







 这篇博客介绍了机器学习中的关键概念,包括损失函数,如0-1损失,用于衡量分类错误;贝叶斯分类器作为最优分类器,其在0-1损失下的分类误差最小;以及决策边界的概念,它定义了不同类别间的划分。此外,还提及了逻辑回归在分类问题中的应用,通过sigmoid函数限制预测值,并用极大似然估计来学习模型参数。
这篇博客介绍了机器学习中的关键概念,包括损失函数,如0-1损失,用于衡量分类错误;贝叶斯分类器作为最优分类器,其在0-1损失下的分类误差最小;以及决策边界的概念,它定义了不同类别间的划分。此外,还提及了逻辑回归在分类问题中的应用,通过sigmoid函数限制预测值,并用极大似然估计来学习模型参数。
损失函数
在分类中,使用一个 C × C C\times C C×C 的损失矩阵 L L L来表达损失函数,其中, C C C 指类别数。损失矩阵中的每个元素 L k l = L ( k , l ) L_{kl}=L(k,l) Lkl=L(k,l) 指将实际类别属于 k k k,但是将其分类到 l l l 的损失。常用的损失函数为 0 − 1 0-1 0−1 损失函,其中 L k l = { 1 , k ≠ l 0 , k = l \displaystyle L_{kl}=\left\{ \begin{aligned} 1, && k\neq l \\ 0, && k=l \end{aligned} \right. Lkl={1,0,k=lk=l
其中,一个单位损失发生在错误分类的情况下,即 L ( Y , G ( X ) ) = I ( Y ≠ G ( X ) ) = { 1 , Y ≠ G ( X ) 0 , Y = G ( X ) \displaystyle L(Y,G(X))=I(Y\neq G(X))=\left\{ \begin{aligned} 1, && Y\neq G(X) \\ 0, && Y= G(X) \end{aligned} \right. L(Y,G(X))=I(Y=G(X))={1,0,Y=G(X)Y=G(X)
而分类器 G G G 的预测损失/错误率是 E r r ( G ) = E [ L ( Y , G ( X ) ) ] = A v e r a g e { L ( y ( i ) , G ( x ( i ) ) ) , ∀ ( y ( i ) , x ( i ) ) } Err(G)=\mathrm E[L(Y,G(X))]=Average\{L(y^{(i)},G(\mathbf x^{(i)})),\forall (y^{(i)},\mathbf x^{(i)})\} Err(G)=E[L(Y,G(X))]=Average{L(y(i),G(x(i))),∀(y(i),x(i))}。最终目标是找到一个使得预测错误率最小的分类器。
贝叶斯分类器(Bayes classifier)
当给定 X = x X=\mathbf x X=x 时, Y = c Y=c Y=c 的条件概率为 p c ( x ) = P ( Y = c ∣ X = x ) \displaystyle p_c(\mathbf x)=P(Y=c|X=\mathbf x) pc(x)=P(Y=c∣X=x),其中 c = 1 , ⋯ , C c=1,\cdots,C c=1,⋯,C。
将样本 x \mathbf x x 分类到 c c c 的条件是: p c ( x ) ≥ p j ( x ) , ∀ j = 1 , ⋯ , C p_c(\mathbf x)\ge p_j(\mathbf x), \forall j=1,\cdots,C pc(x)≥pj(x),∀j=1,⋯,C。
贝叶斯分类器是 0-1损失下的最优分类器,相较于其他分类器有着最小的分类误差。
决策边界
考虑类别
k
k
k 和
j
j
j,集合
{
x
:
p
k
(
x
)
=
p
j
(
x
)
}
\{\mathbf x:p_k(\mathbf x)=p_j(\mathbf x)\}
{x:pk(x)=pj(x)} 则为类别
k
k
k 和
j
j
j 之间的 决策边界(decision boundary)。
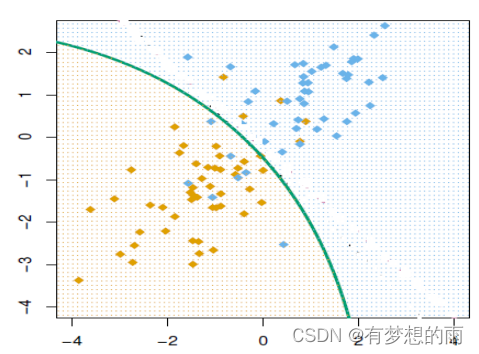
给定训练集
{
(
y
(
i
)
,
x
(
i
)
)
,
i
=
1
,
⋯
,
n
}
\{(y^{(i)},\mathbf x^{(i)}),i=1,\cdots,n\}
{(y(i),x(i)),i=1,⋯,n},分类器
G
G
G 的 经验误差(empirical error) 为
e
r
r
‾
(
G
)
=
1
n
∑
i
I
(
y
(
i
)
≠
G
(
x
(
i
)
)
)
\displaystyle \overline{err}(G)=\frac{1}{n}\sum_iI(y^{(i)}\neq G(\mathbf x^{(i)}))
err(G)=n1i∑I(y(i)=G(x(i)))
逻辑回归(Logistic Regression)
在解决分类问题时,可以忽略 y ( i ) y^{(i)} y(i) 是离散值的事实,然后采用线性回归算法来预测当给定 x \mathbf x x 时 y 的值。但是,这样直接构造的方法效果很差。因此,对 0-1分类来说,需要将预测值 h θ ( x ) h_\theta(x) hθ(x) 限制到 [ 0 , 1 ] [0,1] [0,1] 之间,使得预测值有意义。
目标函数及sigmoid函数
h
θ
(
z
)
=
1
1
+
e
−
z
=
e
z
1
+
e
z
\displaystyle h_\theta(z)=\frac{1}{1+e^{-z}}=\frac{e^z}{1+e^z}
hθ(z)=1+e−z1=1+ezez
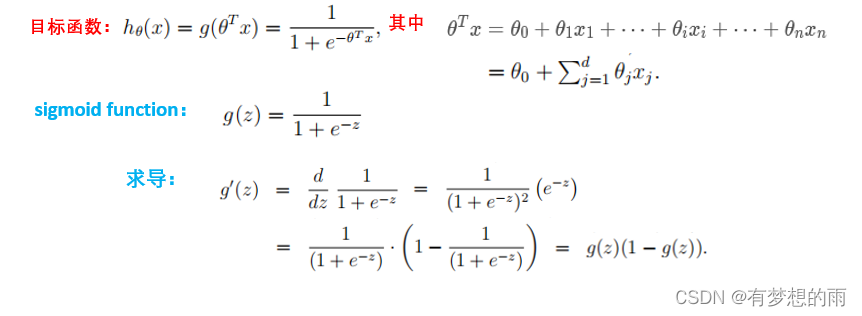
模型参数学习
将预测值
h
θ
(
x
)
h_\theta(x)
hθ(x) 限制到
[
0
,
1
]
[0,1]
[0,1] 之间,因此,以概率视角来看问题,使用 MLE(极大似然估计,maximum likelihood estimator) 来求解。

θ j : = θ j + α ⋅ ∑ i = 1 n ( y ( i ) − h θ ( x ( i ) ) ) ⋅ x j ( i ) \displaystyle \theta_j:=\theta_j+\alpha\cdot\sum^n_{i=1}(y^{(i)}-h_\theta(x^{(i)}))\cdot x^{(i)}_j θj:=θj+α⋅i=1∑n(y(i)−hθ(x(i)))⋅xj(i)

















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









