




前言
紧接上文,这一章将记录RocketMQ的一些核心知识点,也是面试上经常被问及的地方,是非常重要的。
当然了,这里全是理论知识,会比较枯燥,下一张会记录RocketMQ的应用,就会好很多了,不过要有相应的知识支撑,才能更好的去使用rocketMQ。
一、RocketMQ工作原理
1、消息的生产
1.1 消息的生产过程

1.2 Queue选择算法

2、消息的存储
2.1 store目录结构
RocketMQ是将消息存储在~/store目录下,该目录下有7个文件夹,分别如下:

- abort:broker启动后,自动创建,正常关闭时,自动消失,非正常关闭不会消失。
- checkpoint:其中存储着commitlog、comsumequeue、index文件的最后刷盘时间戳
- commitlog:存放着commitlog文件,或者说mappedFile文件,消息就是存放在commitlog中
- config:存放着broker运行期间的一些配置数据
- consumequeue:存放着consumequeue文件、队列就存放在这个目录下
- index:存放着消息索引文件indexFile
- lock:运行期间使用到的全局资源锁
2.2 commitlog
commitlog目录中存放着很多的mappedFile文件,当前Broker中的所有消息都是罗盘到这些mappedFile文件中的,每个mappedFile文件大小为1G,文件名由20位十进制数构成,表示当前文件的第一条消息的起始位移偏移量。
mappedFile文件是顺序存取的,访问效率高。
一个mappedFile文件中第m+1个消息单元的commitlog offset偏移量为L(m+1)=L(m)+MsgLen(m) (m>=0)
消息单元:每一条消息单元有20多个消息相关属性。
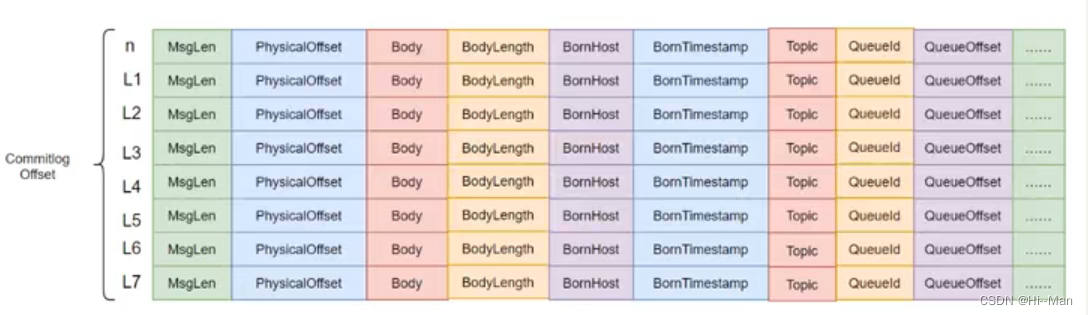
2.3 consumequeue

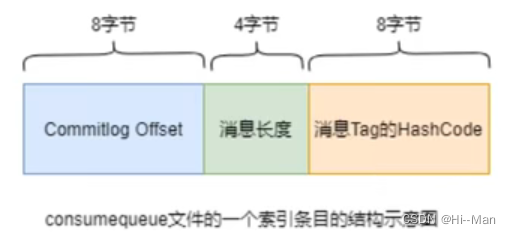
每个consumequeue包含30w个索引条目,每个条目20个字节,包含三个重要部分:commitlog offset、消息长度、消息tag的hashcode。
2.4 对文件的读写
1)消息写入

2)消息拉取

消息offset = 消费offset + 1
queueoffset = 消息offset * 20
3、IndexFile

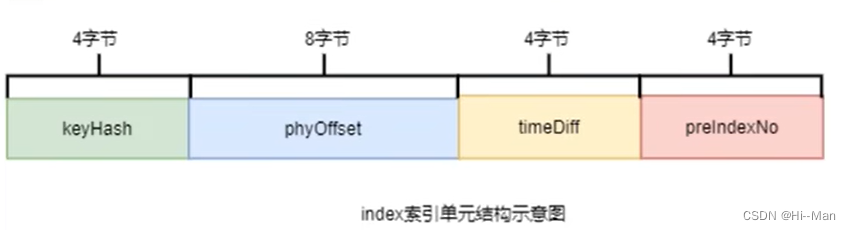
3.1 索引条目结构
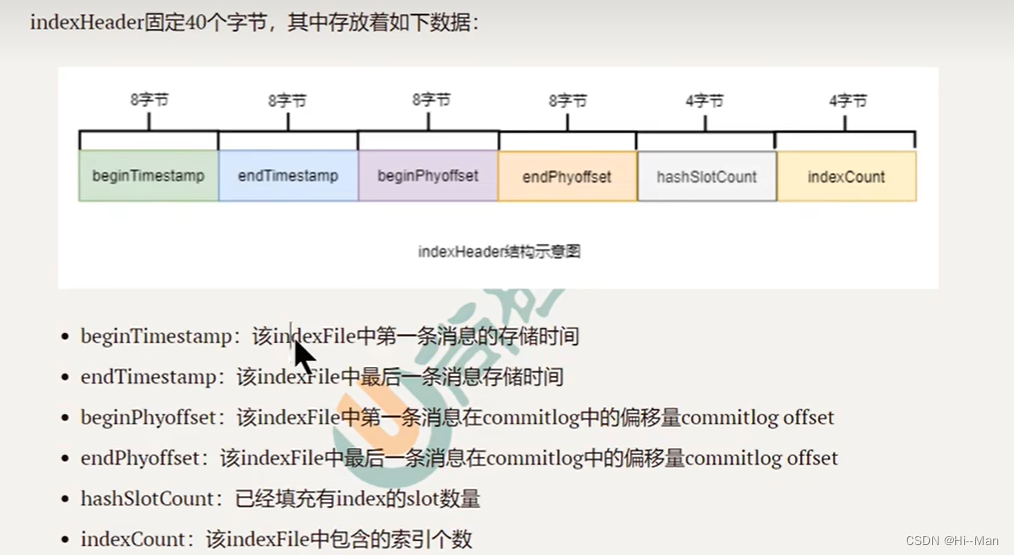
每个broker包含一组IndexFile,每个indexFile已时间戳命名(当前indexFile被创建的时间戳),每个indexFile包含三个部分:indexHeader、slots槽、indexes索引数据。每个indexFile包含500w个slot槽,每个slot槽也可能挂载很多的index索引单元。
slots:key的hash值 % 500w 的结果就是slot槽位
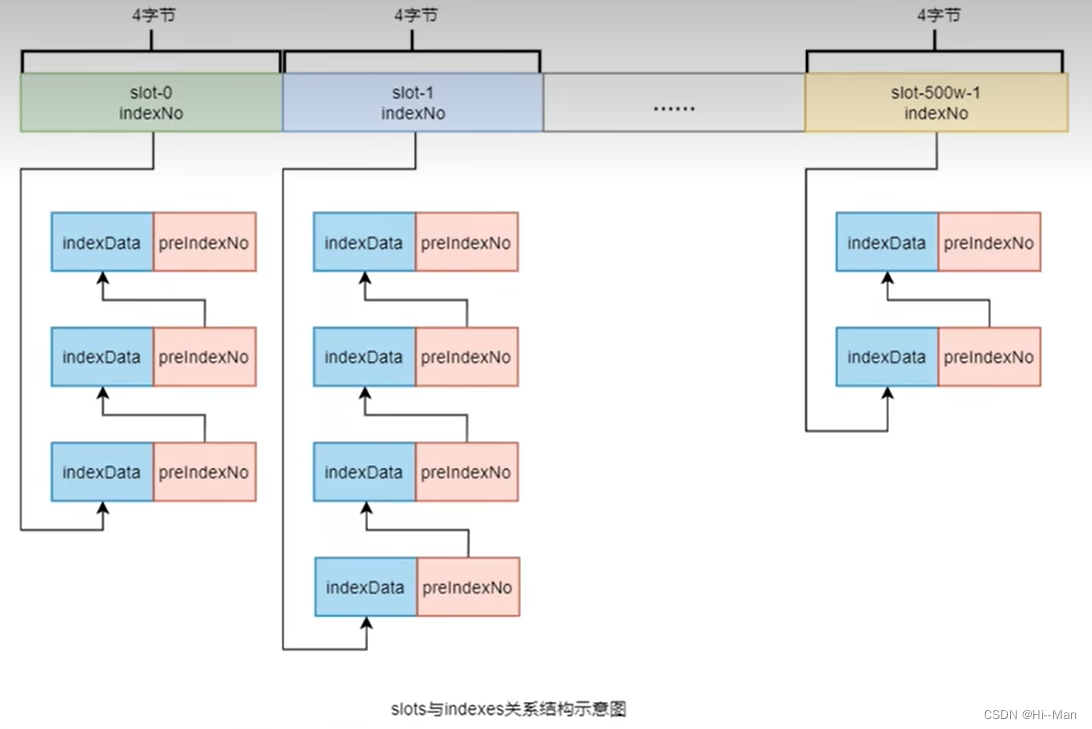
索引单元:
3.2 IndexFile的创建条件
- 当第一个带key的消息进来,系统发现没有创建IndexFile时创建第一个IndexFile。
- 当IndexFile的挂载indexes等于2000w时,创建新的。
由此可以推断出一个indexFile文件的最大大小为:(40 + 500w * 4 + 2000w * 20)字节
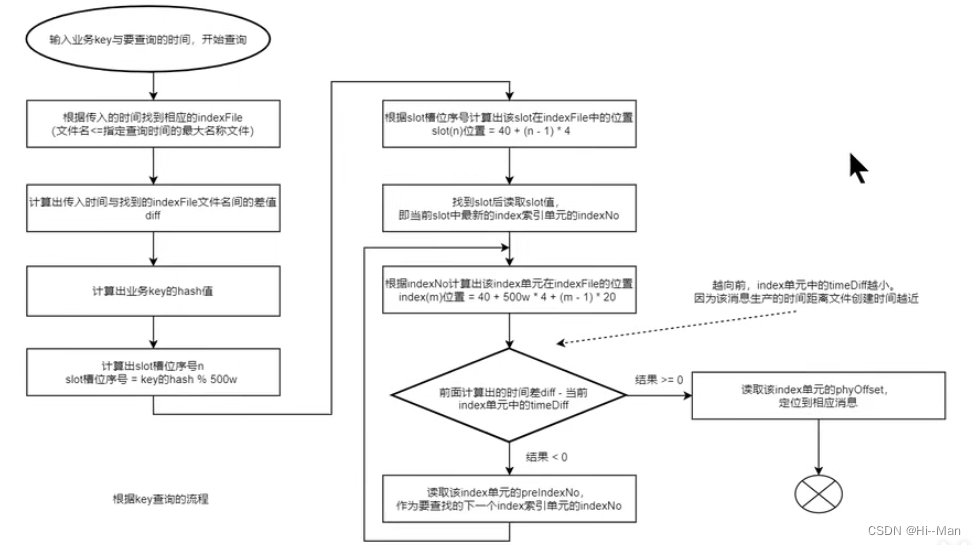
3.3 查询流程
查询流程会相对比较复杂一些。在此之前,需要知道几个公式,如下。
计算指定消息key的slot槽位序号:
slot槽位序号 = key的hash值 % 500w计算槽位序号为n的slot在indexFile中的起始位置:
slot(n)位置 = 40 + (n - 1) * 4计算indexNo为m的index在indexFile中的位置:
index(m)位置 = 40 + 500w * 4 + (m-1) * 20
查询流程:
4、消息的消费
消费者从broker中获取消息的方式有两种:pull拉取方式和push推送方式。
消费者组对于消息消费的方式也有两种:集群消费Clustering和广播消费Broadcasting。
4.1 拉取消费
consumer主动从broker中拉取消息,主动权在consumer,一旦获取到批量消息,则会进行消费。
不过,该方式的实时性比较差,即broker中有了新的消息时,consumer并不能及时发现并消费。
4.2 推送消费
该模式下,broker收到数据后会主动的推送给consumer,该消费模式一般实时性较高。
该模式是典型的发布-订阅模式,即consumer向其关联的queue注册了监听器,一旦发现有新的消息,就会触发回调的执行,回调方法是consumer去queue中拉取消息,这基于consumer和broker的长连接,长连接的维护是需要消耗系统资源的。
推拉消费的对比
pull:需要应用去实现对关联queue的遍历,实时性较差,但便于应用控制消息的拉取
push:封装了对关联queue的便利,实时性强,但会占用较多的系统资源
4.3 广播消费
广播消费模式下,相同的consumer group的每个consumer实例都接受同一个topic的全量消息,即每条消息都会被发送到consumer group里的每个consumer。
4.4 集群消费
集群消费模式下,相同consumer group的每个consumer实例平均分摊同一个topic的消息,即每条消息都会被发送到consumer group里的某一个consumer。
消费进度的保存
广播模式:消费进度保存在consumer端。以为该模式下,consumer group中的每个consumer都会消费所以的消息,但他们的消费进度是不一样的,所以,consumer各自保存各自的消费进度。
集群模式:消费进度保存在broker中,consumer group中的所有consumer共同消费同一个topic中的消息,同一个消息只会被消费一次,消费进度会参与到消息的负载均衡中,故消费进度是需要共享的。
集群消费会产生rebalance,即再平衡。(导致rebalance的原因有两个:消费者订阅的topic的queue发生了变化,或者消费者组中消费者数量发生了变化)
5、订阅关系的一致性
同一个消费者组(即group id相同)下所以consumer实例所订阅的topic与tag及对消息的处理逻辑必须完全一致,否者,消息消费的逻辑就会混乱,甚至导致消息丢失。
5.1 正确订阅关系
多个消费者组订阅了多个topic,并且每个消费者组里的多个消费者实例的订阅关系保持一致。
5.2 错误订阅关系
一个消费者组订阅了多个topic,但是该消费者组里的多个consumer实例的订阅关系并没有保持一致。
6、offset管理
消费进度offset是用来记录每个queue的不同消费者的消费进度。根据消费进度记录器的不同,可以分为两种模式:本地模式(广播模式)和远程模式(集群模式)。
7、消费幂等
当出现消费者对某条消息重复消费的情况时,重复消费的结果与消费一次的结果相同,并且多次消费并未对系统造成任何负面影响,那么这个消费过程就是消费幂等。
消息重复的场景:发送时消息重复、消费时消息重复、rebalance时消息重复
8、消息堆积与消息延迟
消息处理场景中,如果consumer的消费速度更不上producer的发送速度,MQ中未处理的消息就会越来越多,这部分消息就被成为堆积消息,消息被堆积进而造成消息的消费延迟。
以下场景特别要注意消息堆积与延迟问题。
- 业务系统上下游能力不匹配造成的持续堆积,且无法自行恢复。
- 业务系统对消息的消费实时性较高,即使是短暂的堆积造成的消息延迟也无法接受。
8.1 造成原因
consumer将本地缓存的消息提交到消费线程中,使用业务消费逻辑对消息进行处理,处理完毕后获取到一个结果。此时consumer的消费能力完全依赖于消息的消费耗时和消息的并发度。当出现问题导致消息的吞吐量下降致使本地缓存达到上限,就会停止从服务端拉取消息。
8.2 消费耗时
影响消息处理时长的主要因素是代码逻辑,这里面影响时长的主要是两类代码:CPU内部处理型代码和外部I/O操作系代码。
通常情况下。代码中如果没有复杂的递归和循环,内部计算耗时相对于外部I/O操作来说完全可以忽略。
外部I/O操作型代码:
- 读写外部数据库,如对远程MySQL的调用。
- 读写外部缓存系统,如对远程Redis的调用。
- 下游系统调用,如Spring Cloud对下游系统的Http接口调用。
通常消息堆积是由于下游系统出现了服务异常或达到了DBMS容量限制,导致消费耗时增加。
8.3 消息并发度
一般情况下,消费者端的消费并发度由单节点线程数和节点数据共同决定,其值为单节点线程数*节点数量。不过,通常需要优先调整单节点的线程数,若单机硬件达到了上限,则需要通过横向扩展来提高消息并发度。
此处的单节点线程数指单个consumer包含的线程数量,节点数量指consumer group包含的consumer的数量。
对于普通消息、延迟消息及事务消息,并发度计算都是单节点线程数*节点数量,但是对于顺序消息的并发度计算则是Topic的Queue分区数量
8.4 单机线程数
对于一台主机中线程池里线程数量的设置需要谨慎,不能盲目直接调大线程数,过大会导致线程切换的开销,理想环境下,单节点的最大线程数计算模型为:C * (T1 + T2) / T1。
C :CPU内核数
T1 :CPU内部逻辑计算耗时
T2 :外部I/O操作耗时
8.5 如何避免
为避免消息堆积和消息延迟的出现,需要在前期设计阶段对整个业务逻辑进行完善的排查和梳理,其中最重要的就是梳理消息的消费耗时和设置消息消费的并发度。
9、消息的清理
消息被消费后并不会被清理,消息是被顺序存储在commitlog文件中,且消息大小不定长,所以消息的清理是不能以消息为单位进行清理,而是以commitlog文件为单位进行清理,否则会降低清理效率,并且实现的逻辑也会变得很复杂。
commitlog文件存在一个过期时间,默认是72小时。除了手动清理外,在以下场景下也会被自动清理,无论文件中的消息是否已经消费过。
- 文件过期,且达到了清理时间点(默认凌晨4点)后
- 文件过期,且磁盘空间占用率已达到过期清理警戒线(默认75%)后
- 磁盘占用率达到清理警戒线(默认85%)后,开始按照设定的规则清理文件,无论是否过期,默认从最老的文件开始清理。
- 磁盘占用率达到了危险警戒线(默认90%)后,Broker将拒绝消息写入
参考地址
本文是笔者通过自学B站尚硅谷rocketMQ视频做的笔记,视频地址:https://www.bilibili.com/video/BV1cf4y157sz

















 172万+
172万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









