




 本文详细总结了Mybatis的核心知识点,包括增删改查的实现、Mapper动态代理、SqlMapConfig配置、动态Sql及关联查询。同时,分析了#{}与${}的区别、查询数量的选择及resultType与resultMap的应用。此外,还梳理了Mybatis整合SSM的关键步骤,以及在使用过程中可能遇到的易错点。
本文详细总结了Mybatis的核心知识点,包括增删改查的实现、Mapper动态代理、SqlMapConfig配置、动态Sql及关联查询。同时,分析了#{}与${}的区别、查询数量的选择及resultType与resultMap的应用。此外,还梳理了Mybatis整合SSM的关键步骤,以及在使用过程中可能遇到的易错点。
### 知识点总结 ###
1. 增删改查自主实现
查
- 普通代码模板如下
@Test public void test1() throws IOException { InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml"); SqlSessionFactory f = new SqlSessionFactoryBuilder().build(in); SqlSession session = f.openSession(); User user = session.selectOne("user.findUserById", 10); System.out.println(user); }<mapper namespace="user"> <select id="findUserById" parameterType="Integer" resultType="cn.neu.yealon.pojo.User"> select * from user where id = #{v} </select> </mapper>增
- 类的属性可以不写成对象.属性,直接写属性也可。
<insert id="insertNewUser" parameterType="cn.neu.yealon.pojo.User"> INSERT INTO `user`(username,birthday,sex,address) VALUES (#{username},#{birthday},#{sex},#{address}) </insert> - 同查询不一样,如果不提交事务,“增”在数据库中并没有效果
int num = sqlSession.insert("user.insertNewUser",user); sqlSession.commit(); sqlSession.close(); - 获取插入后的元素的自增id,需要先在 <select> 标签中插入以下代码。它表示把新的id存到对象的id属性中。数据库若为mysql,则order="AFTER";若为oracle,则order="BEFORE"。
<selectKey keyColumn="id" keyProperty="id" order="AFTER" resultType="int"> SELECT LAST_INSERT_ID() </selectKey>
删
- 上面的都看完了,这里就没啥特别的了
<delete id="deleteUserById" parameterType="int"> delete from user where id=#{id} </delete>改
- 同样,上面的都看完了,这里就没啥特别的了
<update id="updateUserById" parameterType="cn.neu.yealon.pojo.User"> UPDATE `user` SET username = #{username} WHERE id = #{id} </update>
2. Mapper的动态代理规范
- 方法名 == 语句的id
- 传入参数类型一致
- 返回值类型一致
- 命名空间绑定接口(<mapper namespace="">这里的名称空间应为Dao接口的全路径)
例子:
UserDao:(只需要写接口,不需要写实现类)
public interface UserDao
{
/**
* 根据id返回用户
*
* @param id
* @return
*/
User queryUserById(int id);
}
mapper/UserMapper.xml:
<mapper namespace="cn.neu.yealon.mapper.UserDao">
<select id="queryUserById" parameterType="int"
resultType="cn.neu.yealon.pojo.User">
select * from user where id = #{id}
</select>
</mapper>加载配置文件,在SqlMapConfig.xml中增添:
<mappers>
<mapper resource="mapper/UserMapper.xml" />
</mappers>
test:
@Test
public void testQueryUserById()
{
SqlSession sqlSession = this.sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.queryUserById(1);
System.out.println(user);
sqlSession.close();
}
3. SqlMapConfig.xml中,配置在 <configuration> 下的其他标签
properties
<properties resource="db.properties">
<!-- db.properties 配置的值在键相同的情况下优先于下面配置的值 -->
<!-- 注意:如果后面标签用到这个属性,此属性必须写前面 -->
<property name="jdbc.username" value="admin" />
</properties>
typeAliases(类型别名)
<typeAliases>
<!-- 单独定义 -->
<typeAlias alias="user" type="cn.neu.yealon.pojo.User" />
<!-- 批量定义:整个包下的类的别名都为类名,大小写不敏感 -->
<package name="cn.neu.yealon.pojo" />
</typeAliases>
4. 动态Sql
一种常用写法(不用where就要在最前面加上1=1):
<select id="queryUserByWhere" parameterType="user" resultType="user">
SELECT * FROM `user`
<where>
<if test="username != null and username != ''">
AND username LIKE '%${username}%'
</if>
<if test="sex != null">
AND sex = #{sex}
</if>
</where>
</select>
sql片段,可修改上一个代码示例为:
<sql id="userSelector">
SELECT * FROM `user`
</sql>
<select id="queryUserByWhere" parameterType="user" resultType="user">
<include refid="userSelector" />
<where>
<if test="username != null and username != ''">
AND username LIKE '%${username}%'
</if>
<if test="sex != null">
AND sex = #{sex}
</if>
</where>
</select>foreach:
<select id="queryUserByIds" parameterType="queryVo" resultType="user">
SELECT * FROM `user`
<where>
<!-- collection:遍历的集合。传入单个对象,则写其属性名;是数组,则写作"array",是数据结构如List<Integer>,则写作"list"-->
<foreach collection="ids" item="item" open="id IN (" close=")"
separator=",">
#{item}
</foreach>
</where>
</select>
@Test
public void testQueryUserByIds()
{
SqlSession sqlSession = this.sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
QueryVo queryVo = new QueryVo();
List<Integer> ids = new ArrayList<>();
ids.add(1);
ids.add(10);
ids.add(24);
queryVo.setIds(ids);
List<User> list = userMapper.queryUserByIds(queryVo);
for (User u : list)
{
System.out.println(u);
}
sqlSession.close();
}
5. 关联查询
5.1 实体类设计问题
关联查询在一对多时,返回类型需要有一个实体类来接收。 itcast 给出了两种解决方式:【引用2】
第一种:更改pojo类。由于如 User 和 Order 是一对多的关系,实体类就应该设计成如下图:
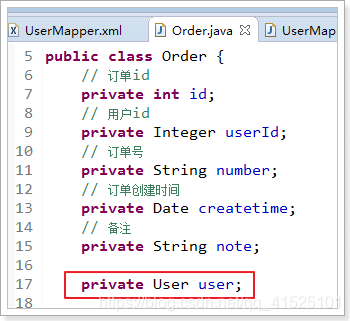
其他配置文件等我就不贴代码了,因为从软件工程的角度来说,尽可能减少代码的更改是一大原则,万一后续每个用户又持有多个银行卡等,又增加其他关联对象时,频繁变更实体类的属性,会使得其本身的方法(getter、setter、toString等),以及相关类(Dao、DaoImpl等)不断需要更改。我认为其提出的第二种方法更具有实用性,个人理由如下:
1) 继承原有实体类。由于查询出的也不是User的全部信息(原User的属性数量远远多出两条),因此此处只筛选出两个我们需要的属性。但是如果仍然从需求变更的角度来讲,当然此处的属性和User类的属性也形成了冗余,一旦有冗余就必然有不利于灵活性(毕竟面向对象本身最大的优势就是灵活适应需求变更,万一后续用户地址相关信息越来越复杂,需要建立地址类,此处就又需要重写),从这个角度来讲,其内部应该存User。但是毕竟就像算法的时间复杂度和空间复杂度总是不能兼得一样,此处考虑到取出整个User性能开销和只取出两个字段相差过大,因此采用重写两个属性的方式。当然如果考虑的更细致一些,此处继承如果更改为持有(组合模式)更佳。
public class OrderUser extends Order
{
private String userName;
private String address;
}2) 在UserMapper.xml添加sql
<select id="queryOrderUser" resultType="orderUser">
SELECT o.id,o.user_id,userId,o.number,o.createtime,o.note,u.username,u.address
FROM `order` o LEFT JOIN `user` u
ON o.user_id = u.id
</select>
3) 接口添加方法
public List<OrderUser> queryOrderUser();4) 测试代码如下
@Test
public void testQueryOrderUser()
{
SqlSession sqlSession = this.sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<OrderUser> list = userMapper.queryOrderUser();
for (OrderUser ou : list)
{
System.out.println(ou);
}
sqlSession.close();
}
5. Mybatis整合SSM
见【相关2】(本博客最后一行)
### 易错点总结 ###
1. #{} 和 ${} 的区别
- #{} 表示占位符,${} 表示字符串。如 ...where name like 'abc${value}%'(模糊查询),亦或写作...where name = "%"#{val}"%"(防sql语句注入);再如...where name = #{val}。
- #{} 中可以随便写,${} 里面只能写value。
2.查询数量
count(*)和count(1) 都含null,但 count(字段) 忽略null的项。【引用1】
3. resultType和resultMap
- 前者在对象属性和表的字段名称一样时使用;后者在这两者不一样时使用
相关链接
【引用1】mysql使用1=1和count(1),count(*)等的区别
【引用2】文章一些主要关键点学习自其他网站,附上各自官网链接,其java教学的确质量不低~ 传智播客 黑马程序员
【相关1】面试常问之mybatis和hibernate的区别
【相关2】SSM项目整合【含最新版所有常用的相关jar包(maven依赖),以及所有基本配置文件】

















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









