







在大的项目开发中,对于文件的上传和下载是必不可少的,就比如说用户头像吧,本章节介绍Tornado通过获取表单数据,保存文件和参数,简单的说就是实现文件上传功能。同时通过复杂表单的方式提交,不仅能够上传文件,还能够发送数据,在python中配合seek命令,可以实现更复杂的下载请求,比如,断点续传、分块下载。解决中文名下载报错问题
一、上代码
import tornado.ioloop
import tornado.web
#上传文件 的路由
class UploadHandler(tornado.web.RequestHandler):
# 设置允许跨域
def set_default_headers(self):
self.set_header("Access-Control-Allow-Origin", "*")
self.set_header("Access-Control-Allow-Headers", "Content-Type")
self.set_header("Access-Control-Allow-Methods", "POST,GET,OPTIONS")
def post(self,*args,**kwargs):
try:
# 表单上传 数据形式是multipart/form-data,既可以提交普通键值对,也可以提交(多个)文件键值对
# 表单上传,这个image其实就是我们上传文件的键值对中的键,而其中这个值呢就是文件,在发送端也可以说是文件路径
file_imgs = self.request.files.get('image',None) # 返回的是一个文件列表
devicemodel = self.get_body_argument('devicemodel') # 我们在发送文件的时候可能会发送其他参数
if not file_imgs:
# 判断文件是否为空
self.write({"error":"file none!"})
return
for file_img in file_imgs: #可能同一个上传的文件会有多个文件,所以要用for循环去迭代它
# filename 文件的实际名字,body 文件的数据实体;content_type 文件的类型。 这三个对象属性可以像字典一样支持关键字索引
# 我们定义保存的路径,同样的你自己可以指定,也可以通过参数获取,但是如果当前目录不存在 你需要处理,否则报错
save_to = './{}'.format(file_img['filename'])
# 同名称的文件且同类型文件会覆盖,切记记得区分或者特殊处理比如加上时间戳
# 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
with open(save_to,'wb') as f: #二进制
f.write(file_img['body'])
self.write({"success":"upload success!"})
except Exception as e:
print("upload",e)
self.write({"error":"server error!"})
def main():
# 定义请求的路径和响应的请求类,此类会根据你发出的请求区分get 还是post而给予不同的处理
application = tornado.web.Application([
(r"/upload", UploadHandler),
])
# 绑定端口,单进程启动
application.listen(8000)
tornado.ioloop.IOLoop.instance().start()
if __name__ == "__main__":
main()
二、测试
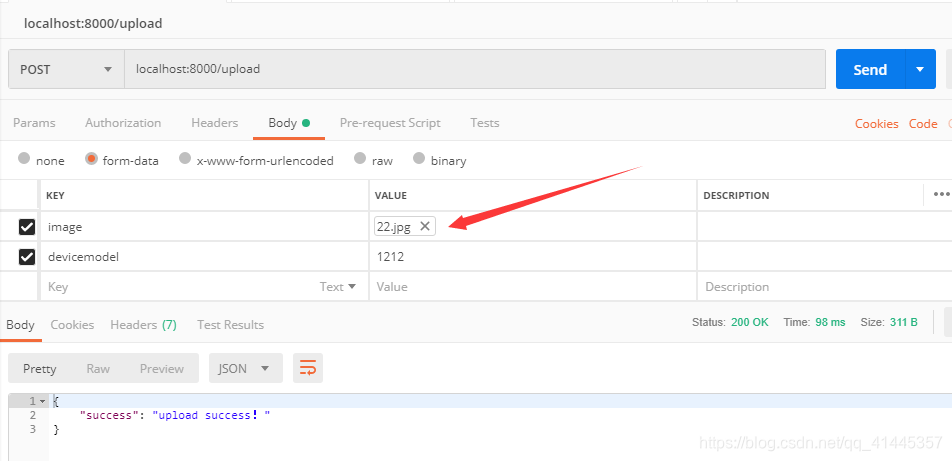

上传成功,我们来看一下postman给的代码
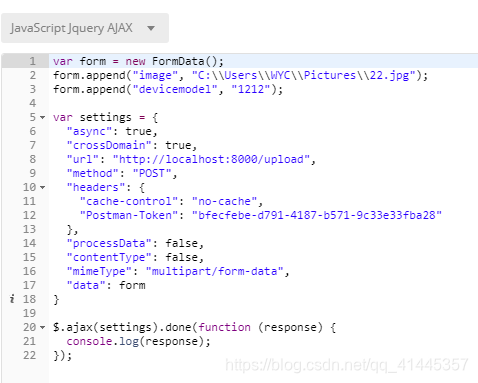
表单提交
三、至于文件下载,其实在上传的时候我们就可以将文件的存放路径给保存下来,写入数据库,留着我们下载使用,但是下载大文件一般推荐使用ftp协议,小的文件就可以用这个http协议,同样是二进制读取文件。
1、上代码
import tornado.ioloop
import tornado.web
# 引入url编码,解决中文文件名下载报错问题
from urllib import parse
class DownloadHandler(tornado.web.RequestHandler):
# 设置允许跨域
def set_default_headers(self):
self.set_header("Access-Control-Allow-Origin", "*")
self.set_header("Access-Control-Allow-Headers", "Content-Type")
self.set_header("Access-Control-Allow-Methods", "POST,GET,OPTIONS")
def get(self):
# 获取参数
# 读取的内存大小,一般会在保存文件的时候记录下来,最好比源文件大
buf_size = 4096
filename=self.get_argument('filename', None)
if not filename:
self.write({"error":"文件名称为空"})
return
# 设置传输的文件类型,有很多例如png/pdf等等 取决于不同场景,这边我用octet-stream
self.set_header ('Content-Type', 'application/octet-stream')
path='./'+filename
with open( path, 'rb') as f:
while True:
data = f.read(buf_size)
if not data:
break
self.write(data)
filename=parse.quote(filename)
# 设置文件保存名,也就是你下载完成显示的名称,我们对文件名进行url编码,因为header对中文是不支持的
# 在浏览器下载的时候,会进行解码的
self.set_header ('Content-Disposition', 'attachment; filename='+filename)
self.finish()
def main():
# 定义请求的路径和响应的请求类,此类会根据你发出的请求区分get 还是post而给予不同的处理
application = tornado.web.Application([
(r"/download", DownloadHandler),
])
# 绑定端口,单进程启动
application.listen(8000)
tornado.ioloop.IOLoop.instance().start()
if __name__ == "__main__":
main()
2、测试,运行dw.py
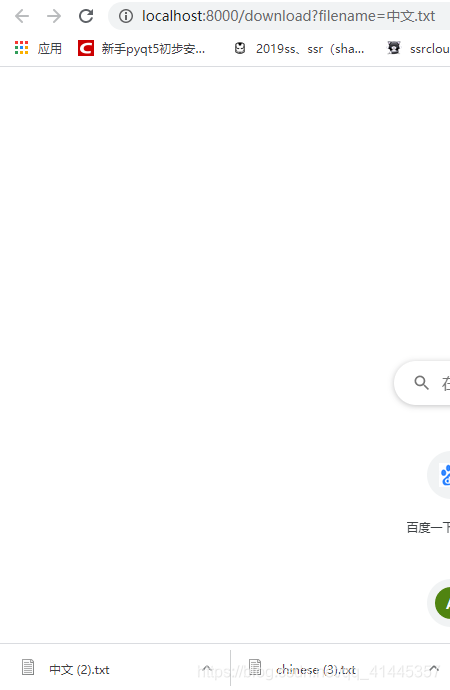
我在浏览器中输入localhost:8000/download?filename=中文.txt,回车就可以下载了


















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











