




 本文介绍了SQL中如何使用LIKE进行模糊查询,包括下划线_和百分号%的通配符用法,以及转义字符的使用。此外,还详细讲解了AND、OR逻辑运算符的组合使用,以及NOT的否定条件。内容涵盖通配符查询的效率问题、多个条件的组合过滤,并通过实例展示了各种查询效果。
本文介绍了SQL中如何使用LIKE进行模糊查询,包括下划线_和百分号%的通配符用法,以及转义字符的使用。此外,还详细讲解了AND、OR逻辑运算符的组合使用,以及NOT的否定条件。内容涵盖通配符查询的效率问题、多个条件的组合过滤,并通过实例展示了各种查询效果。
如果不知道要过滤的具体条件怎么查询呢?用模糊查询



数据过滤- WHERE [列] LIKE、通配符(_%)、转义字符(\)
LIKE 模糊查询:非已知,不明确查询条件。
1. 通配符–下划线
(1)一个下划线_代表: 单个的任何字符(指一个字或字母或数字或字符)
(2)使用: WHERE [列名 ] LIKE ‘…_…’
文本要加引号!
(3)适合场景:知道字符数目;知道字符位置
所以会出现连续的下划线
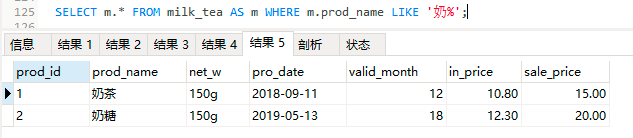
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '奶_';
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '薯_';
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '_糖';
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '__糖';
#最后一行写了两个下划线,要找的是三个字且最后一个字是糖




2. 通配符-百分号%
(1)%代表: 任意数目(包括0个)的任何字符
(2)使用: WHERE [列名 ] LIKE ‘…%…’
(3)适用范围: 不知道字符数目;知道字符位置
(就是知道在什么位置可能有一个或几个不知道的字符,也可以代表0个字符,即也可能没有字符)
所以不会出现连续的两个百分号
注:以通配符开头,查询效率低
(比如’奶_‘只需要搜索奶字开头的两个字词语,而’_糖’需要从头比对第二个字是否是糖字)
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '方%';
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '%糖';
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '方%面';
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '方便%面';
SELECT m.* FROM milk_tea AS m WHERE m.prod_name LIKE '奶%';




3. 转义字符\
Q:如果列中本来的内容就包含下划线_或者百分号%,那么进行通配符查询的时候怎么知道是原来就有的下划线百分号,还是通配符的下划线百分号呢?
A:用转义字符\
解释:转义字符\ 含义是 在它后面紧跟着的符号 仅代表 那个符号本身,比如 \ %指的就是百分号本身,而不是通配符%。
SELECT p.* FROM pet AS p WHERE p.owner LIKE 'Gw%_en' ;
#%能匹配至少0个任意字符,_能匹配1个任意字符,合在一起用就是匹配至少1个任意字符
SELECT p.* FROM pet AS p WHERE p.owner LIKE 'Gw__en' ;
#两个下划线匹配两个任意字符
SELECT p.* FROM pet AS p WHERE p.owner LIKE 'Gw%en' ;
#1个百分号能匹配至少0个任意字符
SELECT p.* FROM pet AS p WHERE p.owner LIKE 'Gw\%_en' ;
#\%代表百分号本身,1个下划线匹配1个任意字符
SELECT p.* FROM pet AS p WHERE p.owner LIKE 'Gw\%_en' ;
#指第三位一定是百分号%,1个下划线匹配1个任意字符
SELECT p.* FROM pet AS p WHERE p.owner LIKE 'Gw\%\_en' ;
#\%代表百分号本身,\_代表下划线本身,这个语句是匹配Gw%%en
结果1:
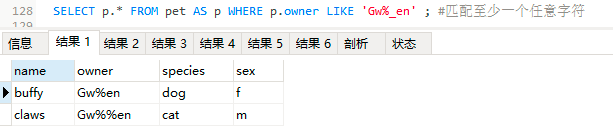
第一行结果相当于语句中 %_ 匹配了1个百分号字符
第二行结果相当于语句中 %_匹配了2个百分号字符
结果2:
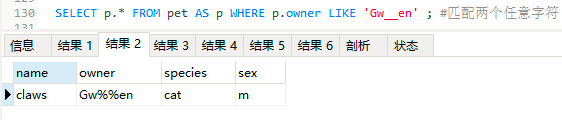
两个下划线匹配到了两个百分号字符
结果3:
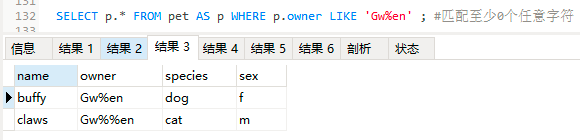
结果4:
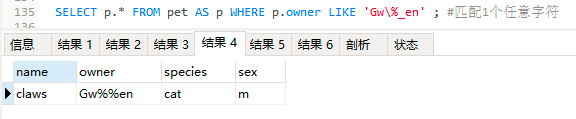
结果5:
 结果6:
结果6:
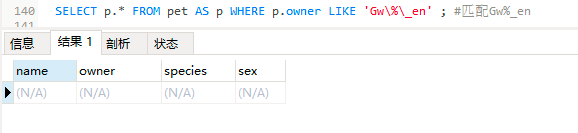
因为设置的表中没有Gw%_en这个数据
4. 且AND
使用场景:同时满足两个或多个条件(不止一个过滤条件且条件需要同时满足)
写法:WHERE [条件1] AND [条件2]…;
AND(和)类似求 交集
SELECT * FROM milk_tea AS m WHERE m.sale_price BETWEEN 5 AND 15; #1
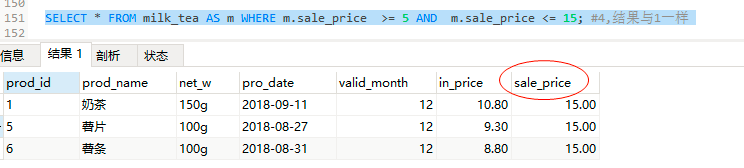
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5;#2
SELECT * FROM milk_tea AS m WHERE m.sale_price <= 15;#3
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND m.sale_price <= 15; #4,结果与1一样
所以
WHERE [列名] BETWEEN 值1 AND 值2
等价于
WHERE [列名] >= 值1 AND [列名] <= 值2
结果1:
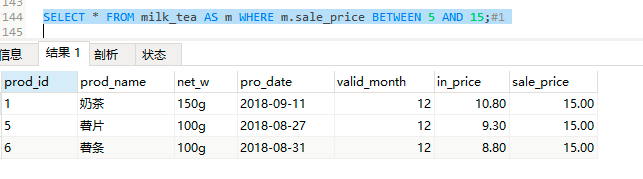 结果2:
结果2:
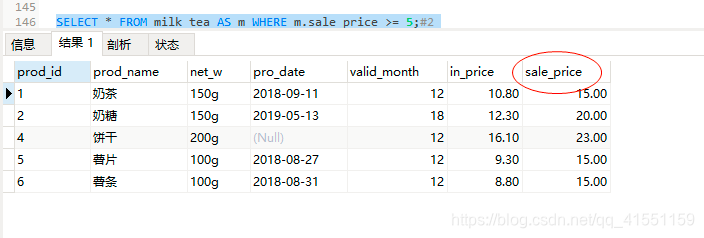 结果3:
结果3:
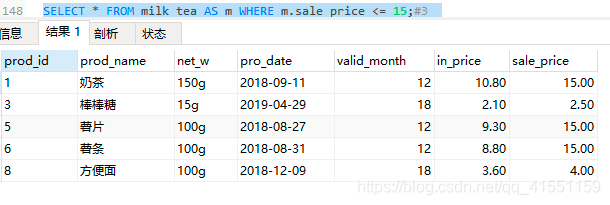 结果4:
结果4:
5. 或OR
使用场景:两个或多个条件,至少满足一个(不止一个过滤条件,只要满足其中一个就可)
写法:WHERE [条件1] OR [条件2] ;
OR(或)类似求 并集
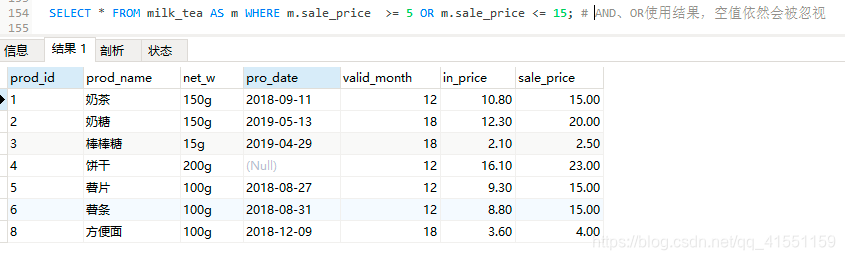
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 OR m.sale_price <= 15;
#AND、OR使用结果,空值依然会被忽视
6. 组合AND…OR
使用场景:多个条件,不同要求。(复杂情况)
写法:WHERE [条件1] AND [条件2] OR [条件3]…;
注:所有能用在WHERE的语句都可以用AND、OR将他们连接起来,比如比较><=、BETWEEN AND,通配符LIKE,判断空值IS(NOT) NULL。
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND m.sale_price <= 15 AND m.sale_price BETWEEN 1 AND 4 ;
#同时满足三个条件,因为前两个条件与第三个条件矛盾,结果为空
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND m.sale_price <= 15 OR m.sale_price BETWEEN 1 AND 4 ;
#结果是(>=5且<=15) 或 (>=1且<=4)
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND m.sale_price <= 15 AND m.sale_price IS NOT NULL;
#结果是非NULL且>= 5且<= 15
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND m.sale_price <= 15 AND m.sale_price IS NULL;
#结果是 NULL且>= 5且<= 15
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND m.sale_price <= 15 OR m.sale_price IS NULL;
#结果 (>=5且<=15) 或 (NULL)
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND m.sale_price <= 15 AND m.prod_name LIKE '薯_';
#结果 (>=5且<=15) 且 prod_name以薯字开头
Q:那么同时用AND、OR的时候,优先级是怎样的?
A:不明确就用括号分开。
SELECT * FROM milk_tea AS m WHERE m.sale_price >= 5 AND (m.sale_price <= 15 OR m.prod_name LIKE '奶%');
SELECT * FROM milk_tea AS m WHERE (m.sale_price >= 5 AND m.sale_price <= 15 ) OR m.prod_name LIKE '奶%';
hai…这个例子两个结果是一样的,就是展示以下括号怎么用…
7. 取值限制IN
使用场景:明确而不连续的取值(过滤值明确;但不是连续范围)
写法:WHERE [列名] IN (值1,值2,…)
(比如>=5是连续的值)
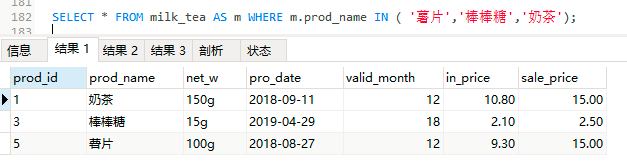
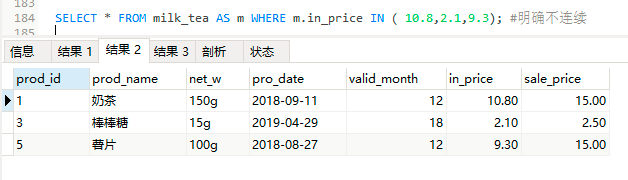
SELECT * FROM milk_tea AS m WHERE m.prod_name IN ( '薯片','棒棒糖','奶茶');
SELECT * FROM milk_tea AS m WHERE m.in_price IN ( 10.8,2.1,9.3); #明确不连续
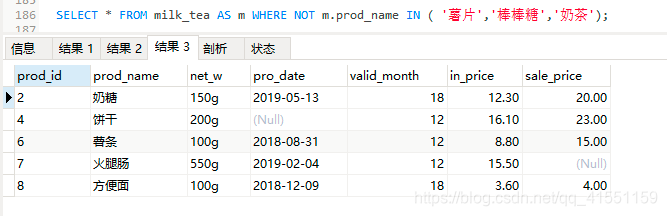
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name IN ( '薯片','棒棒糖','奶茶');
8. 否定条件NOT
使用场景:
否定一个或多个过滤条件;
不能单独使用;
类似补集的概念
写法:WHERE NOT [条件1]
注:NOT是放在条件前!而且只否定一个条件,而且只否定紧跟着的那个条件。
区分位置:
(1) WHERE [列] IS NOT NULL
(2) WHERE NOT [条件]
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name = '奶茶' OR NOT m.prod_name = '薯片' OR NOT m.prod_name = '棒棒糖' ;#1
#不要奶茶 或 不要薯片 或 不要棒棒糖,‘或’就是并集的概念
#即奶茶的补集 并 薯片的补集 并 棒棒糖的补集
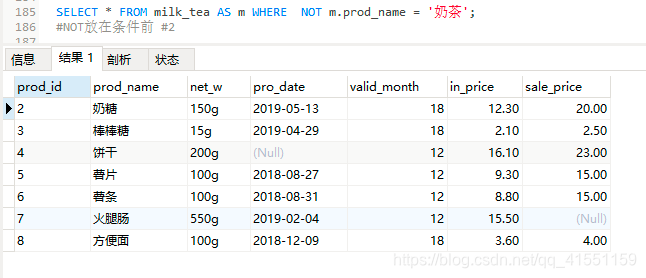
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name = '奶茶';
#NOT放在条件前 #2
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name IN ( '薯片','棒棒糖','奶茶'); #结果与1一样
#不要奶茶、棒棒糖、薯片
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name = '奶茶' OR m.prod_name = '薯片' OR m.prod_name = '棒棒糖' ;
#NOT放在条件前,只否定一个条件,而且只否定紧跟着的那个条件
#不要prod_name=奶茶 或 prod_name是薯片 或 prod_name=棒棒糖
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name = '奶茶' OR NOT m.prod_name = '薯片' OR m.prod_name = '棒棒糖' ;
#不要奶茶 或 不要薯片 或 要棒棒糖,‘或’就是并集的概念
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name = '奶茶' AND NOT m.prod_name = '薯片';
#不要奶茶 和 不要薯片
SELECT * FROM milk_tea AS m WHERE NOT m.prod_name = '奶茶' AND m.prod_name = '薯片'; #只有薯片
#不要奶茶 和 要薯片
结果1:
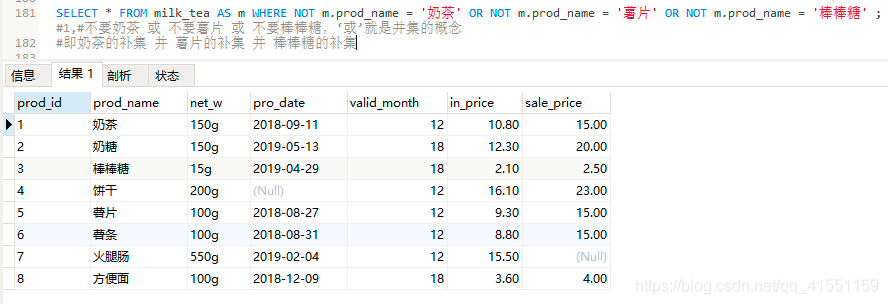 Q:为什么结果中还是有奶茶棒棒糖薯片?
Q:为什么结果中还是有奶茶棒棒糖薯片?
A:
(1)不要奶茶 或 不要薯片 或 不要棒棒糖,即奶茶的补集 并 薯片的补集 并 棒棒糖的补集
(2)奶茶的补集是2,3,4,5,6,7,8
棒棒糖的补集是1,2,4,5,6,7,8
薯片的补集是1,2,3,4,6,7,8
它们的并集就是1,2,3,4,5,6,7,8
结果2:
 结果3:
结果3:
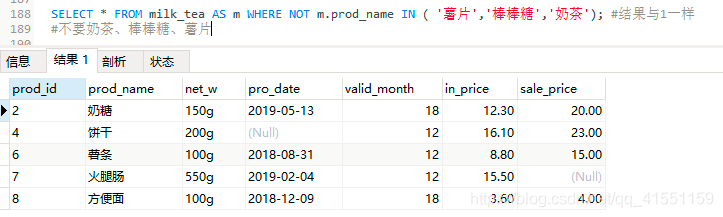 结果4:
结果4:
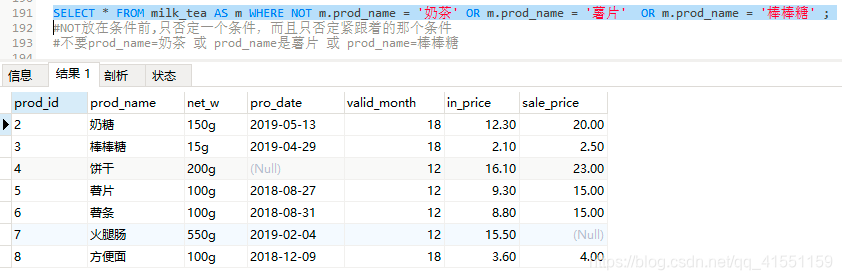 结果5:
结果5:
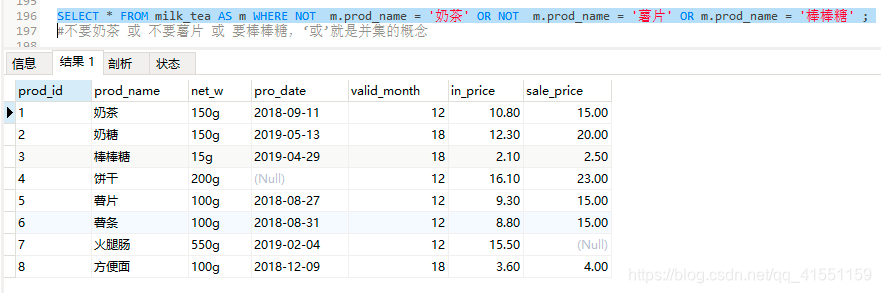 即奶茶的补集 并 薯片的补集 并 棒棒糖
即奶茶的补集 并 薯片的补集 并 棒棒糖
结果6:
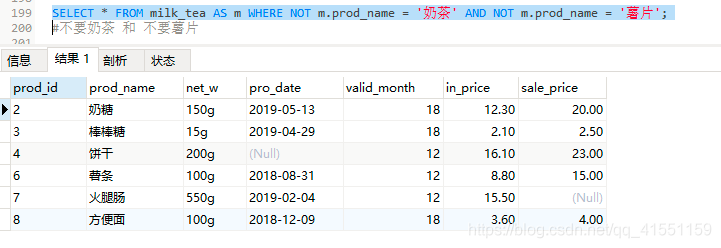 奶茶的补集 交 薯片的补集
奶茶的补集 交 薯片的补集
结果7:
 奶茶的补集 交 薯片(AND是求交集的意思)
奶茶的补集 交 薯片(AND是求交集的意思)

















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









