







1、网站情况及爬虫目标
网站为:https://fz.fang.anjuke.com/loupan/all/;需要得到的是该页面的所有楼盘信息;观察可知,第一页的网址为前面的网址加上p1/,即https://fz.fang.anjuke.com/loupan/all/p1/,同理,第i页为原有网址加上pi/。同样采用循环语句得到共10页的楼盘信息。
2、Xpath
要得到相应的信息需要知道每个信息保存在html中的哪个节点,可以采用谷歌浏览器打开,右击”检查“可得到网页代码情况:
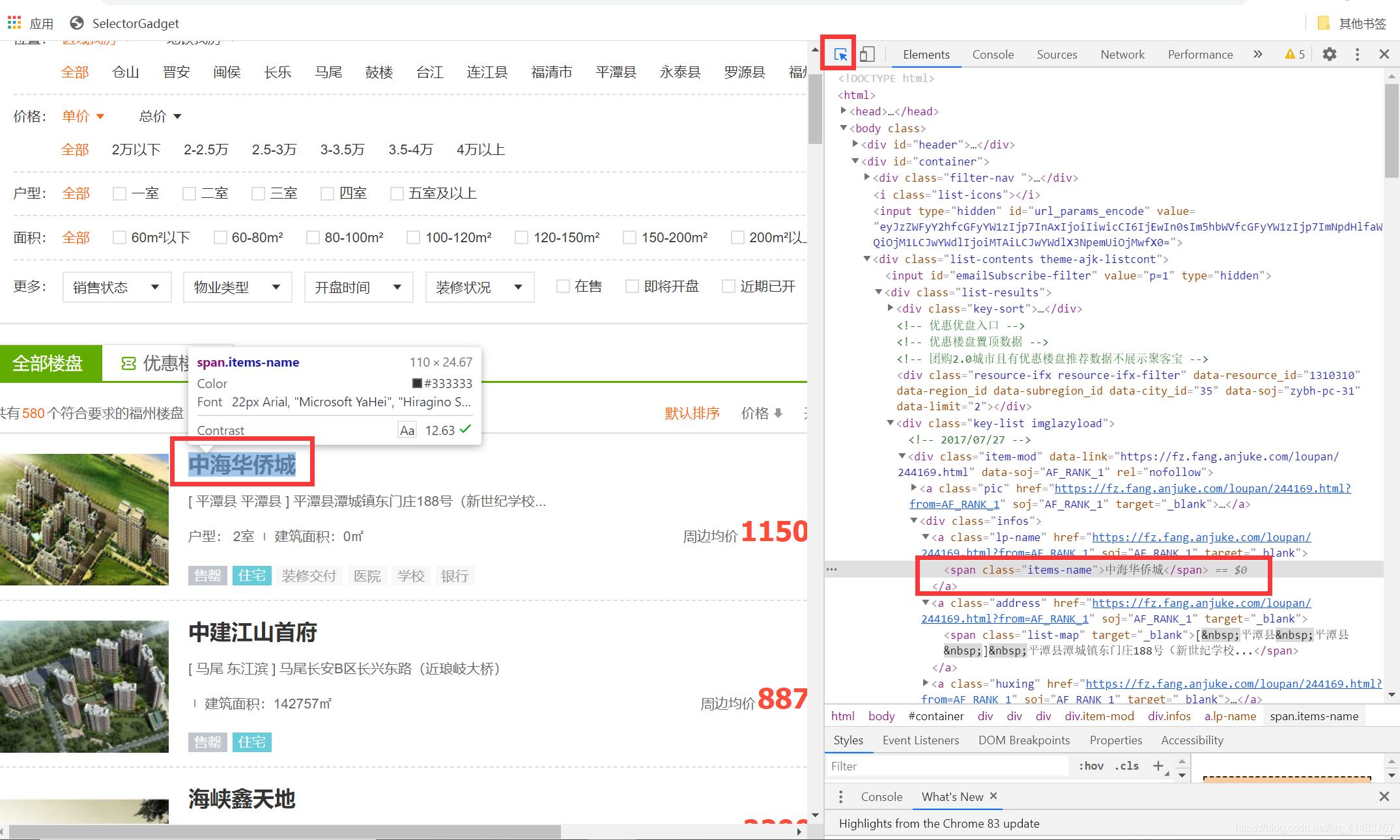
可知,”中海华侨城“这段文字信息位于属性为infos的第一个div节点下的第一个a节点,观察其他的楼盘名字的信息,均位于属性为infos的div节点下的第一个a节点,因此相应的路径则为“//div[@class='infos']/a[1]” ,其中@符号表示符合属性为class的所有div节点。同理分别可根据xpath得到其余地址和房价等信息。
3、爬虫代码
library(xml2)
library(XML)
library(RCurl)
library(rvest)
loupan_inf<-data.frame()
for(i in 1:10)
{
#解析网址
web<-read_html(str_c("https://fz.fang.anjuke.com/loupan/all/p1",i,"/"))
#获得节点并提取其中的文字部分
lp_name<-web%>%html_nodes(xpath = "//div[@class='infos']/a[1]")%>%html_text()
#去除多余的字符
lp_name<-str_remove_all(lp_name,"[\n\t]")
#获得节点并提取其中的文字部分
lp_adress<-web%>%html_nodes(xpath = "//div[@class='infos']/a[2]")%>%html_text()
#去除多余的字符
lp_adress<-str_remove_all(lp_adress,"[ \n\t]")
#获得节点并提取其中的文字部分
lp_huxing<-web%>%html_nodes(xpath = "//div[@class='infos']/a[3]")%>%html_text()
#去除多余的字符
lp_huxing<-str_remove_all(lp_huxing,"[ \n\t]")
#获得节点并提取其中的文字部分
lp_favor<-web%>%html_nodes(xpath = "//a[@class='favor-pos']")%>%html_text()
#去除多余的字符
lp_favor<-str_remove_all(lp_favor,"[ \n\t]")
#放在一个数据框里
loupan<-data.frame(lp_name,lp_adress,lp_huxing,lp_favor)
loupan_inf<-rbind(loupan_inf,loupan)
}
#输出
setwd("F:/s/R语言/爬虫练习")
write.csv(loupan_inf,file ="福州市楼盘.csv")
4、结果
最后得到的结果中,原先在R语言里输出正常的地址,到csv中变成了乱码,这个问题有待后续解决~对于以后一些复杂的数据处理需要再详细了解下正则表达式。
R中的显示结果:

输出csv后得到的结果:


















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









