






文章目录
I know, i know
地球另一端有你陪我
一、Flink
1、Sink
可以使用自定义 Sink,需要实现 RichSinkFunction 接口,重写里面的 invoke
1 直接在控制台打印
package sink
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
object Demo1Sink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val linesDS = env.socketTextStream("master", 8888)
// 使用自定义Sink
linesDS.addSink(new MySink)
env.execute()
}
}
/**
* 自定义sink
*
* 实现SinkFunction接口,重写里面的invoke
*
*/
class MySink extends RichSinkFunction[String] {
// invoke 前执行,每个任务执行一次
override def open(parameters: Configuration): Unit = {
println("open")
}
// invoke 后执行,每个任务执行一次
override def close(): Unit = {
println("close")
}
/**
* @param value ; 数据
* @param context : 承接上下游
*/
override def invoke(
value: String, context: SinkFunction.Context[_]): Unit = {
println(value)
}
}
2 连接写入至 mysql
package sink
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
object Demo2MySql {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val stuDS = env.readTextFile("Flink/data/students.txt")
stuDS.addSink(new MysqlSink)
env.execute()
}
}
class MysqlSink extends RichSinkFunction[String] {
var conn: Connection = _
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
val split = value.split(",")
val id = split(0)
val name = split(1)
val age = split(2).toInt
val gender = split(3)
val clazz = split(4)
val ps: PreparedStatement = conn.prepareStatement(
"insert into table students(id,name,age,gender,clazz) values(?,?,?,?,?)")
ps.setString(1,id)
ps.setString(2,name)
ps.setInt(3,age)
ps.setString(4,gender)
ps.setString(5,clazz)
// ps.addBatch()
ps.execute()
}
override def open(parameters: Configuration): Unit = {
println("创建链接")
Class.forName("com.mysql.jdbc.Driver")
conn = DriverManager.getConnection(
"jdbc:mysql://master:3306/tour?useUnicode=true&characterEncoding=utf-8"
, "root", "123456")
}
override def close(): Unit = {
println("关闭链接")
conn.close()
}
}
3 写至本地文件
package sink
import java.util.concurrent.TimeUnit
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala._
object Demo4StreamingFileSink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val linesDS = env.socketTextStream("master", 8888)
val sink = StreamingFileSink
.forRowFormat(new Path("Flink/data/streamingsink")
, new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
//滚动策略
DefaultRollingPolicy.builder()
//java.util.concurrent.TimeUnit
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toSeconds(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build()
)
.build()
linesDS.addSink(sink)
env.execute()
}
}
二、Flink 集群搭建
1、standallone cluster
1 需要配置 JAVA_HOME
vim /etc/profile
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
2 上传解压
tar -zxvf flink-1.11.0-bin-scala_2.11.tgz
3 修改配置文件
vim conf/flink-conf.yaml
主节点ip地址
jobmanager.rpc.address: master
vim conf/workers
增加从节点
node1 node2
vim conf/masters
改成主节点ip
4 同步到节点
scp -r flink-1.11.0/ node1:`pwd`
5 启动集群
start-cluster.sh
6 访问 web 界面
http://master:8081
2、提交任务
1 web 页面提交
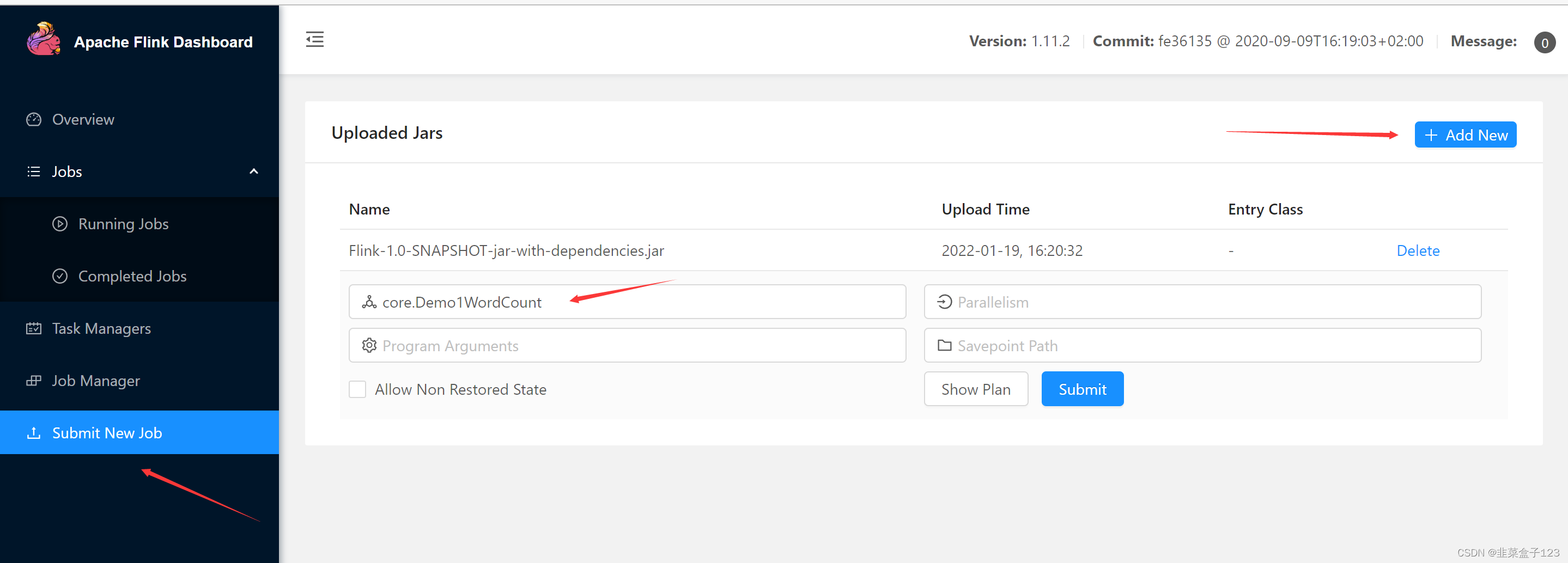
Parallelism 是分配的资源数,standalone 模式下,只会有一个资源
因此在这里提交的任务需要将核数设置为 1
可以在代码中添加如下语句,或不写默认,页面默认设置为 1
env.setParallelism(1)
2 flink 命令提交任务
flink run -c core.Demo1WordCount Flink-1.0-SNAPSHOT-jar-with-dependencies.jar
可以在页面中看到提交出来的任务
3 rpc方式提交任务
可以在代码中远程连接到 Flink 集群中,记得先打包再运行任务
此处的端口号固定为 8081,和后面的 yarn 模式有所区别
package core
import org.apache.flink.streaming.api.scala._
object Demo2RpcSubmit {
def main(args: Array[String]): Unit = {
/**
* createRemoteEnvironment: 远程提交任务
*
* 将代码写好之后打包,再运行代码
*/
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.createRemoteEnvironment(
"master", 8081
, "D:\\soft\\IDEA\\fghStudyData\\Flink\\target\\Flink-1.0-SNAPSHOT-jar-with-dependencies.jar"
)
val linesDS = env.socketTextStream("master", 8888)
val wordDS = linesDS.map((_, 1))
.keyBy(_._1)
.reduce((x, y) => (x._1, x._2 + y._2))
wordDS.print()
env.execute()
}
}
这里可以看到控制台的输出界面和日志
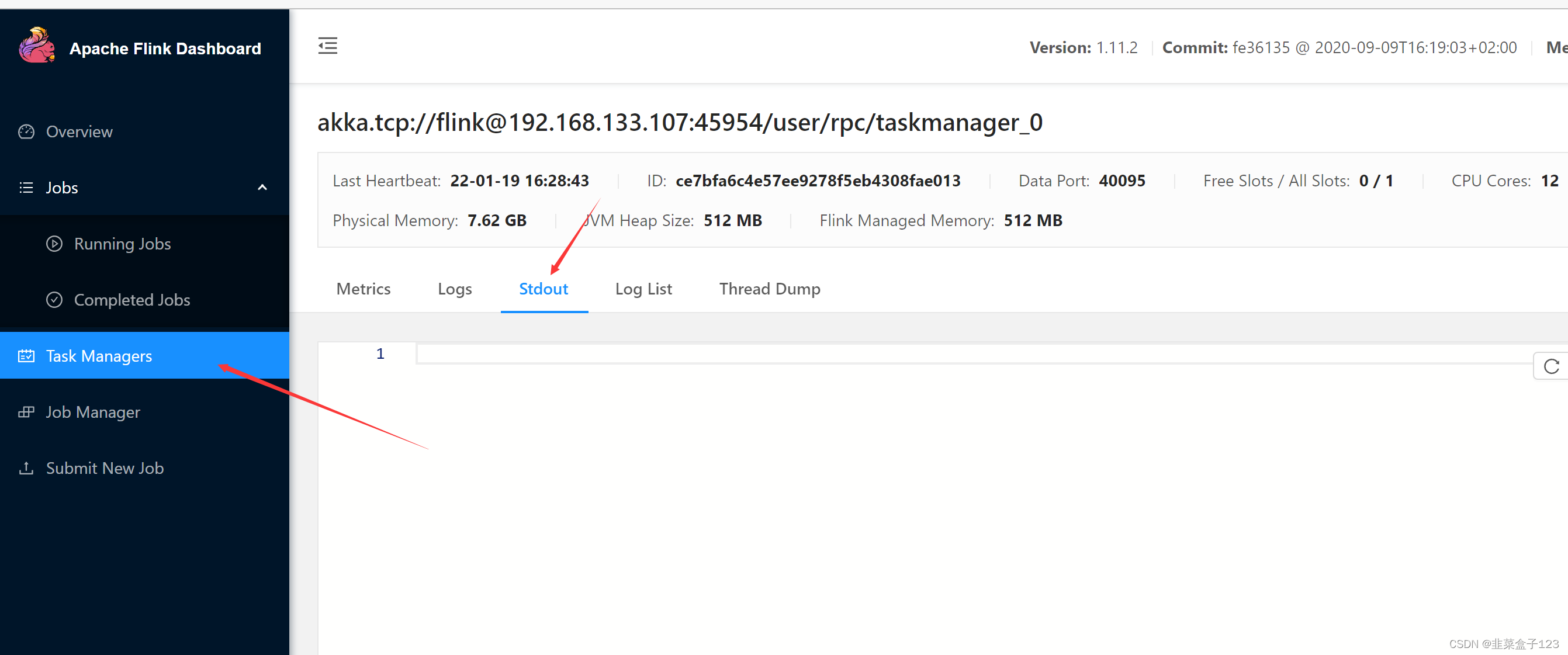
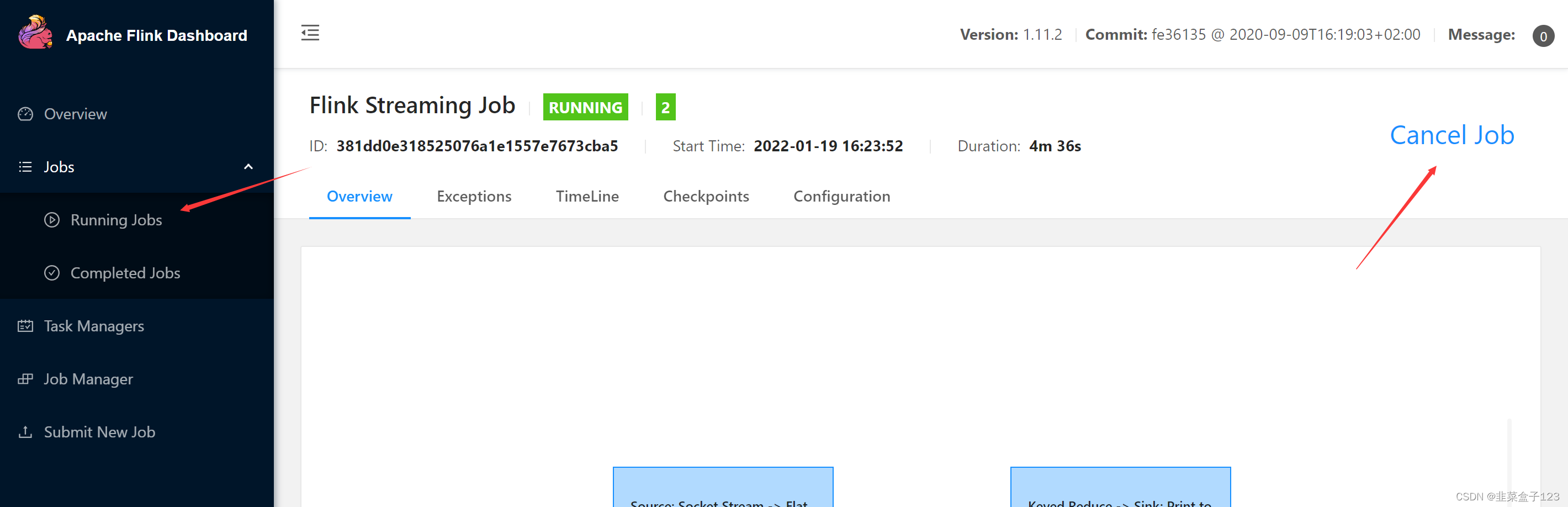
运行完在此处取消任务
3、flink on yarn
1 配置HADOOP_CONF_DIR
vim /etc/profile
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.7.6/etc/hadoop/
2 将hadoop依赖jar上传到 flink / lib 目录
可以在官网的这里下载
4 yarn 集群使用
分为两种方式:yarn-session 和直接提交任务到 yarn
和 Spark 一样,是粗粒度资源申请
1 yarn-session
在yarn里面启动一个flink集群 jobManager(ApplicationMaster)
所有任务会公用一个 jobManager
优势是由于少申请一部分资源,加载会稍快
缺点是多个任务依赖同一个 jobManager,如果它坏了就全废了
先启动 hadoop,再启动 session
start-all.sh
yarn-session.sh -jm 1024m -tm 1096m
关于提交任务,和独立集群模式一样有三种方式
- web 界面提交任务
- Flink 指令提交任务
- RPC 方式提交任务
注意,此时 yarn 会提供依个随机生成的端口号,不再是 8081
2 直接提交到 yarn
会为每一个任务分配不同的 jobManager 和 taskManager
缺点是启动较慢
优点是关联变弱,一般生产环境中会使用这方式
只能通过指令来提交任务
flink run -m yarn-cluster -yjm 1024m -ytm 1096m -c core.Demo1WordCount Flink-1.0-SNAPSHOT-jar-with-dependencies.jar
取消任务也需要手动删除 yarn 任务,需要先拿到编号
yarn application -kill application_1599820991153_0005
三、运行流程
1、standalone
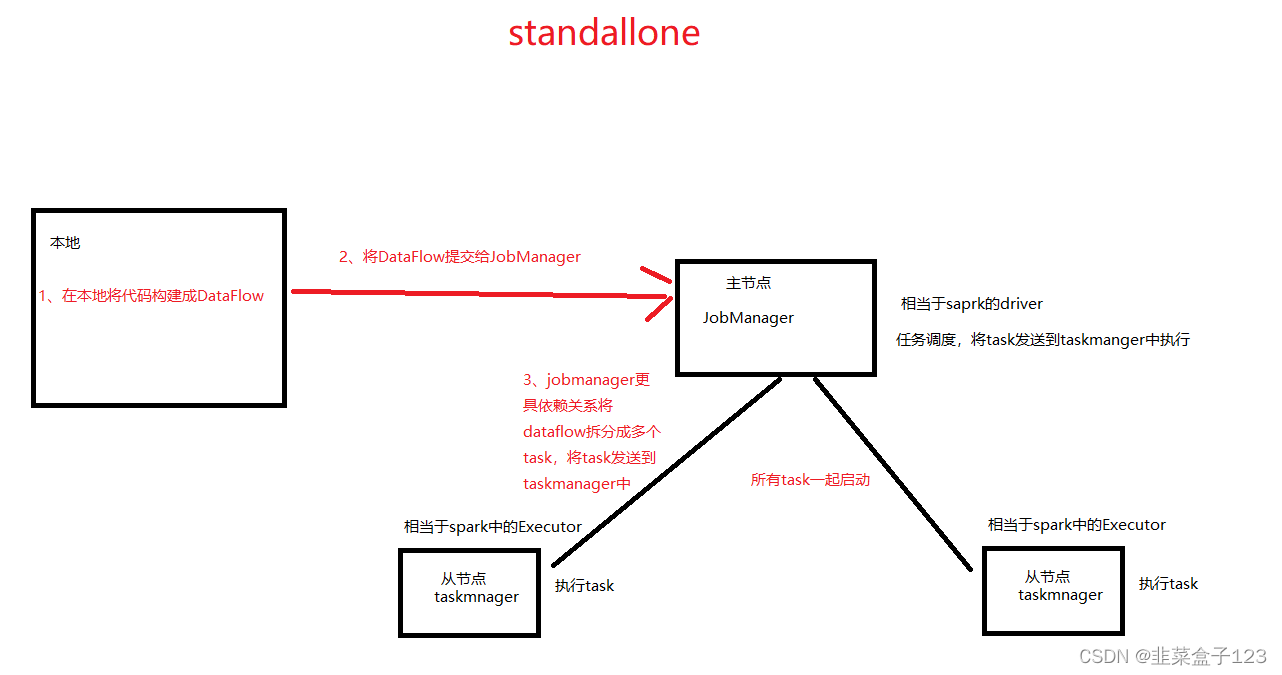
1、在本地将代码就构建成 DataFlow(流程图)
2、提交给 JobManager(相当于 Spark 中的 Driver,负责任务调度)
3、JobManager 根据依赖关系将 DataFlow 拆分为多个 task,发送至 TaskManager 上执行
4、TaskManager(相当于 Spark 中的 Executor)将所有的 Task 一起启动,开始执行
2、yarn-session
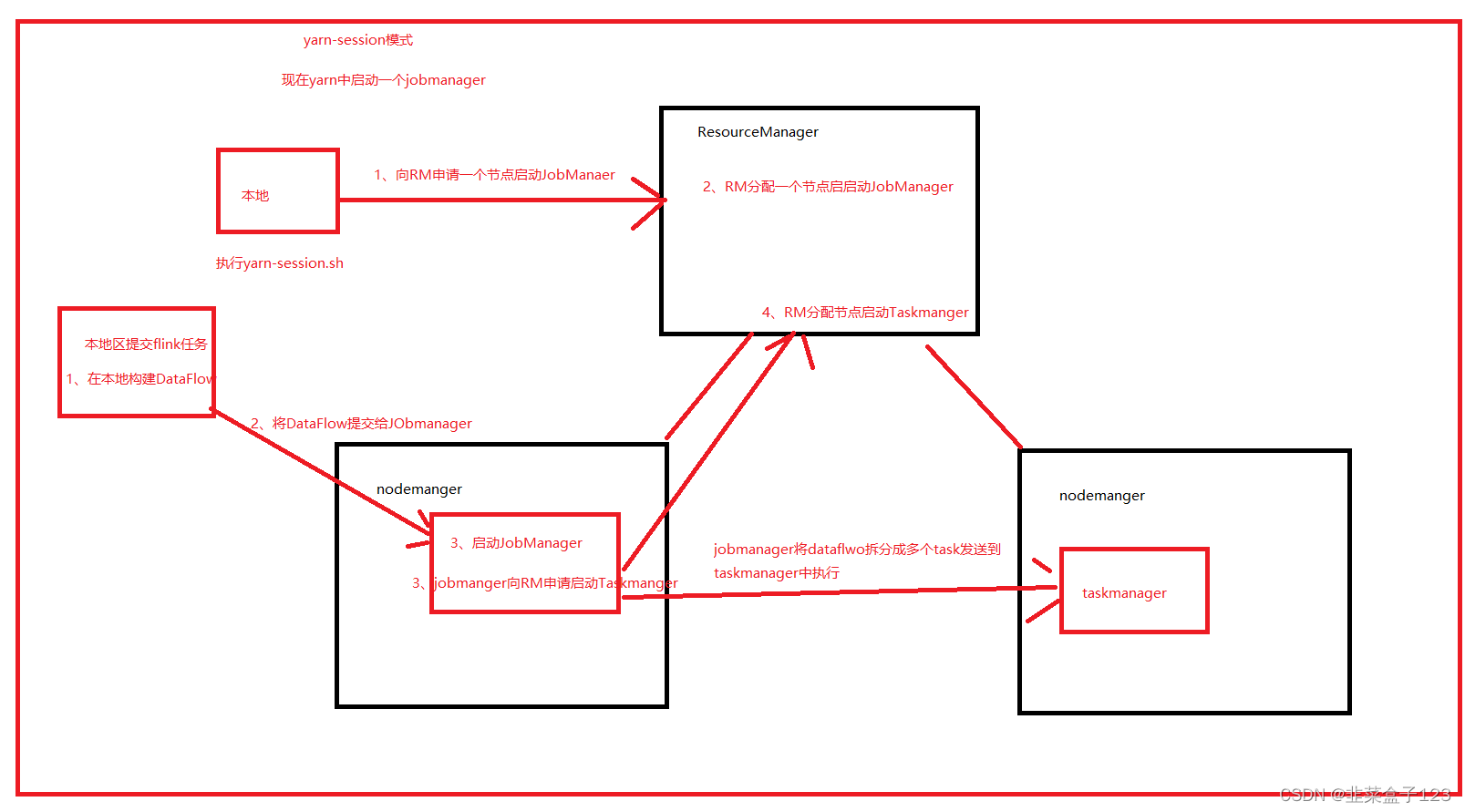
1、向 RM 申请节点启动 JobManager
2、JobManager 反过来向 RM 申请资源启动在随机节点启动 TaskManager
之后任务处理的流程和 StandAlone 一致,后提交的任务只需要从申请 TaskManager 开始=
yarn-session 和直接提交的区别
1、yarn-session 模式所有的任务共享同一个 JobManager 任务启动快,任务之间有影响
2、直接提交模式,每个 Job 单独启动一个 JobManager,任务之间没有影响
四、共享资源
由于 Flink 中,每个任务的 Task 的是一起执行的,所以 shuffle 前后的 Task 都会需要资源
每个 Task 都会占用一个槽位(Slot),这样每个 Job 都会占用非常多的资源
Flink 会将可以并行计算的 Task 放到一个 Slot 中,称为共享资源
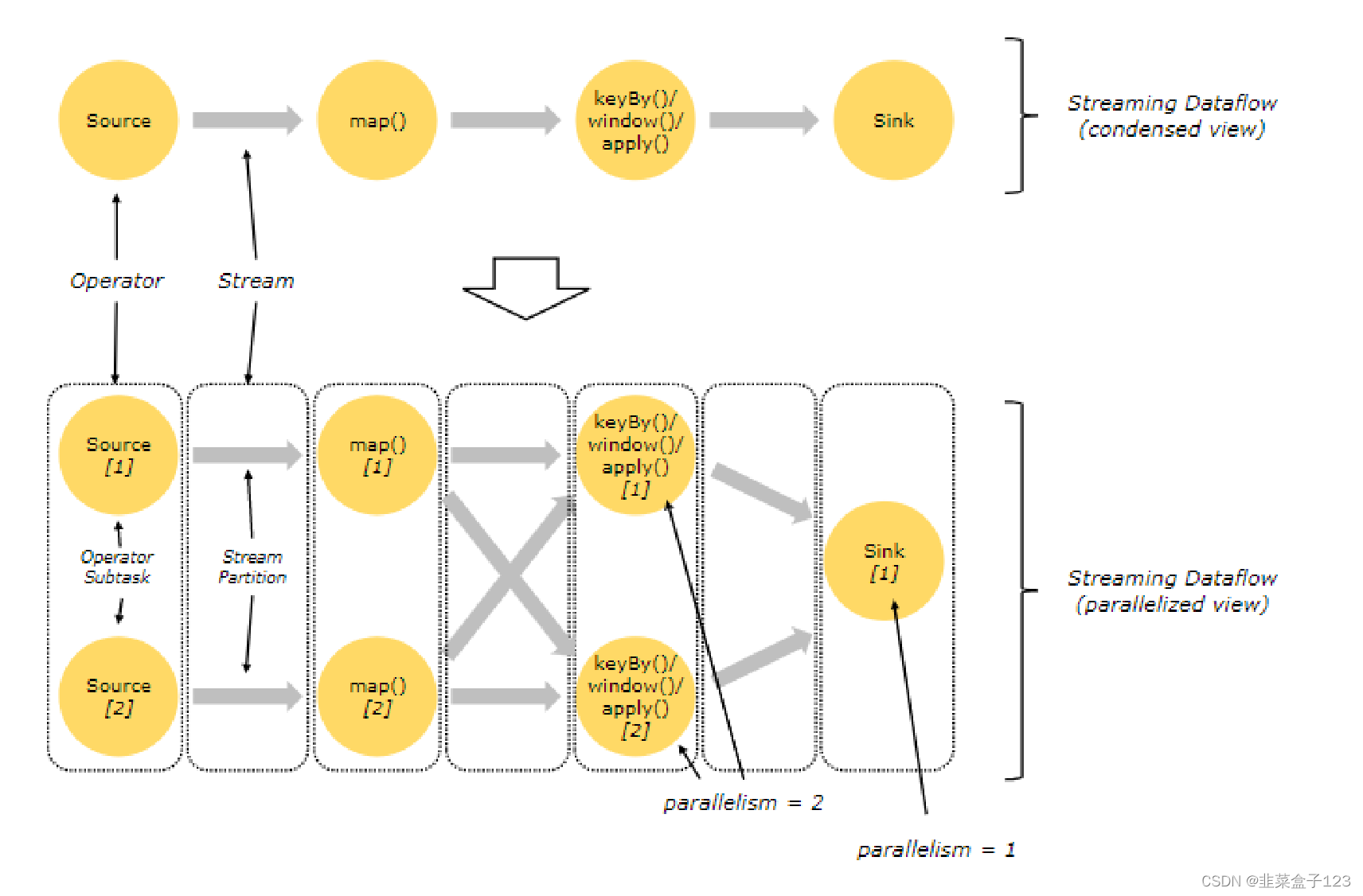
并行后,会需要五个 Task 来启动任务,因此会占用 5 个 Slot(核)
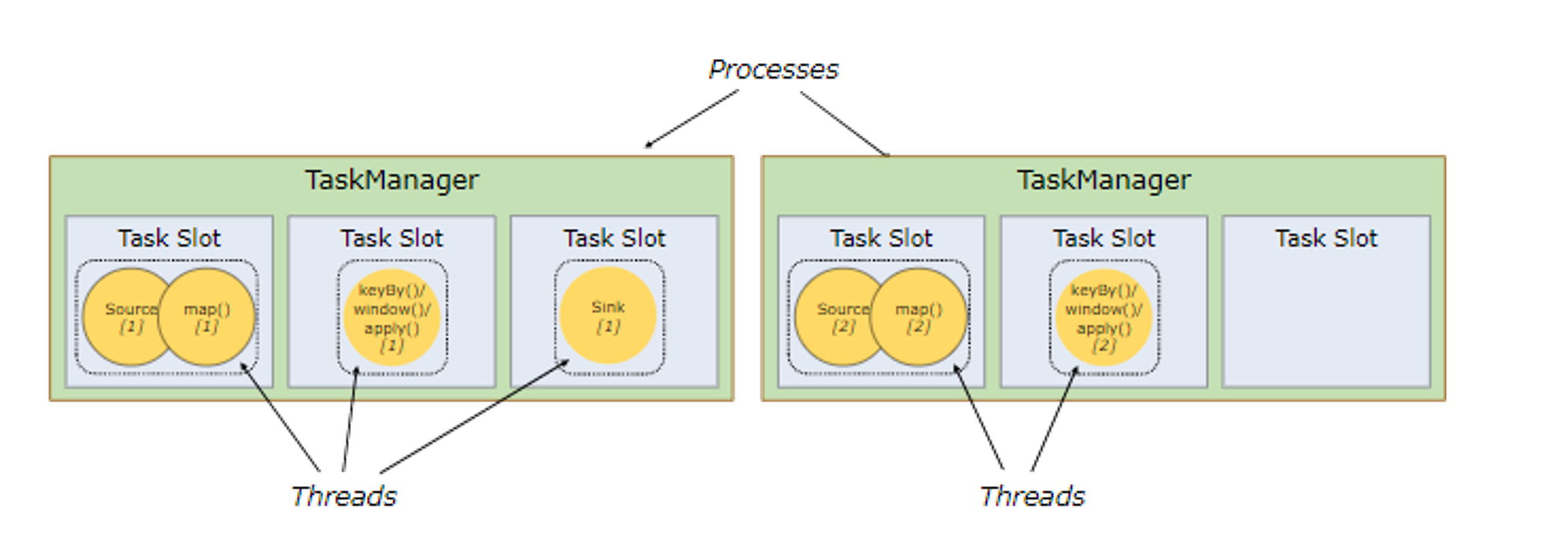
共享资源后,会将并行的 Task 放在一个 Slot 中,原本的任务会只需要 2 个 Slot
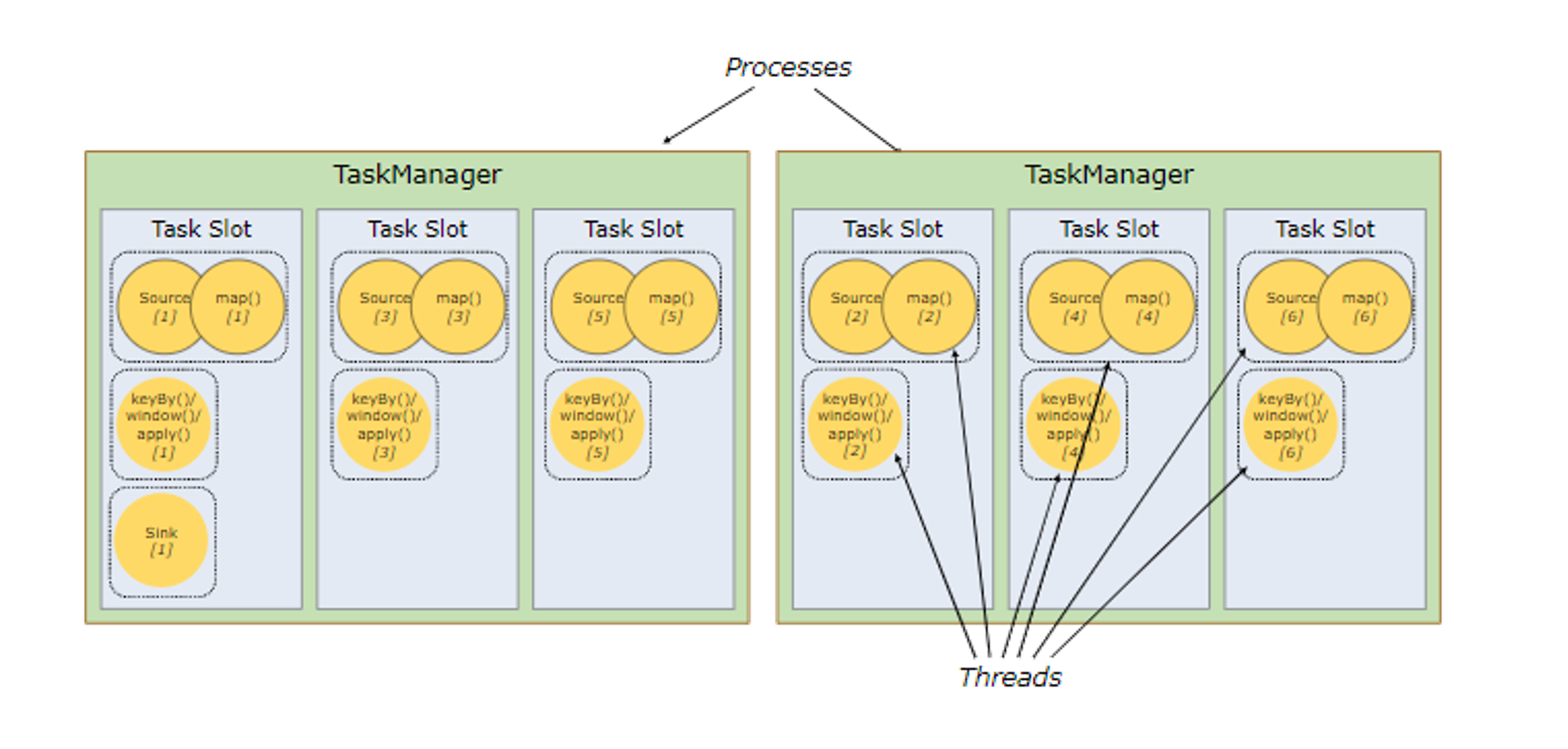
总结就是,一个并行度占用一个资源(Slot),这里的并行度包括 shuffle 的
而 Spark 中的 Partition 是一个 task 占用一个
五、事件时间
Flink 中,有三种时间概念
1.Event Time:
事件(数据)时间,是数据中自带的时间,;例如自带的时间戳字段等,
本质上是脱离当前现实时间的,可以反映数据实际发生的时间
2.Ingestion Time:
接收时间,数据实际到达 Source 的时间,不怎么用得到
3.Processing Time:
处理时间,数据被算子所处理的时间,对应现实时间
事件时间会与处理时间分开处理,因为事件时间是真正发生的时间,
而处理时间可能会有延迟,和乱序,导致结果的偏差,
因此,事件时间用于处理一些对时间比较敏感的数据
为了处理事件时间,Flink 引入了 WaterMark(水位线)的概念
1、一点点解释
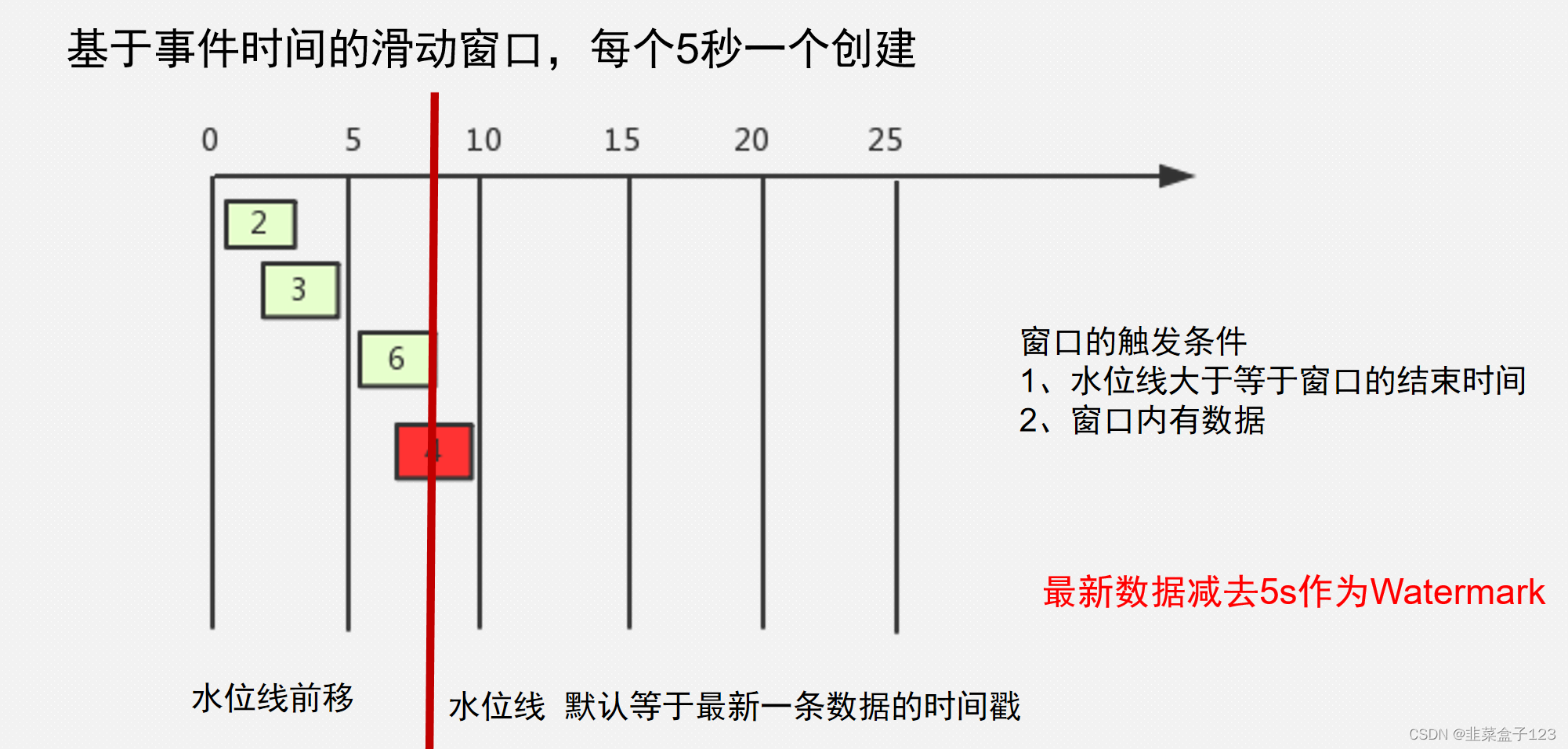
特点
会根据事件时间构建新的时间线,根据窗口大小将时间划分为多个区域,此处为 5,
最新一条数据的事件时间为当前水位线,当水位线 “越过” 区域的界限,执行一次算子
此时水位线为 6,其实为 2,区域的界限为 5,因此会处理事件时间为2和3的数据
问题是当处理时间发生混乱,会导致之前的数据被忽略,如此时事件时间为 4 的数据
优化
解决办法是将水位线前移,如前移 5 秒,此时,当水位线到达 5,不会再计算
到达 10 时,才会计算事件时间处于 [0,5) 之间的数据
到达 15 是,才会计算事件时间处于 [5,10) 之间的数据
… …
以此类推
这样可以一定程度的缓解数据被遗漏的问题,但根源上还是可能发生
package core
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object Demo3EventTime {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
/**
* 1、设置时间模式为事件时间
*
*/
//默认是处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val linesDS = env.socketTextStream("master", 8888)
val wordDS = linesDS.map(line => {
val split = line.split(",")
(split(0), split(1).toLong)
})
/*
java,1642494546000
java,1642494547000
java,1642494548000
java,1642494550000
java,1642494549000
java,1642494551000
java,1642494552000
java,1642494553000
java,1642494554000
java,1642494555000
java,1642494560000
*/
/**
* 2、指定时间字段, 必须是时间戳毫秒级别
*
*/
// val asDS = wordDS.assignAscendingTimestamps(_._2)
val asDS = wordDS.assignTimestampsAndWatermarks(
//指定时间戳字段和数据最大乱序时间
new BoundedOutOfOrdernessTimestampExtractor[(String, Long)](Time.seconds(5)) {
override def extractTimestamp(element: (String, Long)): Long
= {element._2}
}
)
val countDS = asDS
.map((kv => (kv._1, 1)))
.keyBy(_._1)
// .reduce((x, y) => (x._1, x._2 + y._2))
.timeWindow(Time.seconds(5))
// sum(1) 是对索引为1的字段进行加和
.sum(1)
countDS.print()
env.execute()
}
}

















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









