




| 《从零开始构建大语言模型》一书的补充代码,作者:Sebastian Raschka 代码仓库:https://github.com/rasbt/LLMs-from-scratch |  |
第5章:在无标签数据上进行预训练
from importlib.metadata import version
pkgs = ["matplotlib",
"numpy",
"tiktoken",
"torch",
"tensorflow" # 用于OpenAI的预训练权重
]
for p in pkgs:
print(f"{p} version: {version(p)}")
matplotlib version: 3.10.7
numpy version: 2.3.3
tiktoken version: 0.12.0
torch version: 2.5.1+cu124
tensorflow version: 2.20.0
- 在本章中,我们实现训练循环和基本模型评估代码来预训练LLM
- 在本章末尾,我们还将OpenAI公开可用的预训练权重加载到我们的模型中

- 本章涵盖的主题如下所示

5.1 评估生成式文本模型
- 我们从简要回顾使用前一章代码初始化GPT模型开始本节
- 然后,我们讨论LLM的基本评估指标
- 最后,在本节中,我们将这些评估指标应用于训练和验证数据集
5.1.1 使用GPT生成文本
- 我们使用前一章的代码初始化GPT模型
import torch
# from previous_chapters import GPTModel
# 如果本地没有`previous_chapters.py`文件,
# 您可以从`llms-from-scratch` PyPI包中导入它。
# 详情请参见:https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg
# 例如:
import sys
sys.path.append('d:/agent-llm2/LLMs-from-scratch') # 添加项目根目录到路径
from pkg.llms_from_scratch.ch04 import GPTModel
GPT_CONFIG_124M = {
"vocab_size": 50257, # 词汇表大小
"context_length": 256, # 缩短的上下文长度(原始:1024)
"emb_dim": 768, # 嵌入维度
"n_heads": 12, # 注意力头数量
"n_layers": 12, # 层数
"drop_rate": 0.1, # Dropout率
"qkv_bias": False # 查询-键-值偏置
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval(); # 在推理期间禁用dropout
-
我们在上面使用了0.1的dropout,但现在训练LLM时不使用dropout是相对常见的
-
现代LLM也不在查询、键和值矩阵的
nn.Linear层中使用偏置向量(与早期的GPT模型不同),这通过设置"qkv_bias": False来实现 -
我们将上下文长度(
context_length)减少到仅256个token,以减少训练模型的计算资源需求,而原始的1.24亿参数GPT-2模型使用1024个token- 这样做是为了让更多读者能够在笔记本电脑上跟随和执行代码示例
- 但是,请随意将
context_length增加到1024个token(这不需要任何代码更改) - 我们稍后还将从预训练权重加载具有1024
context_length的模型
-
接下来,我们使用前一章的
generate_text_simple函数来生成文本 -
此外,我们定义两个便利函数
text_to_token_ids和token_ids_to_text,用于在token和文本表示之间转换,我们在本章中会使用这些函数

import tiktoken
# from previous_chapters import generate_text_simple
# 或者:
import sys
sys.path.append('d:/agent-llm2/LLMs-from-scratch')
from pkg.llms_from_scratch.ch04 import generate_text_simple
def text_to_token_ids(text, tokenizer):
"""将文本转换为token ID"""
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # 添加批次维度
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
"""将token ID转换为文本"""
flat = token_ids.squeeze(0) # 移除批次维度
return tokenizer.decode(flat.tolist())
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("输出文本:\n", token_ids_to_text(token_ids, tokenizer))
输出文本:
Every effort moves you rentingetic wasnم refres RexMeCHicular stren
- 如上所示,模型没有产生好的文本,因为它还没有被训练
- 我们如何以数字形式测量或捕获什么是"好文本",以便在训练期间跟踪它?
- 下一小节介绍了计算生成输出损失指标的方法,我们可以用它来衡量训练进度
- 关于微调LLM的后续章节还将介绍测量模型质量的其他方法
5.1.2 计算文本生成损失:交叉熵和困惑度
- 假设我们有一个包含2个训练示例(行)的token ID的
inputs张量 - 对应于
inputs,targets包含我们希望模型生成的期望token ID - 注意
targets是inputs向右移动1个位置,正如我们在第2章实现数据加载器时所解释的
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
targets = torch.tensor([[3626, 6100, 345 ], # [" effort moves you",
[1107, 588, 11311]]) # " really like chocolate"]
- 将
inputs输入到模型中,我们获得由3个token组成的2个输入示例的logits向量 - 每个token都是一个50,257维的向量,对应于词汇表的大小
- 应用softmax函数,我们可以将logits张量转换为包含概率分数的相同维度张量
with torch.no_grad():
logits = model(inputs)
probas = torch.softmax(logits, dim=-1) # 词汇表中每个token的概率
print(probas.shape) # 形状:(batch_size, num_tokens, vocab_size)
torch.Size([2, 3, 50257])
- 下图使用一个非常小的词汇表进行说明,概述了我们如何将概率分数转换回文本,这是我们在前一章末尾讨论的

-
如前一章所讨论的,我们可以应用
argmax函数将概率分数转换为预测的token ID -
上面的softmax函数为每个token产生了一个50,257维的向量;
argmax函数返回该向量中最高概率分数的位置,这是给定token的预测token ID -
由于我们有2个输入批次,每个批次有3个token,我们得到2×3的预测token ID:
token_ids = torch.argmax(probas, dim=-1, keepdim=True)
print("Token IDs:\n", token_ids)
Token IDs:
tensor([[[16657],
[ 339],
[42826]],
[[49906],
[29669],
[41751]]])
- 如果我们解码这些token,我们发现它们与我们希望模型预测的token(即目标token)相当不同:
print(f"目标批次1: {token_ids_to_text(targets[0], tokenizer)}")
print(f"输出批次1: {token_ids_to_text(token_ids[0].flatten(), tokenizer)}")
目标批次1: effort moves you
输出批次1: Armed heNetflix
- 这是因为模型还没有被训练
- 为了训练模型,我们需要知道它与正确预测(目标)的距离有多远

- 对应于目标索引的token概率如下:
text_idx = 0
target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("文本1:", target_probas_1)
text_idx = 1
target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("文本2:", target_probas_2)
文本1: tensor([7.4541e-05, 3.1061e-05, 1.1563e-05])
文本2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])
- 我们希望最大化所有这些值,使它们接近概率1
- 在数学优化中,最大化概率分数的对数比最大化概率分数本身更容易;这超出了本书的范围,但我在这里录制了一个包含更多细节的讲座:L8.2 逻辑回归损失函数
# 计算所有token概率的对数
log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))
print(log_probas)
tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])
- 接下来,我们计算平均对数概率:
# 计算每个token的平均概率
avg_log_probas = torch.mean(log_probas)
print(avg_log_probas)
tensor(-10.7940)
-
目标是通过优化模型权重使这个平均对数概率尽可能大
-
由于对数的存在,最大可能值是0,我们目前距离0还很远
-
在深度学习中,不是最大化平均对数概率,而是最小化负平均对数概率值的标准约定;在我们的情况下,不是最大化-10.7722使其接近0,在深度学习中,我们会最小化10.7722使其接近0
-
-10.7722的负值,即10.7722,在深度学习中也称为交叉熵损失
neg_avg_log_probas = avg_log_probas * -1
print(neg_avg_log_probas)
tensor(10.7940)
- PyTorch已经实现了执行前面步骤的
cross_entropy函数

- 在应用
cross_entropy函数之前,让我们检查logits和targets的形状
# Logits的形状为(batch_size, num_tokens, vocab_size)
print("Logits形状:", logits.shape)
# Targets的形状为(batch_size, num_tokens)
print("Targets形状:", targets.shape)
Logits形状: torch.Size([2, 3, 50257])
Targets形状: torch.Size([2, 3])
- 对于PyTorch中的
cross_entropy函数,我们希望通过在批次维度上组合来展平这些张量:
logits_flat = logits.flatten(0, 1)
targets_flat = targets.flatten()
print("展平的logits:", logits_flat.shape)
print("展平的targets:", targets_flat.shape)
展平的logits: torch.Size([6, 50257])
展平的targets: torch.Size([6])
- 注意targets是token ID,它们也表示logits张量中我们想要最大化的索引位置
- PyTorch中的
cross_entropy函数将自动处理在logits中要最大化的那些token索引上应用softmax和对数概率计算
loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)
print(loss)
tensor(10.7940)
- 与交叉熵损失相关的一个概念是LLM的困惑度
- 困惑度简单地是交叉熵损失的指数
perplexity = torch.exp(loss)
print(perplexity)
tensor(48725.8203)
- 困惑度通常被认为更具可解释性,因为它可以理解为模型在每一步不确定的有效词汇表大小(在上面的例子中,那将是48,725个单词或token)
- 换句话说,困惑度提供了模型预测的概率分布与数据集中单词的实际分布匹配程度的度量
- 与损失类似,较低的困惑度表明模型预测更接近实际分布
5.1.3 计算训练和验证集损失
-
我们使用相对较小的数据集来训练LLM(实际上,只有一个短篇故事)
-
原因是:
- 您可以在没有合适GPU的笔记本电脑上在几分钟内运行代码示例
- 训练完成相对较快(几分钟而不是几周),这对教育目的很好
- 我们使用公共领域的文本,可以包含在此GitHub仓库中而不违反任何使用权或使仓库大小膨胀
-
例如,Llama 2 7B需要在A100 GPU上184,320个GPU小时来训练2万亿个token
- 在撰写本文时,AWS上8xA100云服务器的每小时成本约为$30
- 因此,通过粗略计算,训练这个LLM将花费184,320 / 8 * $30 = $690,000
-
下面,我们使用第2章中使用的相同数据集
import os
import requests
file_path = "the-verdict.txt"
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
if not os.path.exists(file_path):
response = requests.get(url, timeout=30)
response.raise_for_status()
text_data = response.text
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
# 本书最初使用了下面的代码
# 但是,urllib使用较旧的协议设置,
# 对于一些使用VPN的读者可能会造成问题。
# 上面的`requests`版本在这方面更加健壮。
# import os
# import urllib.request
# file_path = "the-verdict.txt"
# url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
# if not os.path.exists(file_path):
# with urllib.request.urlopen(url) as response:
# text_data = response.read().decode('utf-8')
# with open(file_path, "w", encoding="utf-8") as file:
# file.write(text_data)
# else:
# with open(file_path, "r", encoding="utf-8") as file:
# text_data = file.read()
- 通过打印前99个和后99个字符来快速检查文本是否正确加载
# 前99个字符
print(text_data[:99])
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
# 后99个字符
print(text_data[-99:])
it for me! The Strouds stand alone, and happen once--but there's no exterminating our kind of art."
total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print("字符数:", total_characters)
print("Token数:", total_tokens)
字符数: 20479
Token数: 5145
-
有5,145个token,这个文本对于训练LLM来说非常短,但同样,这是为了教育目的(我们稍后也会加载预训练权重)
-
接下来,我们将数据集分为训练集和验证集,并使用第2章的数据加载器来准备LLM训练的批次
-
为了可视化目的,下图假设
max_length=6,但对于训练加载器,我们将max_length设置为等于LLM支持的上下文长度 -
下图为简单起见只显示输入token
- 由于我们训练LLM预测文本中的下一个单词,目标看起来与这些输入相同,除了目标向右移动一个位置

# from previous_chapters import create_dataloader_v1
# 或者:
from pkg.llms_from_scratch.ch02 import create_dataloader_v1
# 训练/验证比例
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
torch.manual_seed(123)
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=False,
shuffle=False,
num_workers=0
)
# 合理性检查
if total_tokens * (train_ratio) < GPT_CONFIG_124M["context_length"]:
print("训练加载器的token不足。"
"尝试降低`GPT_CONFIG_124M['context_length']`或"
"增加`training_ratio`")
if total_tokens * (1-train_ratio) < GPT_CONFIG_124M["context_length"]:
print("验证加载器的token不足。"
"尝试降低`GPT_CONFIG_124M['context_length']`或"
"减少`training_ratio`")
-
我们使用相对较小的批次大小来减少计算资源需求,也因为数据集本身就很小
-
例如,Llama 2 7B使用1024的批次大小进行训练
-
可选检查数据是否正确加载:
print("训练加载器:")
for x, y in train_loader:
print(x.shape, y.shape)
print("\n验证加载器:")
for x, y in val_loader:
print(x.shape, y.shape)
训练加载器:
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
验证加载器:
torch.Size([2, 256]) torch.Size([2, 256])
- 另一个可选检查token大小是否在预期范围内:
train_tokens = 0
for input_batch, target_batch in train_loader:
train_tokens += input_batch.numel()
val_tokens = 0
for input_batch, target_batch in val_loader:
val_tokens += input_batch.numel()
print("训练token:", train_tokens)
print("验证token:", val_tokens)
print("所有token:", train_tokens + val_tokens)
训练token: 4608
验证token: 512
所有token: 5120
- 接下来,我们实现一个实用函数来计算给定批次的交叉熵损失
- 此外,我们实现第二个实用函数来计算数据加载器中用户指定批次数的损失
def calc_loss_batch(input_batch, target_batch, model, device):
"""计算单个批次的损失"""
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
"""计算数据加载器的平均损失"""
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# 如果num_batches超过数据加载器中的批次总数,
# 则减少批次数以匹配数据加载器中的批次总数
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
- 如果您有支持CUDA的GPU的机器,LLM将在GPU上训练而无需对代码进行任何更改
- 通过
device设置,我们确保数据加载到与模型相同的设备上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
torch.manual_seed(123) # 为了可重现性
with torch.no_grad(): # 禁用梯度跟踪以提高效率
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("训练损失:", train_loss)
print("验证损失:", val_loss)
训练损失: 10.955184936523438
验证损失: 10.939273834228516
- 如预期的那样,训练和验证损失相对较高,因为模型还没有被训练
- 现在让我们实现训练函数
5.2 训练LLM
- 在本节中,我们实现训练循环来训练LLM
- 我们从一个简单的训练函数开始,然后添加额外的功能,如学习率调度、梯度裁剪和其他改进
5.2.1 训练循环
- 下面,我们实现一个相对简单的训练函数来训练LLM
def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
"""简单的模型训练函数"""
# 初始化列表来跟踪损失和token
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
# 主训练循环
for epoch in range(num_epochs):
model.train() # 设置模型为训练模式
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # 重置上一批次迭代的损失梯度
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # 计算损失梯度
optimizer.step() # 使用损失梯度更新模型权重
tokens_seen += input_batch.numel()
global_step += 1
# 可选评估步骤
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"训练损失 {train_loss:.3f}, 验证损失 {val_loss:.3f}")
# 在每个epoch后打印样本文本
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
"""评估模型在训练和验证集上的性能"""
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
def generate_and_print_sample(model, tokenizer, device, start_context):
"""生成并打印样本文本"""
model.eval()
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace('\n', ' ')) # 紧凑打印
model.train()
- 现在让我们使用这个训练函数来训练LLM:
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=1,
start_context="Every effort moves you", tokenizer=tokenizer
)
Ep 1 (Step 000005): 训练损失 6.158, 验证损失 6.240
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 1 (Step 000010): 训练损失 4.306, 验证损失 4.344
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 1 (Step 000015): 训练损失 4.623, 验证损失 4.608
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 2 (Step 000020): 训练损失 4.280, 验证损失 4.249
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 2 (Step 000025): 训练损失 4.231, 验证损失 4.227
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 2 (Step 000030): 训练损失 4.077, 验证损失 4.053
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 3 (Step 000035): 训练损失 4.011, 验证损失 4.001
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 3 (Step 000040): 训练损失 3.772, 验证损失 3.801
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 3 (Step 000045): 训练损失 3.667, 验证损失 3.682
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 4 (Step 000050): 训练损失 3.469, 验证损失 3.535
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 4 (Step 000055): 训练损失 3.180, 验证损失 3.255
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 4 (Step 000060): 训练损失 2.951, 验证损失 3.064
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 5 (Step 000065): 训练损失 2.840, 验证损失 2.959
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 5 (Step 000070): 训练损失 2.652, 验证损失 2.808
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 5 (Step 000075): 训练损失 2.541, 验证损失 2.718
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 6 (Step 000080): 训练损失 2.439, 验证损失 2.634
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 6 (Step 000085): 训练损失 2.346, 验证损失 2.560
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 6 (Step 000090): 训练损失 2.264, 验证损失 2.497
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 7 (Step 000095): 训练损失 2.192, 验证损失 2.442
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 7 (Step 000100): 训练损失 2.127, 验证损失 2.394
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 7 (Step 000105): 训练损失 2.069, 验证损失 2.351
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 8 (Step 000110): 训练损失 2.017, 验证损失 2.314
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 8 (Step 000115): 训练损失 1.971, 验证损失 2.281
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 8 (Step 000120): 训练损失 1.930, 验证损失 2.252
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 9 (Step 000125): 训练损失 1.893, 验证损失 2.226
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 9 (Step 000130): 训练损失 1.860, 验证损失 2.203
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 9 (Step 000135): 训练损失 1.830, 验证损失 2.182
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 10 (Step 000140): 训练损失 1.802, 验证损失 2.163
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 10 (Step 000145): 训练损失 1.777, 验证损失 2.145
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Ep 10 (Step 000150): 训练损失 1.754, 验证损失 2.129
Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
- 我们可以看到训练和验证损失都在下降,这是一个好兆头
- 但是,生成的文本仍然不是很好(只是逗号)
- 这是因为我们使用的数据集非常小
- 让我们绘制训练和验证损失来可视化训练进度:
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
# Plot training and validation loss against epochs
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(epochs_seen, val_losses, linestyle="-.", label="Validation loss")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True)) # only show integer labels on x-axis
# Create a second x-axis for tokens seen
ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis
ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks
ax2.set_xlabel("Tokens seen")
fig.tight_layout() # Adjust layout to make room
plt.savefig("loss-plot.pdf")
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
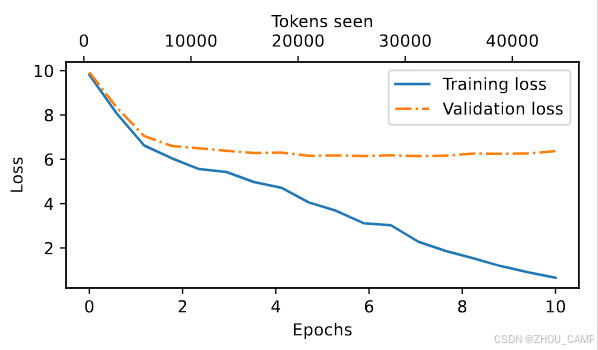
- 从上面的结果可以看出,模型开始时生成的是难以理解的词汇串,而到最后,它能够生成语法上或多或少正确的句子
- 然而,基于训练和验证集损失,我们可以看到模型开始过拟合
- 如果我们检查它在最后写的一些段落,我们会发现它们在训练集中是逐字存在的——它只是记住了训练数据
- 稍后,我们将介绍可以在一定程度上缓解这种记忆化的解码策略
- 请注意,这里的过拟合发生是因为我们有一个非常非常小的训练集,并且我们对它进行了很多次迭代
- 这里的LLM训练主要用于教育目的;我们主要想看到模型能够学会产生连贯的文本
- 与其花费数周或数月在大量昂贵的硬件上训练这个模型,我们稍后会加载预训练权重

如果您有兴趣使用更高级的技术来增强此训练函数,如学习率预热、余弦退火和梯度裁剪,请参考附录D
如果您对更大的训练数据集和更长的训练运行感兴趣,请参见…/03_bonus_pretraining_on_gutenberg
5.3 控制随机性的解码策略
- 对于像我们上面训练的GPT模型这样相对较小的LLM,推理相对便宜,所以如果您在上面使用GPU进行训练,就不需要为推理使用GPU
- 使用我们之前在简单训练函数中使用的
generate_text_simple函数(来自上一章),我们可以一次生成一个单词(或标记)的新文本 - 如5.1.2节所述,下一个生成的标记是词汇表中所有标记中对应最大概率分数的标记
# 新增:这里使用CPU,因为对于这个模型推理很便宜
# 并且确保读者在本书剩余部分获得相同的结果
inference_device = torch.device("cpu")
model.to(inference_device)
model.eval()
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(inference_device),
max_new_tokens=25,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:
Every effort moves you?"
"Yes--quite insensible to the irony. She wanted him vindicated--and by me!"
- 即使我们多次执行上面的
generate_text_simple函数,LLM也总是会生成相同的输出 - 我们现在引入两个概念,即所谓的解码策略,来修改
generate_text_simple:温度缩放和top-k采样 - 这些将允许模型控制生成文本的随机性和多样性
5.3.1 温度缩放
-
之前,我们总是使用
torch.argmax采样概率最高的标记作为下一个标记 -
为了增加多样性,我们可以使用
torch.multinomial(probs, num_samples=1)从概率分布中采样下一个标记 -
在这里,每个索引被选中的机会对应于它在输入张量中的概率
-
这里是生成下一个标记的小回顾,假设一个非常小的词汇表用于说明目的:
vocab = {
"closer": 0,
"every": 1,
"effort": 2,
"forward": 3,
"inches": 4,
"moves": 5,
"pizza": 6,
"toward": 7,
"you": 8,
}
inverse_vocab = {v: k for k, v in vocab.items()}
# 假设输入是"every effort moves you",LLM
# 为下一个标记返回以下logits:
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
).to("cpu")
probas = torch.softmax(next_token_logits, dim=0)
next_token_id = torch.argmax(probas).item()
# 下一个生成的标记如下:
print(inverse_vocab[next_token_id])
forward
torch.manual_seed(13)
next_token_id = torch.multinomial(probas, num_samples=1).item()
print(inverse_vocab[next_token_id])
forward
- 我们使用
torch.multinomial(probas, num_samples=1)通过从softmax分布中采样来确定最可能的标记,而不是通过torch.argmax确定最可能的标记 - 为了说明目的,让我们看看当我们使用原始softmax概率采样下一个标记1000次时会发生什么:
def print_sampled_tokens(probas):
torch.manual_seed(123) # 手动设置种子以确保可重现性
sample = [torch.multinomial(probas, num_samples=1).item() for i in range(1_000)]
sampled_ids = torch.bincount(torch.tensor(sample), minlength=len(probas))
for i, freq in enumerate(sampled_ids):
print(f"{freq} x {inverse_vocab[i]}")
print_sampled_tokens(probas)
71 x closer
2 x every
0 x effort
544 x forward
2 x inches
1 x moves
0 x pizza
376 x toward
4 x you
-
我们可以通过一个叫做温度缩放的概念来控制分布和选择过程
-
"温度缩放"只是将logits除以一个大于0的数字的花哨说法
-
大于1的温度在应用softmax后会导致更均匀分布的标记概率
-
小于1的温度在应用softmax后会导致更自信(更尖锐或更尖峰)的分布
-
请注意,根据您的操作系统,生成的dropout输出可能看起来不同;您可以在PyTorch问题跟踪器上阅读更多关于这种不一致性的信息
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
# 温度值
temperatures = [1, 0.1, 5] # 原始、更高置信度和更低置信度
# 计算缩放概率
scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]
# 绘图
x = torch.arange(len(vocab))
bar_width = 0.15
fig, ax = plt.subplots(figsize=(5, 3))
for i, T in enumerate(temperatures):
rects = ax.bar(x + i * bar_width, scaled_probas[i], bar_width, label=f'Temperature = {T}')
ax.set_ylabel('Probability')
ax.set_xticks(x)
ax.set_xticklabels(vocab.keys(), rotation=90)
ax.legend()
plt.tight_layout()
plt.savefig("temperature-plot.pdf")
plt.show()
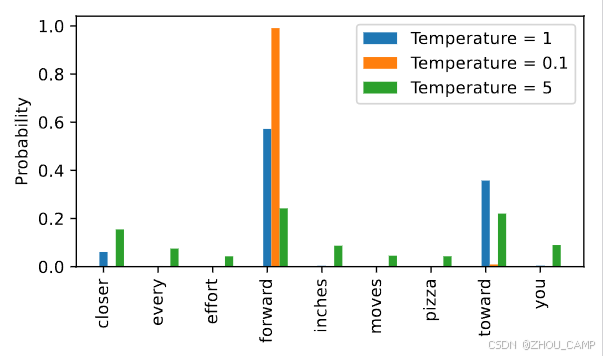
- 我们可以看到,通过温度0.1的重新缩放导致更尖锐的分布,接近
torch.argmax,使得最可能的词几乎总是被选中:
print_sampled_tokens(scaled_probas[1])
0 x closer
0 x every
0 x effort
992 x forward
0 x inches
0 x moves
0 x pizza
8 x toward
0 x you
- 通过温度5重新缩放的概率更均匀分布:
print_sampled_tokens(scaled_probas[2])
153 x closer
68 x every
55 x effort
223 x forward
102 x inches
50 x moves
43 x pizza
218 x toward
88 x you
- 假设LLM输入"every effort moves you",使用上述方法有时会导致无意义的文本,如"every effort moves you pizza",在3.2%的时间内(1000次中的32次)
5.3.2 Top-k采样
- 为了能够使用更高的温度来增加输出多样性并减少无意义句子的概率,我们可以将采样的标记限制为top-k个最可能的标记:

-
(请注意,此图中的数字被截断为小数点后两位以减少视觉混乱。Softmax行中的值应该加起来等于1.0。)
-
在代码中,我们可以这样实现:
top_k = 3
top_logits, top_pos = torch.topk(next_token_logits, top_k)
print("Top logits:", top_logits)
print("Top positions:", top_pos)
Top logits: tensor([6.7500, 6.2800, 4.5100])
Top positions: tensor([3, 7, 0])
new_logits = torch.where(
condition=next_token_logits < top_logits[-1],
input=torch.tensor(float("-inf")),
other=next_token_logits
)
print(new_logits)
tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])
注意:
前一个代码单元的另一种稍微更高效的实现如下:
new_logits = torch.full_like( # 创建包含-inf值的张量 next_token_logits, -torch.inf ) new_logits[top_pos] = next_token_logits[top_pos] # 将top k值复制到-inf张量中
更多详情,请参见 https://github.com/rasbt/LLMs-from-scratch/discussions/326
topk_probas = torch.softmax(new_logits, dim=0)
print(topk_probas)
tensor([0.0615, 0.0000, 0.0000, 0.5775, 0.0000, 0.0000, 0.0000, 0.3610, 0.0000])
5.3.3 修改文本生成函数
- 前面两个小节介绍了温度采样和top-k采样
- 让我们使用这两个概念来修改第4章中的
generate_text_simple函数,创建一个新的generate函数:
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
# For循环与之前相同:获取logits,只关注最后一个时间步
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
# 新增:使用top_k采样过滤logits
if top_k is not None:
# 只保留top_k值
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# 新增:应用温度缩放
if temperature > 0.0:
logits = logits / temperature
# 新增(书中没有):数值稳定性技巧,在mps设备上获得等效结果
# 在softmax之前减去行最大值
logits = logits - logits.max(dim=-1, keepdim=True).values
# 应用softmax获得概率
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# 从分布中采样
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# 否则与之前相同:获取具有最高logits值的词汇条目的idx
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
if idx_next == eos_id: # 如果遇到序列结束标记且指定了eos_id,则提前停止生成
break
# 与之前相同:将采样的索引附加到运行序列中
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
return idx
torch.manual_seed(123)
token_ids = generate(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(inference_device),
max_new_tokens=15,
context_size=GPT_CONFIG_124M["context_length"],
top_k=25,
temperature=1.4
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:
Every effort moves you know began to go a hint a littleoms he painted with a single enough
5.4 在PyTorch中加载和保存模型权重
- 训练LLM在计算上是昂贵的,因此能够保存和加载LLM权重至关重要

- PyTorch中推荐的方法是通过将
torch.save函数应用于.state_dict()方法来保存模型权重,即所谓的state_dict:
torch.save(model.state_dict(), "model.pth")
- 然后我们可以将模型权重加载到新的
GPTModel模型实例中,如下所示:
model = GPTModel(GPT_CONFIG_124M)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.load_state_dict(torch.load("model.pth", map_location=device, weights_only=True))
model.eval();
- 使用像Adam或AdamW这样的自适应优化器而不是常规SGD来训练LLM是很常见的
- 这些自适应优化器为每个模型权重存储额外的参数,因此如果我们计划稍后继续预训练,保存它们也是有意义的:
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
},
"model_and_optimizer.pth"
)
checkpoint = torch.load("model_and_optimizer.pth", weights_only=True)
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
model.train();
5.5 从OpenAI加载预训练权重
- 之前,我们只使用一本非常小的短篇小说书来训练小型GPT-2模型,用于教育目的
- 感兴趣的读者也可以在…/03_bonus_pretraining_on_gutenberg中找到在完整的古腾堡计划书籍语料库上进行的更长预训练运行
- 幸运的是,我们不必花费数万到数十万美元在大型预训练语料库上预训练模型,而是可以加载OpenAI提供的预训练权重
⚠️ 注意:由于TensorFlow兼容性问题,某些用户可能在本节遇到问题,特别是在某些Windows系统上。这里需要TensorFlow仅用于加载原始的OpenAI GPT-2权重文件,然后我们将其转换为PyTorch。
如果您遇到TensorFlow相关问题,可以使用下面的替代代码,而不是本节中的其余代码。
这个替代方案基于预转换的PyTorch权重,使用前一节中描述的相同转换过程创建。详细信息请参考笔记本:
…/02_alternative_weight_loading/weight-loading-pytorch.ipynb 笔记本。
file_name = "gpt2-small-124M.pth"
# file_name = "gpt2-medium-355M.pth"
# file_name = "gpt2-large-774M.pth"
# file_name = "gpt2-xl-1558M.pth"
url = f"https://huggingface.co/rasbt/gpt2-from-scratch-pytorch/resolve/main/{file_name}"
if not os.path.exists(file_name):
urllib.request.urlretrieve(url, file_name)
print(f"Downloaded to {file_name}")
gpt = GPTModel(BASE_CONFIG)
gpt.load_state_dict(torch.load(file_name, weights_only=True))
gpt.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gpt.to(device);
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.5
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
- 首先,一些样板代码用于从OpenAI下载文件并将权重加载到Python中
- 由于OpenAI使用了TensorFlow,我们必须安装并使用TensorFlow来加载权重;tqdm是一个进度条库
- 取消注释并运行下一个单元格来安装所需的库
# pip install tensorflow tqdm
print("TensorFlow version:", version("tensorflow"))
print("tqdm version:", version("tqdm"))
TensorFlow version: 2.20.0
tqdm version: 4.67.1
# 从此文件夹中包含的gpt_download.py进行相对导入
from gpt_download import download_and_load_gpt2
# 或者:
# from llms_from_scratch.ch05 import download_and_load_gpt2
注意
- 在极少数情况下,上面的代码单元格可能会导致
zsh: illegal hardware instruction python错误,这可能是由于您机器上的TensorFlow安装问题 - 一位读者发现通过
conda安装TensorFlow解决了这个特定情况下的问题,如这里所述 - 您可以在这个补充的Python设置教程中找到更多说明
- 然后我们可以下载1.24亿参数模型的模型权重,如下所示:
settings, params = download_and_load_gpt2(model_size="124M", models_dir="gpt2")
checkpoint: 100%|████████████████████████████████████████████████████████████████████████████████| 77.0/77.0 [00:00<00:00, 63.1kiB/s]
encoder.json: 100%|████████████████████████████████████████████████████████████████████████████| 1.04M/1.04M [00:00<00:00, 4.69MiB/s]
hparams.json: 100%|██████████████████████████████████████████████████████████████████████████████| 90.0/90.0 [00:00<00:00, 59.7kiB/s]
model.ckpt.data-00000-of-00001: 100%|████████████████████████████████████████████████████████████| 498M/498M [01:09<00:00, 7.15MiB/s]
model.ckpt.index: 100%|████████████████████████████████████████████████████████████████████████| 5.21k/5.21k [00:00<00:00, 2.32MiB/s]
model.ckpt.meta: 100%|███████████████████████████████████████████████████████████████████████████| 471k/471k [00:00<00:00, 2.19MiB/s]
vocab.bpe: 100%|█████████████████████████████████████████████████████████████████████████████████| 456k/456k [00:00<00:00, 3.47MiB/s]
print("Settings:", settings)
Settings: {'n_vocab': 50257, 'n_ctx': 1024, 'n_embd': 768, 'n_head': 12, 'n_layer': 12}
print("Parameter dictionary keys:", params.keys())
Parameter dictionary keys: dict_keys(['blocks', 'b', 'g', 'wpe', 'wte'])
print(params["wte"])
print("Token embedding weight tensor dimensions:", params["wte"].shape)
[[-0.11010301 -0.03926672 0.03310751 ... -0.1363697 0.01506208
0.04531523]
[ 0.04034033 -0.04861503 0.04624869 ... 0.08605453 0.00253983
0.04318958]
[-0.12746179 0.04793796 0.18410145 ... 0.08991534 -0.12972379
-0.08785918]
...
[-0.04453601 -0.05483596 0.01225674 ... 0.10435229 0.09783269
-0.06952604]
[ 0.1860082 0.01665728 0.04611587 ... -0.09625227 0.07847701
-0.02245961]
[ 0.05135201 -0.02768905 0.0499369 ... 0.00704835 0.15519823
0.12067825]]
Token embedding weight tensor dimensions: (50257, 768)
- 或者,“355M”、"774M"和"1558M"也是支持的
model_size参数 - 这些不同大小模型之间的差异在下图中总结:

- 上面,我们将124M GPT-2模型权重加载到Python中,但我们仍然需要将它们传输到我们的
GPTModel实例中 - 首先,我们初始化一个新的GPTModel实例
- 请注意,原始GPT模型在多头注意力模块中为查询、键和值矩阵的线性层初始化了偏置向量,这不是必需的或推荐的;但是,为了能够正确加载权重,我们也必须通过在我们的实现中将
qkv_bias设置为True来启用这些 - 我们还使用了原始GPT-2模型使用的
1024标记上下文长度
# 在字典中定义模型配置以保持紧凑性
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
# 复制基础配置并使用特定模型设置更新
model_name = "gpt2-small (124M)" # 示例模型名称
NEW_CONFIG = GPT_CONFIG_124M.copy()
NEW_CONFIG.update(model_configs[model_name])
NEW_CONFIG.update({"context_length": 1024, "qkv_bias": True})
gpt = GPTModel(NEW_CONFIG)
gpt.eval();
- 下一个任务是将OpenAI权重分配给我们
GPTModel实例中相应的权重张量
def assign(left, right):
if left.shape != right.shape:
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
return torch.nn.Parameter(torch.tensor(right))
import numpy as np
def load_weights_into_gpt(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
for b in range(len(params["blocks"])):
q_w, k_w, v_w = np.split(
(params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
q_b, k_b, v_b = np.split(
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale,
params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift,
params["blocks"][b]["ln_1"]["b"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale,
params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift,
params["blocks"][b]["ln_2"]["b"])
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
load_weights_into_gpt(gpt, params)
gpt.to(device);
- 如果模型加载正确,我们可以使用之前的
generate函数来生成新文本:
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.5
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:
Every effort moves you toward finding an ideal new way to practice something!
What makes us want to be on top of that?
-
我们知道我们正确加载了模型权重,因为模型能够生成连贯的文本;如果我们犯了哪怕一个小错误,模型都无法做到这一点
-
有关从Hugging Face Hub加载权重的替代方法,请参见…/02_alternative_weight_loading
-
如果您有兴趣了解GPT架构与Llama架构(Meta AI开发的流行LLM)的比较,请参见…/07_gpt_to_llama的奖励内容
总结和要点
- 参见./gpt_train.py脚本,一个用于训练的独立脚本
- ./gpt_generate.py脚本从OpenAI加载预训练权重并基于提示生成文本
- 您可以在./exercise-solutions.ipynb中找到练习解答

















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









