






现象:
lora微调过程中出现loss持续为0
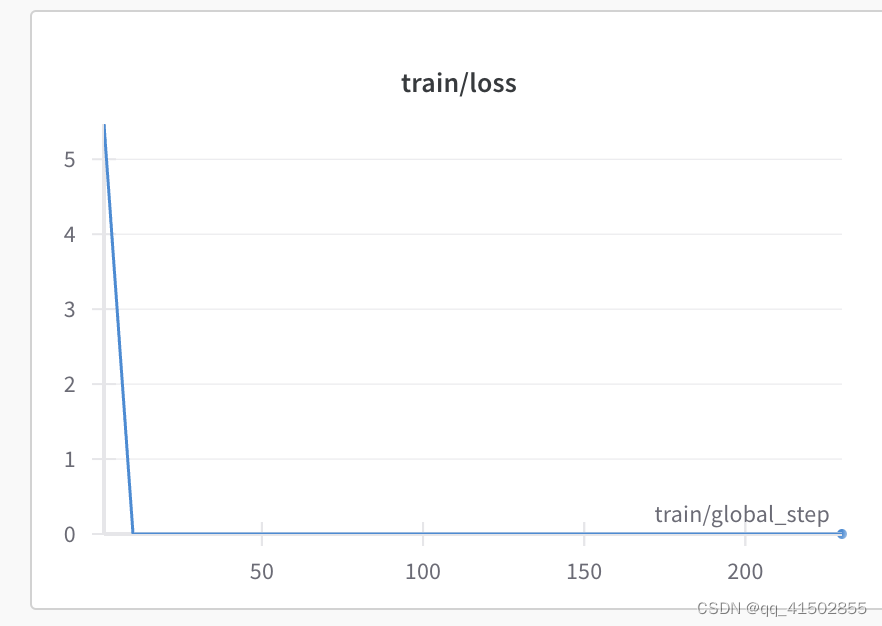
解决方案:
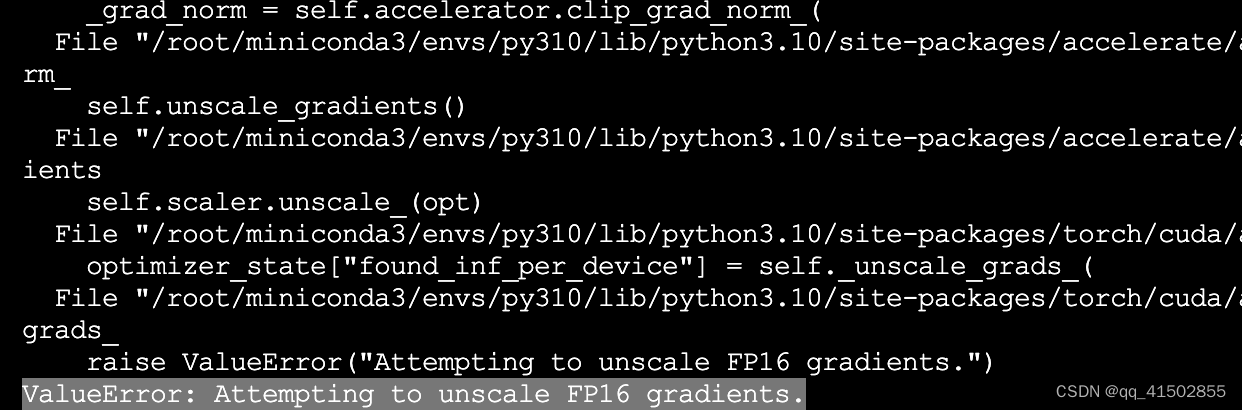
步骤1,设置fp16=True,后出现报错ValueError: Attempting to unscale FP16 gradients.
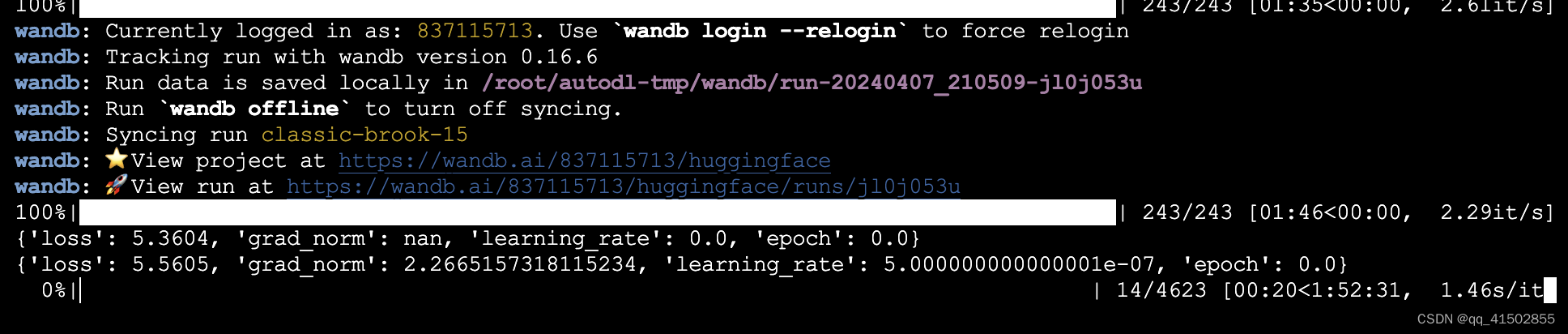
步骤2,将peft版本降为0.3.0后,报错消失,loss正常
lora微调过程中出现loss持续为0
步骤1,设置fp16=True,后出现报错ValueError: Attempting to unscale FP16 gradients.
步骤2,将peft版本降为0.3.0后,报错消失,loss正常
 1074
297
2486
1203
6417
4463
1074
297
2486
1203
6417
4463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























