LLMs-from-scratch第七章:指令微调核心技术解析
 项目地址: https://gitcode.com/GitHub_Trending/ll/LLMs-from-scratch
项目地址: https://gitcode.com/GitHub_Trending/ll/LLMs-from-scratch 你是否曾困惑于如何让预训练语言模型理解并执行人类指令?想知道ChatGPT等对话模型如何从文本续写升级为智能助手?本文将带你深入LLMs-from-scratch项目第七章,掌握指令微调(Instruction Finetuning)核心技术,用简单代码将基础语言模型转变为能理解复杂指令的AI助手。读完本文,你将能够:
- 掌握指令微调的完整工作流程
- 学会构建高质量的指令数据集
- 实现高效的批量数据处理策略
- 理解损失函数优化技巧
- 完成模型微调与评估全流程
指令微调:让AI理解人类意图的关键技术
指令微调是将预训练语言模型(仅擅长文本续写)转化为指令遵循模型(能理解并执行任务指令)的核心技术。如图所示,预训练模型通过在海量文本上学习预测下一个token,而指令微调则通过特定格式的指令-响应对数据,让模型学会理解任务要求并生成合适的回答。
第七章完整覆盖了从数据准备到模型评估的全流程,主要包含以下关键技术模块:
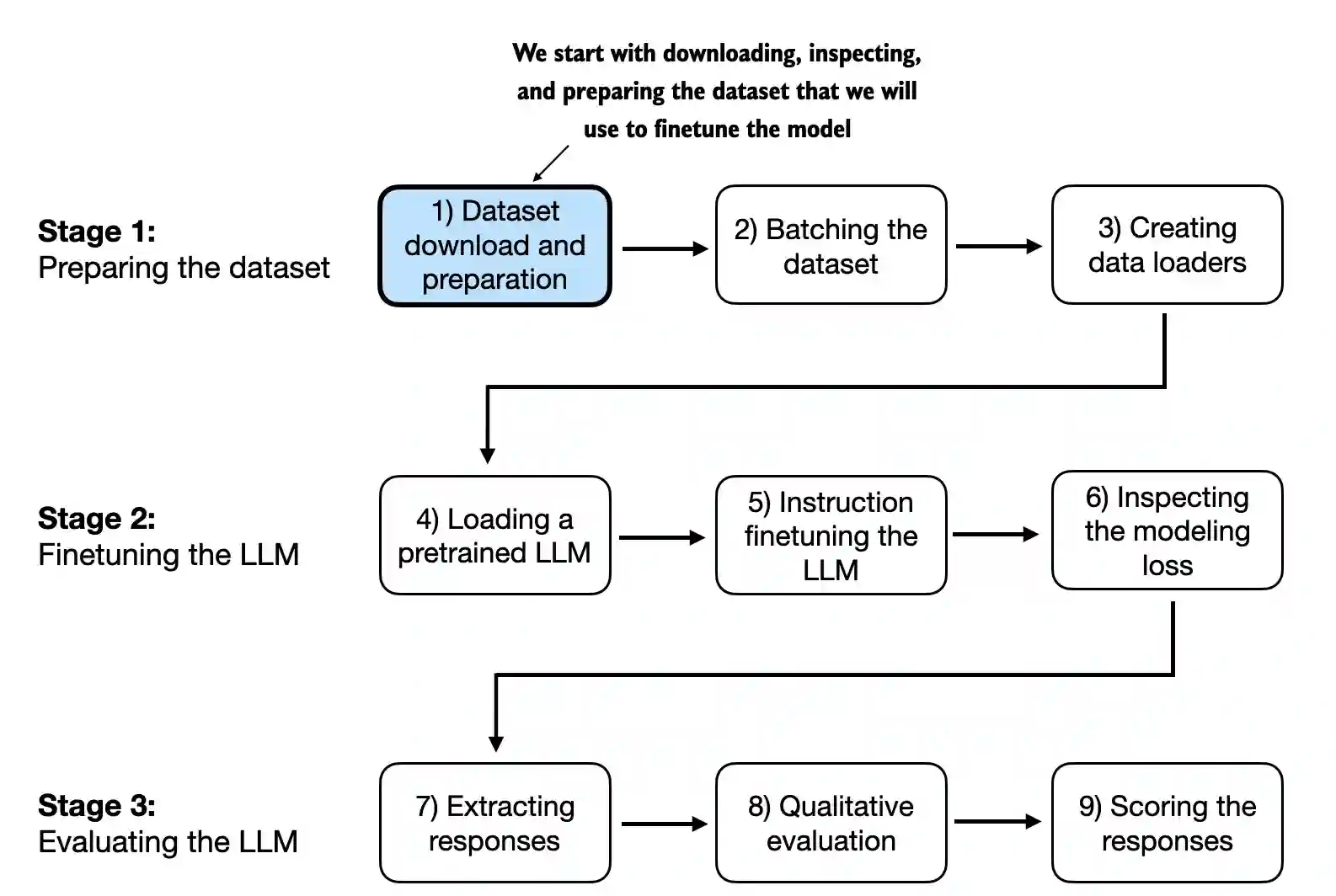
核心实现代码位于ch07/01_main-chapter-code/目录,主要包括:
- gpt_instruction_finetuning.py:完整微调脚本
- ch07.ipynb:交互式教程
- instruction-data.json:示例指令数据集
构建高质量指令数据集
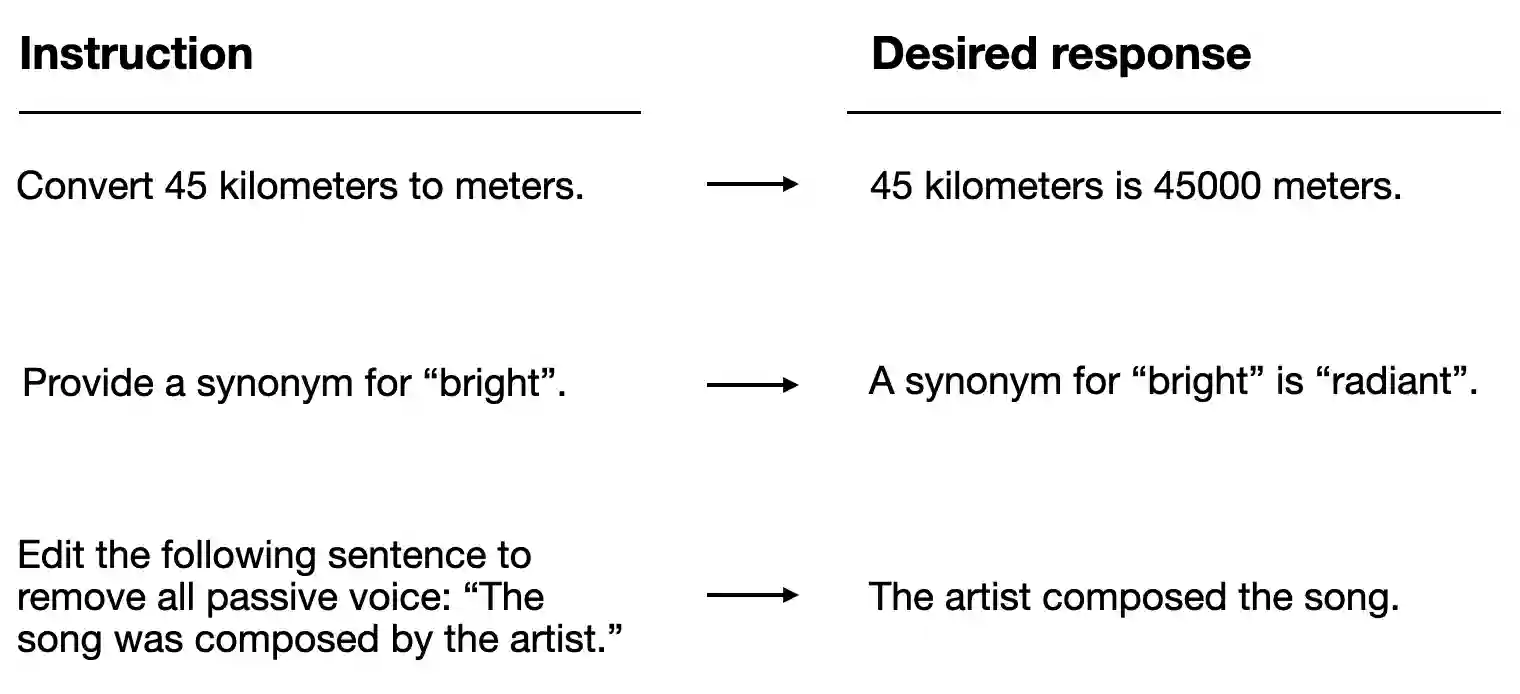
指令微调的效果高度依赖数据质量。第七章采用Alpaca风格的指令格式,每个数据样本包含三个核心字段:
{
"instruction": "识别下列单词的正确拼写。", # 任务描述
"input": "Ocassion", # 任务输入(可选)
"output": "正确拼写是'Occasion'。" # 期望输出
}
数据集构建关键步骤
- 数据收集与格式化: 项目提供的instruction-data.json包含1100条指令样本,涵盖拼写纠正、情感分析、摘要生成等多种任务类型。数据格式处理通过format_input函数实现:
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
return instruction_text + input_text
- 数据划分: 将数据集划分为训练集(85%)、验证集(5%)和测试集(10%),确保模型能在未见数据上评估泛化能力:
train_portion = int(len(data) * 0.85) # 训练集:935条
test_portion = int(len(data) * 0.1) # 测试集:110条
val_portion = len(data) - train_portion - test_portion # 验证集:55条
- 数据质量保障:
- 确保指令表述清晰明确
- 控制输入输出长度,避免极端样本
- 覆盖多样化任务类型
- 保证响应质量和准确性
项目还提供了数据集处理工具集,位于ch07/02_dataset-utilities/,包括重复数据检测、指令生成等实用工具。
高效批量数据处理策略
语言模型训练需要高效处理大量数据,第七章实现了针对指令数据的优化批量处理流程,解决了变长序列的高效训练问题。
自定义数据集类
InstructionDataset类负责将文本数据预处理为模型可接受的token格式:
class InstructionDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
self.encoded_texts = []
for entry in data:
# 格式化指令+输入
instruction_plus_input = format_input(entry)
# 添加响应部分
response_text = f"\n\n### Response:\n{entry['output']}"
full_text = instruction_plus_input + response_text
# 编码为token IDs
self.encoded_texts.append(tokenizer.encode(full_text))
def __getitem__(self, index):
return self.encoded_texts[index]
def __len__(self):
return len(self.data)
智能批量处理技术
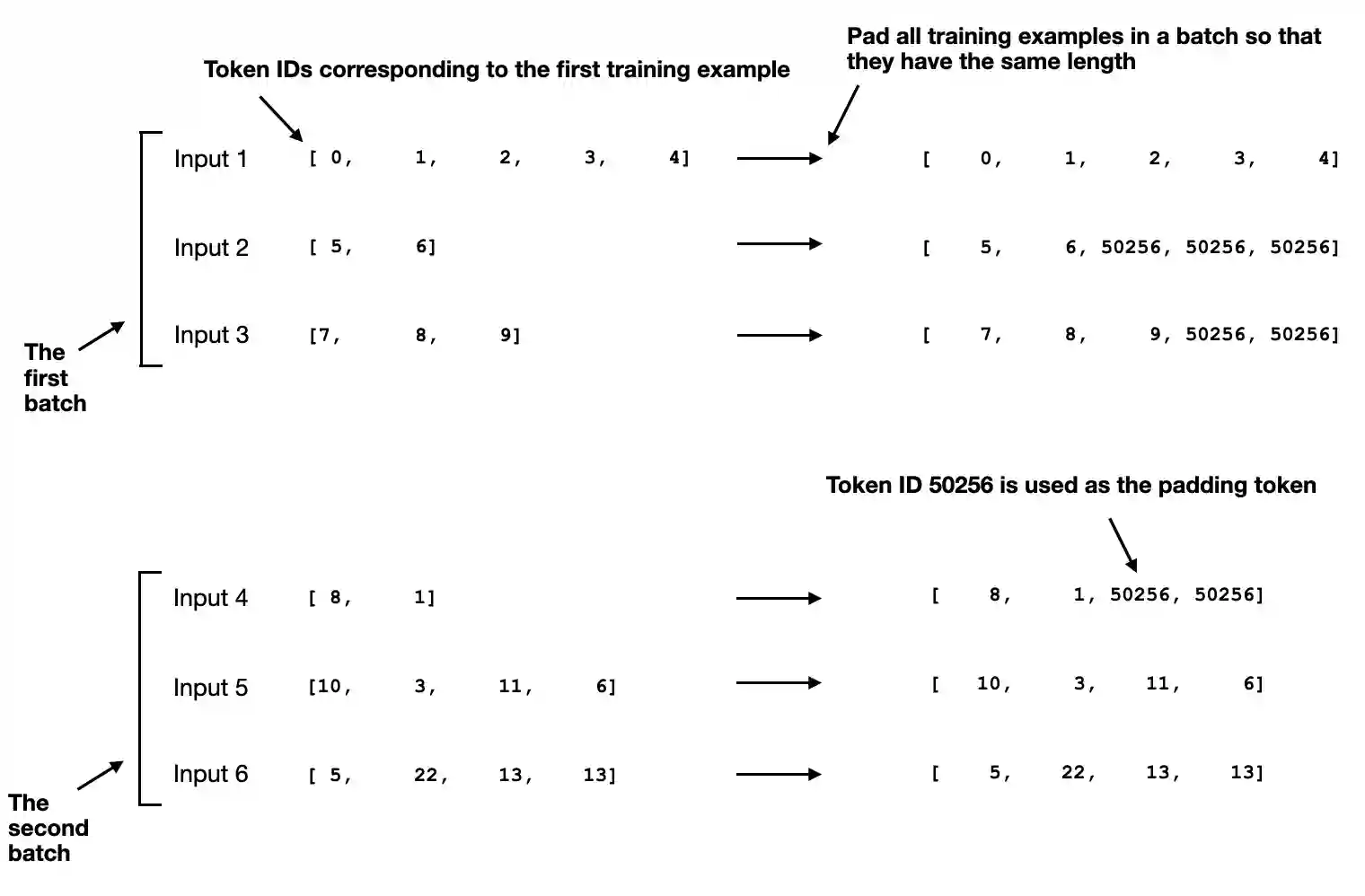
由于不同指令样本长度差异大,第七章提出了动态批量处理策略,主要包含以下创新点:
- 动态长度填充:每个批次按最长样本长度填充,避免统一长度导致的计算浪费:
- 输入-目标对构建:将输入序列右移一位作为目标序列,实现自回归训练:
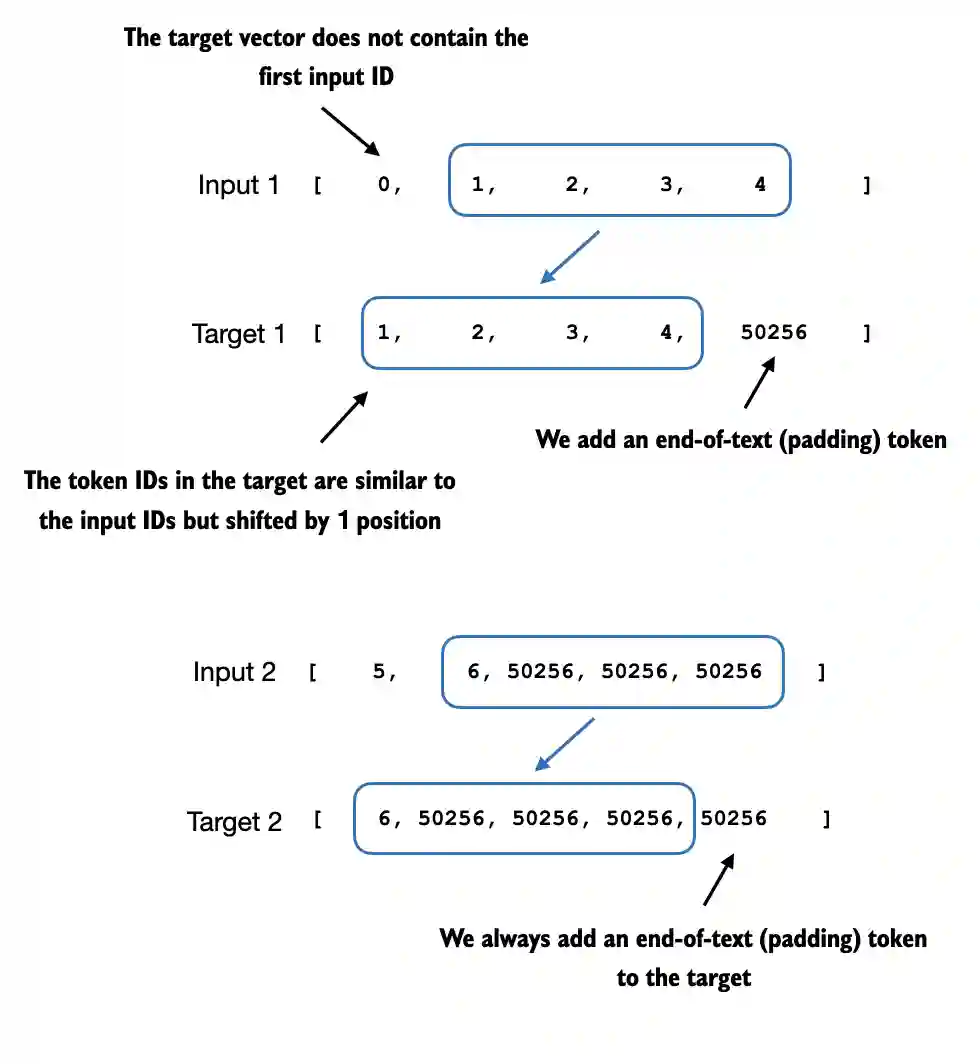
- 损失掩码技术:仅计算响应部分的损失,忽略指令部分的预测误差,实现精准目标导向训练:
def custom_collate_fn(batch, pad_token_id=50256, ignore_index=-100):
# 批次内最大长度
batch_max_length = max(len(item)+1 for item in batch)
inputs_lst, targets_lst = [], []
for item in batch:
# 添加结束符并填充
new_item = item.copy() + [pad_token_id]
padded = new_item + [pad_token_id]*(batch_max_length - len(new_item))
# 构建输入和目标
inputs = torch.tensor(padded[:-1])
targets = torch.tensor(padded[1:])
# 关键:仅保留第一个填充符,其余替换为ignore_index
mask = targets == pad_token_id
indices = torch.nonzero(mask).squeeze()
if indices.numel() > 1:
targets[indices[1:]] = ignore_index
inputs_lst.append(inputs)
targets_lst.append(targets)
return torch.stack(inputs_lst), torch.stack(targets_lst)
完整实现见custom_collate_fn函数,通过这一技术,模型能专注学习如何根据指令生成正确响应。
模型微调全流程实现
第七章使用GPT-2作为基础模型,通过以下步骤实现指令微调:
1. 环境准备与参数设置
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 批量处理配置
customized_collate_fn = partial(
custom_collate_fn,
device=device,
allowed_max_length=1024 # GPT-2最大序列长度
)
# 数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=8, # 根据GPU内存调整
collate_fn=customized_collate_fn,
shuffle=True,
drop_last=True
)
2. 加载预训练模型
项目支持多种规模的GPT-2模型,从124M到1558M参数:
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
# 默认使用3.5亿参数的medium模型
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
# 加载预训练权重
settings, params = download_and_load_gpt2(model_size="355M", models_dir="gpt2")
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.to(device)
3. 微调训练过程
指令微调采用小学习率、短训练周期的策略,关键参数设置:
# 优化器配置
optimizer = torch.optim.AdamW(
model.parameters(),
lr=5e-5, # 较小学习率,避免过拟合
weight_decay=0.1 # 权重衰减,提高泛化能力
)
# 训练配置
num_epochs = 2 # 少量epochs,防止过拟合
batch_size = 8 # 根据GPU内存调整
# 开始训练
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5
)
执行微调脚本:
python ch07/01_main-chapter-code/gpt_instruction_finetuning.py
训练过程输出示例:
Loaded model: gpt2-medium (355M)
--------------------------------------------------
Initial losses
Training loss: 3.839039182662964
Validation loss: 3.7619192123413088
Ep 1 (Step 000000): Train loss 2.611, Val loss 2.668
Ep 1 (Step 000005): Train loss 1.161, Val loss 1.131
Ep 1 (Step 000010): Train loss 0.939, Val loss 0.973
...
Training completed in 15.66 minutes.
Plot saved as loss-plot-standalone.pdf
--------------------------------------------------
Generating responses
100%|█████████████████████████████████████████████████████████| 110/110 [06:57<00:00, 3.80s/it]
Responses saved as instruction-data-with-response-standalone.json
Model saved as gpt2-medium355M-sft-standalone.pth
训练过程中会自动生成损失曲线,保存在loss-plot-standalone.pdf。
模型评估与结果分析
第七章提供了全面的评估方案,从定量和定性两个维度评估微调效果:
定量评估
通过计算测试集损失值评估整体性能:
# 计算测试集损失
test_loss = calc_loss_loader(test_loader, model, device)
print(f"Test loss: {test_loss:.4f}")
更高级的评估可使用ollama_evaluate.py脚本,通过LLM辅助评估生成质量:
python ch07/01_main-chapter-code/ollama_evaluate.py --file_path instruction-data-with-response-standalone.json
评估输出示例:
Ollama running: True
Scoring entries: 100%|███████████████████████████████████████| 110/110 [01:08<00:00, 1.62it/s]
Number of scores: 110 of 110
Average score: 51.75
定性评估
通过生成示例评估模型指令理解能力:
# 测试模型指令跟随能力
instruction = "解释什么是指令微调。"
input_text = format_input({"instruction": instruction, "input": ""})
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"]
)
print(token_ids_to_text(token_ids, tokenizer))
微调前后对比示例:
| 任务 | 微调前模型输出 | 微调后模型输出 |
|---|---|---|
| 拼写纠正 | "Ocassion is a word that..." | "正确拼写是'Occasion'。这个单词的意思是特殊事件或场合。" |
| 反义词查询 | "'complicated' is a word that means..." | "'complicated'的反义词是'simple'(简单的)。" |
高级优化与扩展应用
第七章还提供了多个高级主题的扩展内容,帮助读者深入理解指令微调技术:
数据集增强技术
ch07/02_dataset-utilities/目录提供了数据集质量提升工具:
- find-near-duplicates.py:检测并移除重复样本
- create-passive-voice-entries.ipynb:生成句式转换样本
- instruction-examples.json:高质量指令模板
模型优化技术
- 学习率调度:ch07/04_learning_rate_schedulers/提供多种学习率策略
- 内存优化:ch07/08_memory_efficient_weight_loading/展示低内存加载技术
- 训练加速:ch07/10_llm-training-speed/提供单GPU和多GPU优化方案
界面交互
ch07/06_user_interface/提供了简单的Web交互界面:
pip install -r ch07/06_user_interface/requirements-extra.txt
python ch07/06_user_interface/app.py
模型转换
ch07/07_gpt_to_llama/展示如何将微调后的GPT模型转换为Llama格式,支持更广泛部署:
- converting-gpt-to-llama2.ipynb:GPT到Llama2转换
- converting-llama2-to-llama3.ipynb:Llama2到Llama3升级
总结与实践建议
指令微调是构建实用对话AI的关键技术,通过第七章的学习,读者掌握了从数据准备到模型部署的全流程技能。实践中建议:
- 数据质量优先:指令微调效果高度依赖数据质量,建议投入60%以上精力在数据构建与清洗上
- 从小模型开始:先用小模型验证流程,再扩展到大规模模型
- 控制训练强度:指令微调通常只需要1-3个epochs,过度训练会导致过拟合
- 重视评估:结合自动指标和人工评估,全面衡量模型性能
第七章完整代码和教程为读者提供了实践指令微调技术的最佳起点。通过这些工具和知识,你可以将任何预训练语言模型转变为能理解复杂指令的AI助手,为构建智能对话系统、专业领域助手等应用奠定基础。
想要深入探索更多高级主题?推荐继续学习:
- 第八章:偏好优化(RLHF)技术
- 附录E:模型部署与优化
- 项目ch05/11_qwen3/:最新Qwen3模型实现
掌握指令微调技术,你已迈出构建真正理解人类意图的AI系统的关键一步!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







