







 本文详细介绍了Elasticsearch中关于数据的操作,包括文档的元数据如_index、_type和_id,如何索引、检索、更新和删除文档,以及处理冲突、使用外部版本控制系统、局部更新和批量操作的方法。重点讲解了bulk API在实现多文档操作中的应用和最佳批量大小的考量。
本文详细介绍了Elasticsearch中关于数据的操作,包括文档的元数据如_index、_type和_id,如何索引、检索、更新和删除文档,以及处理冲突、使用外部版本控制系统、局部更新和批量操作的方法。重点讲解了bulk API在实现多文档操作中的应用和最佳批量大小的考量。
索引名:必须是全部小写,不能以下划线开头,不能包含逗号
类型名:可以是大写或小写,不能包含下划线或逗号
1. 文档元数据
一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:

1.1 _index
索引(index)类似于关系型数据库里的“数据库”——它是我们存储和索引关联数据的地方。
提示:
事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然 而,这只是一些内部细节——我们的程序完全不用关心分片。对于我们的程序而言,文档存储在索引(index)中。剩下 的细节由Elasticsearch关心既可。
1.2 _type
在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。每个对象都属于一个类 (class),这个类定义了属性或与对象关联的数据。 user 类的对象可能包含姓名、性别、年龄和Email地址。
在关系型数据库中,我们经常将相同类的对象存储在一个表里,因为它们有着相同的结构。同理,在Elasticsearch中,我们 使用相同类型(type)的文档表示相同的“事物”,因为他们的数据结构也是相同的。
每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个 索引下,但是类型的映射(mapping)会告诉Elasticsearch不同的文档如何被索引。 我们将会在《映射》章节探讨如何定义和 管理映射,但是现在我们将依赖ELasticsearch去自动处理数据结构。
_type 的名字可以是大写或小写,不能包含下划线或逗号
1.3 _id
id仅仅是一个字符串,它与 _index 和 _type 组合时,就可以在ELasticsearch中唯一标识一个文档。当创建一个文档,你可以 自定义 _id ,也可以让Elasticsearch帮你自动生成。
2. 索引一个文档
1.1 使用自己的id

1.2 让Elasticsearch自动生成
请求结构发生了变化: PUT (在这个URL中存 储文档)方法 变成了 POST (在这个文档下存储文档)方法 。(译者注:原来是把文档存储到某个ID对应的空间,现在是把这个文档 添加到某个 _type 下)。
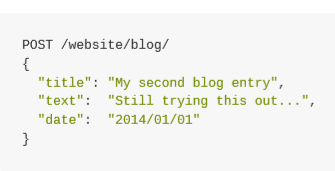
自动生成的ID有22个字符长,URL-safe, Base64-encoded string universally unique identifiers, 或者叫 UUIDs
3. 检索文档
GET /website/blog/123?pretty
在任意的查询字符串中增加 pretty 参数,类似于上面的例子。会让Elasticsearch美化输出(pretty-print)JSON响应以 便更加容易阅读。 _source 字段不会被美化,它的样子与我们输入的一致。
-
检索文档的一部分
GET /website/blog/123?_source=title,text
-
或者你只想得到 _source 字段而不要其他的元数据,你可以这样请求:
GET /website/blog/123/_source
-
检查文档是否存在
使用 HEAD 方法来代替 GET 。 HEAD 请求不会返回响应 体,只有HTTP头curl -i -XHEAD http://localhost:9200/website/blog/123
Elasticsearch将会返回 200 OK 状态如果你的文档存在,如果不存在返回 404 Not Found
3. 更新整个文档

过程如下:
- 从旧文档中检索JSON
- 修改它
- 删除旧文档
- 索引新文档
4. 创建一个新文档
4.1 id自己生成
用post方法,上面说了
4.2 用自定义id
- 第一种方法使用 op_type 查询参数:
PUT /website/blog/123?op_type=create { … }
- 或者第二种方法是在URL后加 /_create 做为端点:
PUT /website/blog/123/_create { … }
如果请求成功的创建了一个新文档,Elasticsearch将返回正常的元数据且响应状态码是 201 Created;另一方面,如果包含相同的 _index 、 _type 和 _id 的文档已经存在,Elasticsearch将返回 409 Conflict 响应状态码
5. 删除文档
DELETE /website/blog/123
6. 处理冲突
每个文档都有一个 _version 号码,这个号码在文档被改变时加一。 Elasticsearch使用这个 _version 保证所有修改都被正确排序。当一个旧版本出现在新版本之后,它会被简单的忽略。
我们利用 _version 的这一优点确保数据不会因为修改冲突而丢失。我们可以指定文档的 version 来做想要的更改。如果那个 版本号不是现在的,我们的请求就失败了。
7. 使用外部版本控制系统
创建一个包含外部版本号 5 的新博客:
PUT /website/blog/2?version=5&version_type=external
8. 文档局部更新

9. 检索多个文档

如果你想检索的文档在同一个 _index 中(甚至在同一个 _type 中),你就可以在URL中定义一个默认的 /_index 或 者 /_index/_type

10. 批量操作
10.1 bulk API允许我们使用单一请求来实现多个文档 的 create 、 index 、 update 或 delete

-
action/metadata这一行定义了文档行为(what action)发生在哪个文档(which document)之上。

在索引、创建、更新或删除时必须指定文档的 _index 、 _type 、 _id 这些元数据(metadata)。
例如删除请求看起来像这样:

-
请求体(request body)由文档的 _source 组成——文档所包含的一些字段以及其值。它被 index 和 create 操作所必须,这是 有道理的:你必须提供文档用来索引。
这些还被 update 操作所必需,而且请求体的组成应该与 update API( doc , upsert , script 等等)一致。删除操作不需要 请求体(request body)。

为了将这些放在一起, bulk 请求表单是这样的:


每个子请求都被独立的执行,所以一个子请求的错误并不影响其它请求。如果任何一个请求失败,顶层的 error 标记将被设 置为 true ,然后错误的细节将在相应的请求中被报告:
10.2 bulk 请求也可以在URL中使用
/_index 或 /_index/_type :

你依旧可以覆盖元数据行的 _index 和 _type ,在没有覆盖时它会使用URL中的值作为默认值:

10.3 批量大小
整个批量请求需要被加载到接受我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一个最佳 的 bulk 请求大小。超过这个大小,性能不再提升而且可能降低。
最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









