






 XLA是TensorFlow的编译器,能显著提升模型性能,尤其在GPU上。它通过融合运算减少内存使用,提高计算效率。文章介绍了XLA的工作原理,展示了如何使用xla.compile API在代码中应用XLA,并提到了使用注意事项,包括GPU后端的实验性质、不支持的部分运算以及对可推断形状和运算的支持要求。
XLA是TensorFlow的编译器,能显著提升模型性能,尤其在GPU上。它通过融合运算减少内存使用,提高计算效率。文章介绍了XLA的工作原理,展示了如何使用xla.compile API在代码中应用XLA,并提到了使用注意事项,包括GPU后端的实验性质、不支持的部分运算以及对可推断形状和运算的支持要求。
XLA 简介
XLA 是 TensorFlow 图表的编译器,只需更改极少的源代码,便可加速您的 TensorFlow ML 模型。这篇文章将介绍 XLA,并说明如何在您自己的代码中试用 XLA。
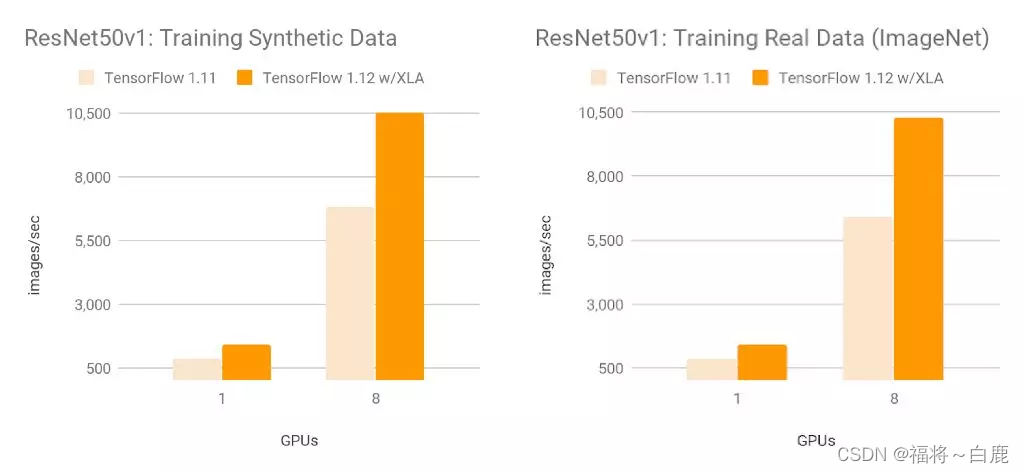
在使用 NVIDIA® Tesla® V100 GPU 训练 ResNet50 v1.0 时,相比 TensorFlow 1.11(未配备 XLA),TensorFlow 1.12(配备 XLA)的性能有显著提升:合成数据为每秒 10526 张图像,真实数据为每秒 10267 张图像(复制说明请见附录)。我们在各种内部模型上观察到速度提升(从 1.13 倍至 3.04 倍)。
加速原理
通常情况下,当您运行 TensorFlow 图表时,所有运算都由 TensorFlow 图表执行器单独执行。每个运算都会安装由图表执行器分派的预编译 GPU 内核(随附于 TensorFlow 二进制文件中)。
XLA 提供了另一种运行 TensorFlow 模型的模式:这种模式会将您的 TensorFlow 图表编译成专为您的模型生成的 GPU 内核序列。由于这些是您程序独有的内核,因此它们可以利用模型的特定信息进行优化。
举一个例子,我们一起看看 XLA 在简单 TensorFlow 计算环境中的优化过程:
def get_learning_rate(is_warmup, learning_rate, warmup_learning_rate):
return (1.0 - is_warmup) * learning_rate + is_warmup * warmup_learning_rate
如果运行模型时不使用 XLA,图表会启动三个内核,分别用于乘法、加法和减法。
但是,XLA 可以优化图表,以便在启动单个内核时计算结果。方法是将加法、乘法和减法 “融合” 到单个 GPU 内核中。此外,这种融合运算不会将 yz 和 x+yz 生成的中间值写入内存,而是将这些中间计算的结果直接 “流式传输” 给用户,并完整保存在 GPU 寄存器中。
融合是 XLA 最重要的一种优化方式。内存带宽通常是硬件加速器上最稀缺的资源,因此删除内存运算是提升性能的最佳方法之一。
应用演示
XLA 使用 xla.compile API,让您可以在部分 TensorFlow 图表上显式调用 XLA 编译器。xla.compile 会接受生成 TensorFlow 计算的 Python 函数,然后连接所生成的计算以供 XLA 编译。xla.compile 还会返回张量列表,其中每个张量对应传入函数构建的计算结果,但现在会立即由 XLA 优化。
因此,通过调用 xla.compile,您可以使用 XLA 运行以上由 model_fn 生成的计算,如下所示:
learning_rate = xla.compile(computation=get_learning_rate, inputs=(is_warmup, learning_rate, warmup_learning_rate))
- 官方已经设置 colab,让您可以在稍微复杂一些的模型上使用 xla.compile。
xla.compile 不是在 TensorFlow 子图表上调用 XLA 的唯一方法;具体来说,有一些方法可以让 TensorFlow 自动找到与 XLA 兼容的子图表并使用 XLA 进行编译,但我们不会在这篇文章中讨论这些方法。
使用 XLA 的注意事项
第一,XLA GPU 后端目前仍处于实验阶段,虽然我们没有发现任何重大问题,但其尚未进行广泛的生产使用测试。
第二,xla.compile 仍不适用于 model.fit 等 Keras 高级 API(但您可以使用 Keras 运算),也不支持 Eager 模式。我们正在积极开发 API 以便在这些模式下启用 XLA;敬请期待。
第三,XLA 无法编译所有 TensorFlow 图表;只有具有以下属性的图表才能传递给 xla.compile。
所有运算都必须具有可推断的形状
XLA 需要能够在给定计算输入的情况下,推断出其编译的所有运算的形状。因此,如果模型函数生成的 Tensor 具有不可推断的形状,则运行时将会出现错误,进而导致运行失败。(在这个例子中,tf.expand_dims 的输出形状取决于 random_dim_size,但其无法在给定 x、y 和 z 的情况下推断出来。)
请注意,由于 XLA 是 JIT 编译器,形状会因不同的运行过程而异,前提是能够根据给定的集群输入条件推断出来。这个例子很好地体现了这一点。
XLA 必须支持所有运算
并非所有 TensorFlow 运算都可由 XLA 编译,如果模型中有 XLA 不支持的运算,XLA 编译就会失败。例如,XLA 不支持 tf.where 运算,因此如果您的模型函数包含此运算,使用 xla.compile 运行模型时便会失败。
XLA 支持的每项 TensorFlow 运算都可在 tensorflow/compiler/tf2xla/kernels/ 中调用 REGISTER_XLA_OP,因此您可以使用 grep 来搜索 REGISTER_XLA_OP 宏实例,以查找支持的 TensorFlow 运算列表。

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









