






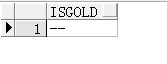
把’- -'赋值给isgold
select '- -' isgold from dual;
dynamic
<dynamic prepend=" ">
当需要使用根据传入参数的值来动态组装SQL时,可以使用dynamic标签。
dynamic元素可以包含多个条件比较元素,并且按照条件比较元素的表述对参数值进行比较,来组装动态SQL。
这里主要的条件比较元素包含isGreaterThan、isNotNull、isEmpty……
dynamic元素和条件比较元素,都是组成动态SQL的一部分,其中的prepend属性根据实际情况的需要辅助的组装动态SQL。
dynamic要覆盖第一个为“真”的条件比较元素的prepend属性,首先需要检测该tag的prepend是否可用(tag.isPrependAvailable()),如果不可用的话,即便该比较条件为“真”,则不会覆盖,只是单独的添加该比较条件元素下的SQL
public boolean isPrependAvailable() {
return prependAttr != null && prependAttr.length() > 0;
}
prepend可用的前提是prepend属性值已经设置,并且长度>0。
<![CDATA[]]>
在xml中用<![CDATA[<>]]>表示"<>"
在XML中,需要转义的字符有:
(1)& &
(2)< <
(3)> >
(4)" "
(5)' '
为了方便起见,使用<![CDATA[]]>来包含不被xml解析器解析的内容。但要注意的是:
(1) 此部分不能再包含”]]>”;
(2) 不允许嵌套使用;
(3)”]]>”这部分不能包含空格或者换行。
isNotNull和isNotEmpty
null不指向任何对象,相当于没有任何值;而’‘代表一个长度为0的字符串
null不分配内存空间;而’'会分配内存空间
isNotNull 参数不为Null时返回true,
isNotEmpty 参数既不为Null也不为空时返回true,
isNotEmpty 比 isNotNull 多了一个非空的判断。
isEqual 相当于String 里的equal方法
property:指定比较属性的名称,
compareValue:表示要比较的参数,
prepend:表示追加比较条件
“||”代表连接两个字符串
“+”代表作相加运算
row_number() over(partition by 分组列 order by 排序列)
分组排序:每一个分组后的组组内排序
count(*) over(partition by 分组列 order by 排序列)
当在over()中带order by xxx时,如果没分组,则相同xxx的记录的count()over()值都一样,为最大的那个值;如果分组,则相同组相同xxx的count()over()值一样,也为最大的那个值。
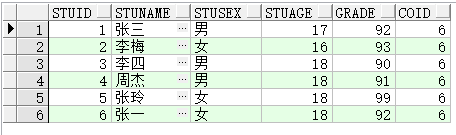
- count(*) over()
求总计数
select stuId,stuName,stuSex,stuAge,grade,count(*) over() coID from BIZ_FJTEST order by stuId;
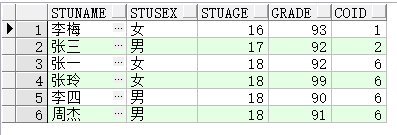
- count(*) over(order by xxx)
递加求计数(当xxx有一样的时,值都为相同xxx的最下面那一行数据的顺序)
select stuName,stuSex,stuAge,grade,count(*) over(order by stuAge) coID from BIZ_FJTEST;
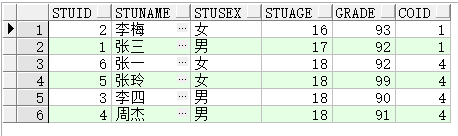
- count(*) over(partition by xxx)
分组求计数,
select stuId,stuName,stuSex,stuAge,grade,count(*) over(partition by stuAge) coID from BIZ_FJTEST;
- count(*) over(partition by xxx order by yyy)
分组递加求计数
select stuId,stuName,stuSex,stuAge,grade,count(*) over(partition by stuSex order by grade) coID from BIZ_FJTEST;
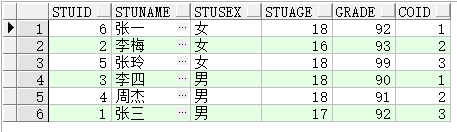
select stuId,stuName,stuSex,stuAge,grade,count(*) over(partition by stuSex order by stuAge) coID from BIZ_FJTEST;
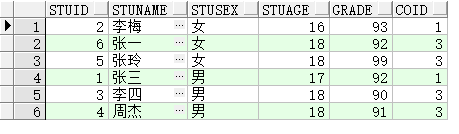
row_number()over()与count(*)over()区别:同一组内不会存在重复的row_number()over()值,而可能存在一样的count(*)over()值
instr函数(字符查找)
注意!!!从1开始而不是从0开始。先找到这个字符,然后从左开始往右算这个字符排在第几位。起始位置为负数时,这个字符从右边往左找,-1则从最右边的字符开始。
格式一:instr( string1, string2 ) / instr(源字符串, 目标字符串)
格式二:instr( string1, string2 [, start_position [, nth_appearance ] ] ) / instr(源字符串, 目标字符串, 起始位置, 匹配序号)
解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检索第nth_appearance(几)次出现string2。
select instr('helloworld','l') from dual; 3 第一次出现"l"的位置 和('helloworld','l',1,1)效果一样
select instr('helloworld','lo') from dual; 4 第一次出现"lo"的位置
select instr('helloworld','l',2,2) from dual; 4 在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置
select instr('helloworld','l',-2,2) from dual; 4 在"helloworld"的倒数第2(l)号位置开始,往回查找第二次出现的“l”的位置
round函数(四舍五入)
传回一个数值,该数值是按照指定的小数位元数进行四舍五入运算的结果
round(number,decimal_places)
number:待处理的数值
decimal_places:四舍五入 , 小数取几位 ( 预设为 0 )
select round(123.456, 0) from dual; 返回123
select round(123.456, 1) from dual; 返回123.5
select round(-123.456, 2) from dual; 返回-123.46
ceil和floor函数(取整)
ceil(n) 取大于等于数值n的最小整数
floor(n)取小于等于数值n的最大整数
select ceil(1.5) a from dual; 返回2
select ceil(-1.5) a from dual; 返回-1
select floor(1.5) a from dual; 返回1
select floor(-1.5) a from dual; 返回-2
trunc函数(截取)
用于截取时间或者数值,返回指定的值
1)截取数值
trunc(number,decimals)
number :待做截取处理的数值
decimals :指明需保留小数点后面的位数。可选项,忽略它或者为0则截去所有的小数部分,保留整数部分。
trunc就是处理数字的显示位数,如果decimals为负数,就去掉小数部分,处理整数部分,处理完为0,-1就是个位为0,-2就是十位和个位为0,如果超过了或等于整数部分长度,则整个数字为0;如果decimals为正数,就处理小数部分,截取n位小数,超过了小数位长度仍是原值。
select trunc(12.34) from dual; 12
select trunc(12.34,0) from dual; 12
select trunc(12.34,-1) from dual; 10
select trunc(12.34,-2) from dual; 0
select trunc(12.34,-3) from dual; 0
select trunc(12.34,1) from dual; 12.3
select trunc(12.34,2) from dual; 12.34
select trunc(12.34,3) from dual; 12.34
2)截取时间
trunc(date,format)
date:日期格式的值
format:日期格式 如’mm’,‘yyyy’等将date从指定日期格式截取(没有’ss’,trunc函数没有秒的精确)
| 无参 | yyyy | yy | mm | dd | d | hh | mi |
|---|---|---|---|---|---|---|---|
| 当前date的年月日 | 当年第一天 | 当年第一天 | 当月第一天 | 当前年月日 | 当前星期的第一天(星期日) | 当前日期截取到小时,分和秒补00 | 当前日期截取到分,秒补00 |
select trunc(sysdate) from dual; 2021/7/30
select trunc(sysdate,'yyyy') from dual; 2021/1/1
select trunc(sysdate,'yy') from dual; 2021/1/1
select trunc(sysdate,'mm') from dual; 2021/7/1
select trunc(sysdate,'dd') from dual; 2021/7/30
select trunc(sysdate,'d') from dual; 2021/7/25
select trunc(sysdate,'hh') from dual; 2021/7/30 13:00:00
select trunc(sysdate,'mi') from dual; 2021/7/30 13:50:00
select trunc(to_date('2018-02-01 1:00:00','YYYY-MM-DD HH:MI:SS')) from dual; 2018/2/1
select trunc(to_date('2018-02-01 1:00:00','YYYY-MM-DD HH:MI:SS'),'yyyy') from dual; 2018/1/1
select trunc(to_date('2018-02-01 1:00:00','YYYY-MM-DD HH:MI:SS'),'mm') from dual; 2018/2/1
select trunc(to_date('2018-02-01 1:00:00','YYYY-MM-DD HH:MI:SS'),'dd') from dual; 2018/2/1
select trunc(to_date('2018-02-01 1:00:00','YYYY-MM-DD HH:MI:SS'),'d') from dual; 2018/1/28
select trunc(to_date('2018-02-01 1:12:12','YYYY-MM-DD HH:MI:SS'),'hh') from dual; 2018/2/1 1:00:00
select trunc(to_date('2018-02-01 1:12:12','YYYY-MM-DD HH:MI:SS'),'mi') from dual; 2018/2/1 1:12:00
decode():相当于if/else if语句
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
该函数的含义如下:
IF 条件=值1 THEN
RETURN(返回值1)
ELSIF 条件=值2 THEN
RETURN(返回值2)
…
ELSIF 条件=值n THEN
RETURN(返回值n)
ELSE
RETURN(缺省值)
END IF
REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
string:需要进行正则处理的字符串
pattern:进行匹配的正则表达式
position:起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0
occurrence:获取第几个分割出来的组(分割后最初的字符串会按分割的顺序排列成组)
modifier:模式(‘i’不区分大小写进行检索;‘c’区分大小写进行检索。默认为’c’)针对的是正则表达式里字符大小写的匹配
1、select REGEXP_SUBSTR(‘11a22A33a’,’[^A]+’,1,1,‘i’) as str from dual;
结果:11
分析:正则表达式是以A为标识进行分割,而’i’标识不区分大小写,所以结果是11,而不是11a22
2、select REGEXP_SUBSTR(‘11a22A33a’,’[^A]+’,1,1,‘c’) as str from dual;
结果:11a22
分析:正则表达式是以A为标识进行分割,而’c’标识区分大小写,所以结果是11a22,而不是11
REGEXP_REPLACE(source, pattern, replace_string, occurrence)
● source: string类型,要替换的原始字符串。
● pattern: string类型常量,要匹配的正则模式,pattern为空串时抛异常。
● replace_string:string,将匹配的pattern替换成的字符串。
● occurrence: bigint类型常量,必须大于等于0,
大于0:表示将第几次匹配替换成replace_string,
等于0:表示替换掉所有的匹配子串。
其它类型或小于0抛异常。
select regexp_replace('01234abcde56789','[0-9]','#')FROM dual; 用'#'替换字符串中的所有数字
select regexp_replace('01234abcde56789','[09]','#')FROM dual; 用'#'替换字符串中的数字0和9
select regexp_replace('abcDEfg123456ABC','[a-z0-9]','',4) from dual; 遇到非小写字母或者数字跳过,从匹配到的第4个值开始替换,替换为''
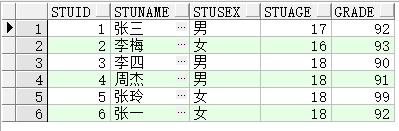
Union:对两个结果集进行并集操作(合并结果),不包括重复行,同时进行默认规则的排序;
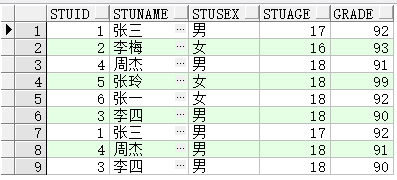
Union All:对两个结果集进行并集操作(合并结果),包括重复行,不进行排序;
select * from student union all
select * from student where stuSex='男';
select * from student union
select * from student where stuSex='男';
NVL函数:从两个表达式返回一个非 null 值
NVL(expression1, expression2)
如果 expression1 的计算结果为 null 值,则 NVL( ) 返回 expression2。如果 expression1 的计算结果不是 null 值,则返回 expression1。expression1 和 expression2 可以是任意一种数据类型。如果 expression1 与 expression2 的结果皆为 null 值,则 NVL( ) 返回 NULL。
LPAD:从左边对字符串使用指定的字符进行填充
lpad( string, padded_length, [ pad_string ] )
string:准备被填充的字符串
padded_length:填充之后的字符串长度,也就是该函数返回的字符串长度,如果这个数量比原字符串的长度要短,lpad函数将会把字符串截取成从左到右的n个字符
pad_string:填充字符串,是个可选参数,这个字符串是要粘贴到string的左边,如果这个参数未写,lpad函数将会在string的左边粘贴空格
select lpad('Sibal',10,'abc') from dual; "abcabSibal"
select lpad('Sibal',7,'abc') from dual; "abSibal"
select lpad('Sibal',4,'abc') from dual; "Siba"
select lpad('Sibal',10) from dual; " Sibal" 5个空格
to_date,to_char
to_date:将具有固定格式的字符串类型的数据转化为相对应的Date类型数据
to_char:将数值型或者日期型转化为字符型
使用方法
to_date(“需要转换的字符串”,“日期格式”) 前后要匹配
参数详解:日期格式
元素连接格式
元素使用“-”连接,如YYYY-MM-DD (2019-05-28)
元素使用“:”连接,如YYYY-MM-DD HH:MI:SS (2019-05-28 11:25:36)
元素使用“/”连接,如YYYY/MM/DD HH:MI:SS (2019/05/28 11:25:36)
组成元素(结合to_char使用)
YYYY:四位表示的年份
YYY,YY,Y:年份的最后三位、两位或一位
MM:01~12的月份编号
MONTH:九个字符表示的月份,右边用空格填补
MON:三位字符的月份缩写
D:星期中的第几天
DD:月份中的第几天
DDD:年份中的第几天
DAY:当周第几天全写,右边用空格补齐
DY:当周第几天缩写
W:当月中的第几周
WW:一年中的第几周
CC:世纪
Q:季度
HH,HH12:一天中的第几个小时,12进制表示法
HH24:一天中的第几个小时,取值为00~23
MI:一小时中的分钟
SS:一分钟中的秒
SSSS:从午夜开始过去的秒数
select sysdate,sysdate - interval '7' MINUTE from dual; 当前时间减去7分钟的时间
select sysdate - interval '7' hour from dual; 当前时间减去7小时的时间
select sysdate - interval '7' day from dual; 当前时间减去7天的时间
select sysdate,sysdate - interval '7' month from dual; 当前时间减去7月的时间
select sysdate,sysdate - interval '7' year from dual; 当前时间减去7年的时间
select sysdate,sysdate - 8*interval '2' hour from dual; 当前时间减去16小时的时间
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual; 给出的时间是周几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual; 给出的时间是周几
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual; 两个日期间的天数
to_char(to_date('2021-07-30','yyyy-mm-dd'),'cc') 21 当前日期所在的世纪
to_char(to_date('2021-07-30','yyyy-mm-dd'),'yy') 21 当前日期所在的年份后两位
to_char(to_date('2021-07-30','yyyy-mm-dd'),'month') 7月 当前日期所在的月份
to_char(to_date('2021-07-30','yyyy-mm-dd'),'ddd') 211 当前日期所在的年份中第几天
to_char(to_date('2021-07-30','yyyy-mm-dd'),'ww') 31 当前日期所在的年份中第几周
to_char(to_date('2021-07-30 16:12:15','yyyy-mm-dd hh24:mi:ss'),'HH24') 16 当前时间所在天中一天的第几个小时
dbms_lob.substr(clob_column)
● clob_column: clob类型
针对ORA-00932: inconsistent datatypes: expected - got CLOB
进行clob转字符串操作
select id,dbms_lob.substr(attributes) from ecas_message where rownum <= 8;
MINUS
●A minus B就意味着将结果集A去除结果集B中所包含的所有记录后的结果,即在A中存在,而在B中不存在的记录。即差集B-A,A minus B,对于集合A、B,即集合{x∣x∈A,且x∉B}。
●minus是按列进行比较的,所以A能够minus B的前提条件是结果集A和结果集B需要有相同的列数,且相同列索引的列具有相同的数据类型。
●oracle会对minus后的结果集进行去重,即如果A中原本多条相同的记录数在进行A minus B后将会只剩一条对应的记录。
select id,dbms_lob.substr(attributes) from ecas_message where rownum <= 8
minus
select id,dbms_lob.substr(attributes) from ecas_message where rownum < 2;
INTERSECT
●和 UNION 指令类似,但UNION是并集,A∪B,INTERSECT是交集,A∩B。
●使用intersect的限制条件如下:1、所有查询中的列数和列的顺序必须相同。2、比较的两个查询结果集中的列数据类型可以不同但必须兼容。3、比较的两个查询结果集中不能包含不可比较的数据类型(xml、text、ntext、image 或非二进制 CLR 用户定义类型)的列。4、返回的结果集的列名与操作数左侧的查询返回的列名相同。ORDER BY 子句中的列名或别名必须引用左侧查询返回的列名。5、不能与 COMPUTE 和 COMPUTE BY 子句一起使用。6、通过比较行来确定非重复值时,两个 NULL 值被视为相等。
select id,content from (select id,content,rownum as num from ecas_message) where num >= 2
intersect
select id,content from ecas_message where rownum <= 8;
rownum
●分页查询时使用,例如返回表中的前n条记录或者是中间的几条记录
●rownum需要注意的问题
[1] rownum不支持以下方式的查询
a: select * from area where rownum > 2;
b: select * from area where rownum = n; --where n is a integer number lager than 1
注:rownum只支持select * from area where rownum =1的查询
因为rownum是根据查询的结果集来对记录进行编号,所以当你查询rownum大于2的记录时会得到一个空的结果集。因为当oracle查询得到第1条记录时,发现rownum为1不满足条件,然后就继续查询第2条记录,但此时第2条记录又被编号为1(也即rownum变为1),所以查询得到的始终是rownum=1,因此无法满足约束,最终查询的结果集为空。
所以rownum不支持使用>,>=,=(除了1),between...and,不会提示语法错误,但查询不出数据
[2] rownum的排序查询问题
Rownum的排序查询是根据表中数据的初始顺序来进行的。
例如:select * from area where rownum <= 8 order by district;只对area表中的前8条记录进行排序。那么,如果我要取表中的前8条记录并且要求是全表有序,那怎么办呢?还是老办法,使用子查询。我们可以使用以下语句得到:
select * from (select * from area order by district) where rownum <= 8;


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









