







 本文介绍了HBase的读数据和写数据流程。读数据时,Client通过Zookeeper获取Meta表位置,访问HRegionServer读取元数据,然后访问HRegion获取数据。写数据时,Client同样通过Zookeeper找到对应HRegionServer,数据先写入HLog确保不丢失,再写入Memstore,当Memstore达到阈值会flush到Storefile,经过Compact和Split操作进行数据管理和优化。
本文介绍了HBase的读数据和写数据流程。读数据时,Client通过Zookeeper获取Meta表位置,访问HRegionServer读取元数据,然后访问HRegion获取数据。写数据时,Client同样通过Zookeeper找到对应HRegionServer,数据先写入HLog确保不丢失,再写入Memstore,当Memstore达到阈值会flush到Storefile,经过Compact和Split操作进行数据管理和优化。
来源:https://www.bilibili.com/video/av36033875?from=search&seid=12700632591522714293
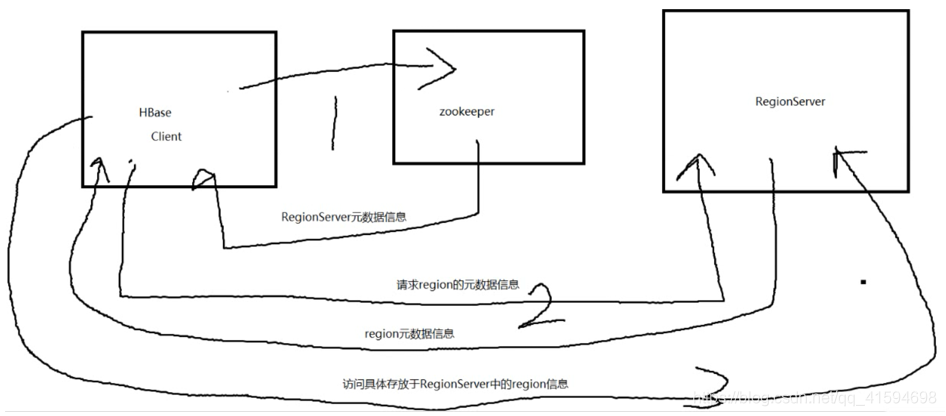
读数据流程
注:
- HRegionServer保存着meta表以及表数据
1.要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。(region元数据信息存在regionServer,regionServer的元数据信息存在zookeeper)
2.接着Client通过刚才获取到的HRegionServer的IP来访问Meta表所在的HRegionServer,从而读取到Meta,进而获取到Meta表中存放的元数据。
3.Client通过元数据中存储的信息,访问对应的HRegion,然后扫描所在HRegion的Memstore和Storefile来查询数据;最后HRegion把查询到的数据响应给Client。
流程图如下:
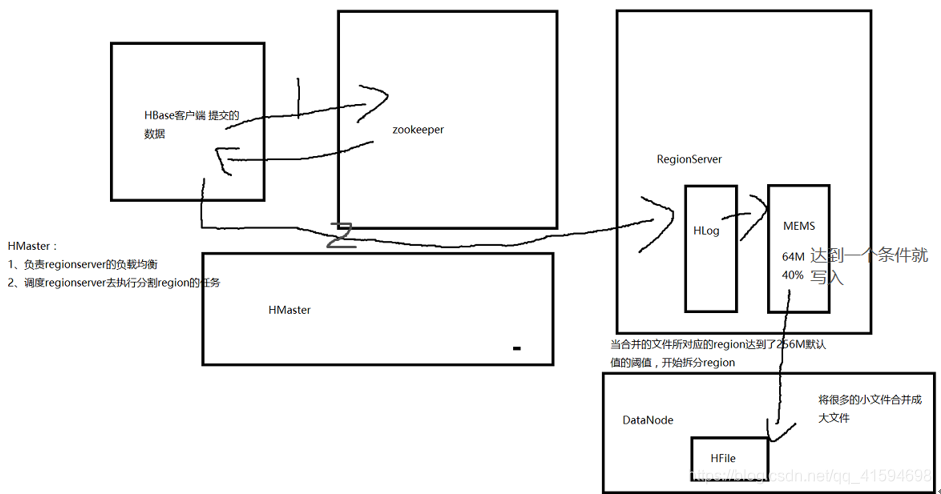
写数据流程
注1:
- 此过程中,HMaster不会直接参与
1.负载均衡:即某个RegionServer宕机后,HMaster会将其region转移到其他RegionServer上
2.分割region
1.Client也是先访问zookeeper,找到Meta表,并获取Meta表元数据。
确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
2.然后Client向该HRegionServer服务器发起写入数据请求,HRegionServer收到请求并响应。
Client先把数据写入到HLog(在Linux本地),以防止数据丢失。然后将数据写入到Region中的Memstore。如果HLog和Memstore均写入成功,则这条数据写入成功
- 注2:
1.如果Memstore达到阈值,会把Memstore中的数据flush到Storefile中。
2.当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile。
3.当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为二。
流程图如下:

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









