







这是爬取中国科技部计划申报指南的小程序,灵感来自一个很厉害的学姐,目的帮大家提取关键词,方便写论文申请课题,把握研究动向,然后我们再转换为txt文件,做词频处理。关于文件执行流程,就是这三个文件依次执行。其中百度停用词表下载连接附在最后了。
这是目标网址:http://www.most.gov.cn/mostinfo/xinxifenlei/zjgx/
一、首先是获得pdf文件
"""
版本:python 3.6
作者:物联网菜鸟
时间:2019年8月11
这是一个抓取 2019 年 科技部计划申报指南 pdf文件的程序
当然你也可以改成2020只是因为2020年的项目太少了,你等下半年试试
"""
import requests
import re
import os
import shutil
"""
通过url获取页面信息
参数 url 字符串
返回值 页面内容 字符串类型
"""
def getPage(url):
try:
r=requests.get(url)
r.encoding = 'utf-8'
return r.text
except Exception as e:
print("网络错误!",e)
return ""
"""
分析页面内容,拿到 pdf文件 所在页面的url
参数 页面内容 字符串
返回值 url列表
"""
def getUrl(htmlpage):
url_list = re.findall(r'/fgzc/gfxwj/gfxwj2019.*?htm', htmlpage)
#正则表达式,提取url地址
new_url_list=[]
for i in url_list:
new_url_list.append("http://www.most.gov.cn/mostinfo/xinxifenlei"+i)
#补全地址
return new_url_list
"""
得到pdf 文件所在页面的地址
参数 页面内容 字符串
返回值 URL列表
"""
def getPdfPageUrl(htmlpage):
#得到包含pdf连接的页面url
url_list=re.findall(r'<A href="./(.*?pdf)',htmlpage)
#提取url地址
name_list=re.findall(r'.pdf"*>[:|.0|1|2|3|4|5|6|7|8|9| ]*(.*?)</A>',htmlpage)
#提取文档的名称
new_url_list=[]
for i in url_list:
new_url_list.append("http://www.most.gov.cn/mostinfo/xinxifenlei/fgzc/gfxwj/gfxwj2019/"+i[2:8]+"/"+i)
#补全地址
return new_url_list,name_list
"""
得到包含pdf 文件的页面的 url
返回值 url 列表
"""
def getPdfUrl():
base_url="http://www.most.gov.cn/mostinfo/xinxifenlei/zjgx/"
# 我们只爬取20*5页的内容,大概在2019年9月之前的文件,也就是2019年上半年,为了大家看的明白我就不用循环了
target_url_list = ['index_5.htm','index_6.htm','index_7.htm','index_8.htm','index_9.htm']
new_url_list=[]
new_name_list=[]
for url in target_url_list:
htmlpage=getPage(base_url+url)
url_list=getUrl(htmlpage)
for i in url_list:
htmlpage=getPage(i)
temp_url,temp_name=getPdfPageUrl(htmlpage)
if temp_url:
for i in temp_url:
new_url_list.append(i)
if temp_name:
for j in temp_name:
new_name_list.append(j)
url_dir=dict(zip(new_url_list,new_name_list))
#形成文件名称和文件地址的键值对
new_url_dir={}
for key,value in url_dir.items():
if value[-2:]=="指南":
#剔除不是指南的文件
new_url_dir[value.split("/")[0]]=key
return new_url_dir
"""
得到pdf 文件
"""
def getPdfFile(name,url):
try:
with open('./pdf/'+name+'.pdf','wb') as f:
f.write(requests.get(url).content)
print ("Sucessful to download" + " " + name)
except Exception as e:
print("下载pdf失败"+ name,e)
"""
清楚文件夹及其pdf文件
"""
def clearPath():
if os.path.exists('pdf'):
shutil.rmtree('pdf')
print("目录删除成功!")
os.mkdir('pdf')
print("目录创建成功!")
else:
os.mkdir('pdf')
print("目录创建成功!")
def main():
clearPath()
url_dir=getPdfUrl()
for key,value in url_dir.items():
getPdfFile(key,value)
if __name__=='__main__':
main()
这是执行结果,汇总自动创建和删除已有目录
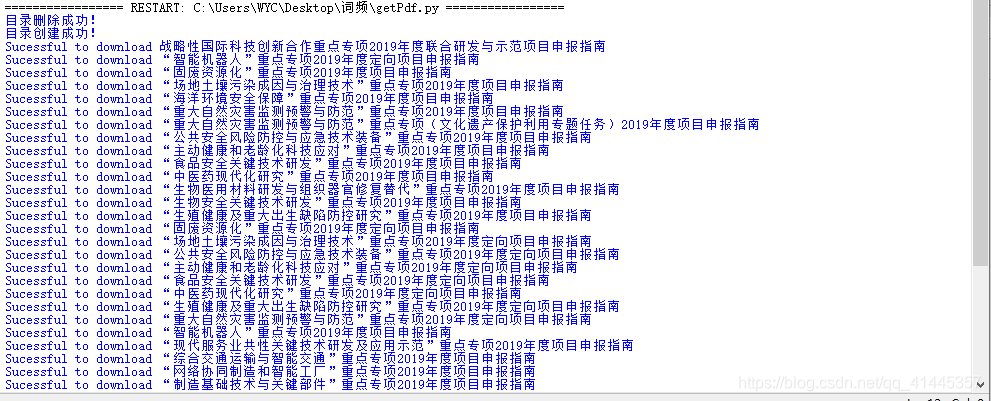
二、pdf文件转换为txt文件,用于词频分析
"""
版本 python 3.6
作者 物联网菜鸟
时间 2019 年 8 月 11
这是一个将pdf文件内容提取放在txt的程序
"""
import os
import re
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTTextBoxHorizontal
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed, PDFResourceManager, PDFPageInterpreter
"""
pdf文件内容提取
参数 paf 路径
"""
def pdfParse(path):
#pdf文字提取
try:
with open(path, 'rb') as f:# 用文件对象来创建一个pdf文档分析器
praser = PDFParser(f)# 创建一个PDF文档
doc = PDFDocument()# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
#每页文字内容
results = []
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,
for x in layout:
if isinstance(x, LTTextBoxHorizontal):
with open(r"2019国家科技计划申报.txt","a",encoding="utf-8") as f:
results=x.get_text()
results=re.sub("— \d* —","",results)#去除页码
results=re.sub("\n"," ",results)#去除回车
f.write(results)
print(path+"转换完成!")
except Exception as e:
print(path+"转换失败!",e)
def main():
if os.path.exists("./pdf"):
pass
else:
print("你还没有生成pdf文件")
return
pdf_list=os.listdir('./pdf')
if os.path.exists(r"2019国家科技计划申报.txt"):
os.remove(r"2019国家科技计划申报.txt")
print("删除历史文件成功!")
for i in pdf_list:
pdfParse('./pdf/'+i)
if __name__=="__main__":
main()

所有文件转换完成会生成一个txt文本

三、下面我们将查看词频
"""
版本 python 3.6
作者 物联网菜鸟
时间 2019年 8 月 11
这是一个词频小程序,首先你应该得到pdf文件,执行getPdf.py
其次执行pdfChangeTxt.py 将pdf文件内容集中到一个txt文件中,最后执行这个文件
"""
import os
from wordcloud import WordCloud
import jieba
import nltk
"""
从词频 得到词云图片 参数是 nltk.FreqDist()对象,不是txt文件哦
"""
def CiYunShow_fq(fq):
wordcloud = WordCloud(width=1200,height=600,font_path=r'C:\Windows\fonts\simhei.ttf',background_color="white",max_font_size=100).generate_from_frequencies(fq)
image=wordcloud.to_image()
image.show()
"""
从词频 得到词云图片 参数是字符串
"""
def CiYunShow_txt(txt):
wordcloud = WordCloud(width=1200,height=600,font_path=r'C:\Windows\fonts\simhei.ttf',background_color="white",max_font_size=100).generate(txt)
image=wordcloud.to_image()
image.show()
"""
得到经过过滤的词频表
"""
def getCiPin():
with open(r'2019国家科技计划申报.txt',"r",encoding="utf-8") as f:
txt=f.read()
words=jieba.lcut(txt,cut_all=False,HMM=True)
#生成词频表 采用 精确模式
with open(r"百度停用词列表.txt","r",encoding="utf-8") as f:
stoplist=[x.strip() for x in f.readlines()]
#将百度停用表的内容做成列表
stoplist.append(" ")
#向停用表增加空字符串
words_filtered=[x for x in words if x not in stoplist]#将停用词汇剔除出去
return words_filtered
"""
现在你可以为所欲为了
看完main 函数 你应该知道怎么用词云了吧,通过 trigrams=nltk.ngrams(words_filtered,4)) 得到相关的词组
4可以是其他数值,表示几个相关的词组
通过fd_trigrams= nltk.FreqDist(trigrams) 得到词频表,就是字典呗
fd_trigrams.most_common(5000)得到 词频就是出现的次数前5000的词语,
5000也可以改为其他数值
"""
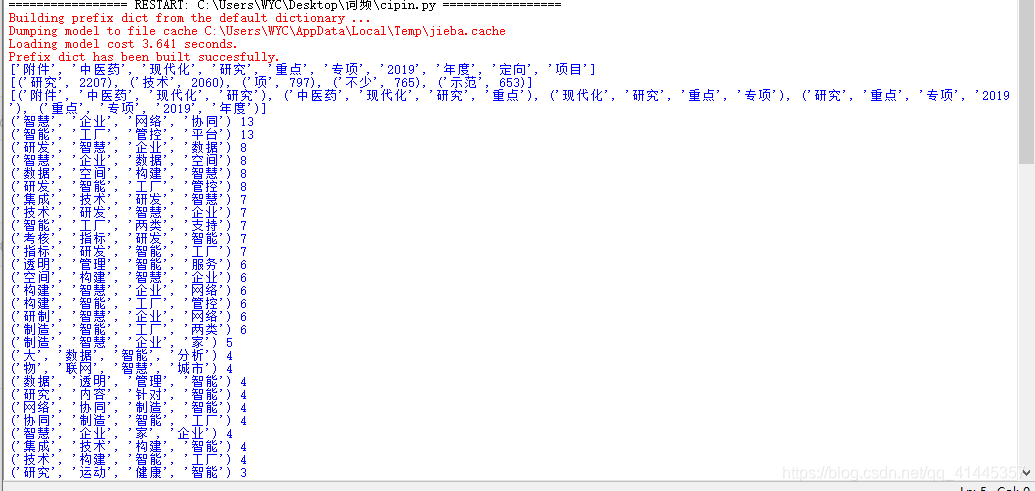
def main():
words_filtered=getCiPin()
# 打印10个词语看看
print(words_filtered[:10])
fq=nltk.FreqDist(words_filtered)
# 出现次数最多的前五个词汇
print(fq.most_common(5))
# 你将得到有关联的四个词组成的元祖
trigrams=list(nltk.ngrams(words_filtered,4))
# 我们输出5个看看
print(trigrams[:5])
# 提取含有 智慧 或者 智能词语的 组合
fd_trigrams=nltk.FreqDist(trigrams)
for x,y in fd_trigrams.most_common(5000):
if "智慧" in x or "智能" in x:
print(x,y)
# 你会得到一个词云图片
CiYunShow_fq(fq)
if __name__=="__main__":
main()
对应的输出结果:

有了数据之后,大家可以尽情的用各种姿势取解锁信息。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











