,这个文件包含所有的设备代码,可以在GPU上直接运行。这一条命令和下一条命令都是设备代码linker的部分。
第十条命令
fatbinary -link "--image3=kind=elf,sm=52,file=/tmp/tmpxft_0002eb1a_00000000-12_a_dlink.sm_52.cubin" --embedded-fatbin="/tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin.c"
第十一条命令
这条指令是rm,没太大意义。
第十二条命令
gcc -c -DFATBINFILE="\"/tmp/tmpxft_0002eb1a_00000000-8_a_dlink.fatbin.c\"" -m64 "/usr/local/cuda-12.4/bin/crt/link.stub" -o "/tmp/tmpxft_0002eb1a_00000000-13_a_dlink.o"
-c还是只编译不链接,gcc会编译CUDA链接存根文件,生成目标文件a_dlink.o,a_dlink.fatbin.c文件被include在link.stub里。
第十三条命令
g++ "/tmp/tmpxft_0002eb1a_00000000-13_a_dlink.o" "/tmp/tmpxft_0002eb1a_00000000-11_vectorAdd.o" "-L/usr/local/cuda-12.4/bin/../targets/x86_64-linux/lib/stubs" -o "a.out"
这一步会将第八条命令生成的vectorAdd.o文件和上一步生成的a_dlink.o链接到一起,生成可执行程序a.out。
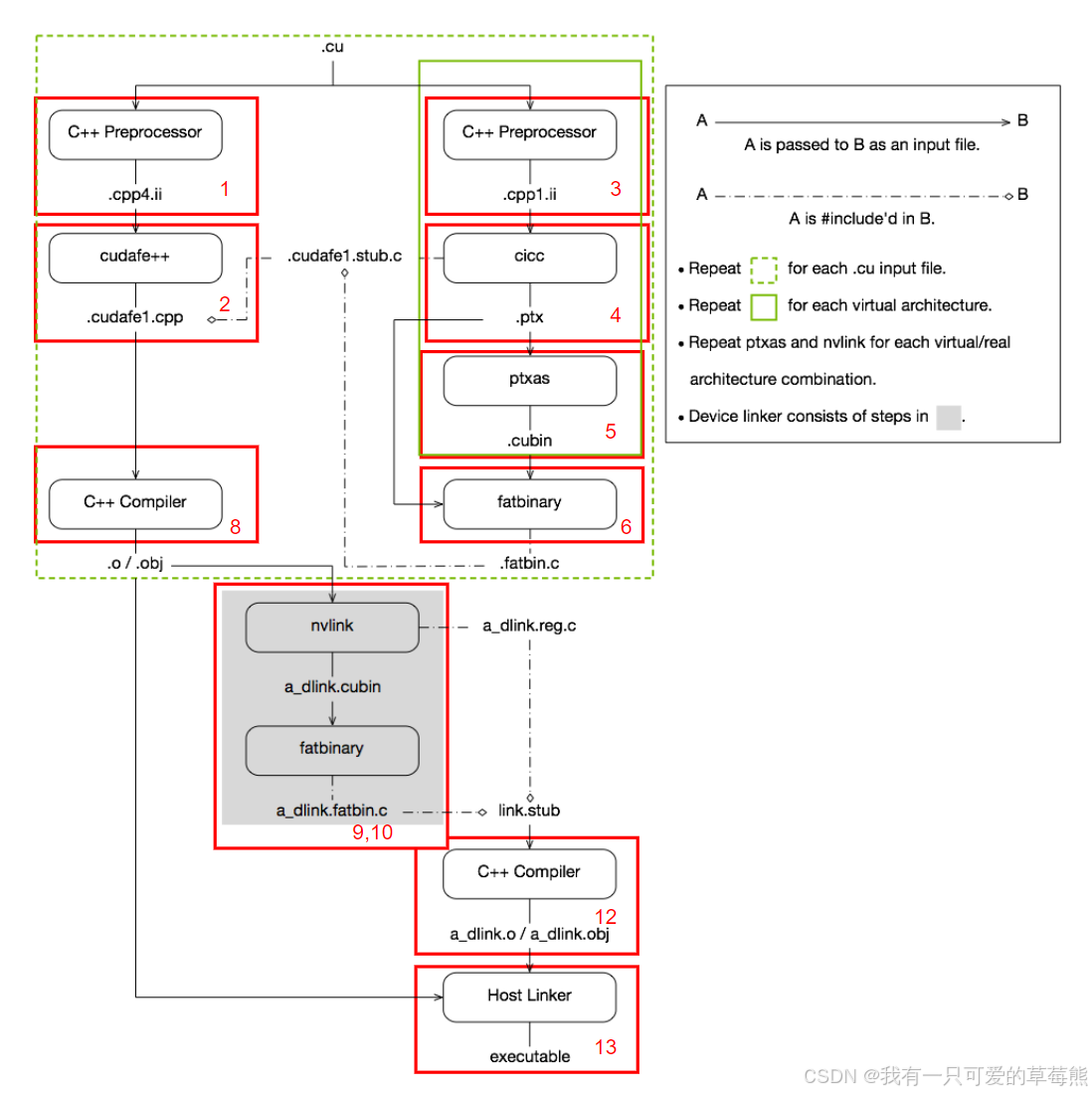
总结
以上就是CUDA程序编译的过程,看起来是要比我们只编译主机代码复杂。继续加油吧,少年!!!
参考链接
- https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









